Often, GraphQL is presented as a revolutionary new way to think about APIs. Instead of working with rigid server-defined endpoints, you can send queries to get exactly the data you’re looking for in one request. And it’s true — GraphQL can be transformative when adopted in an organization, enabling frontend and backend teams to collaborate more smoothly than ever before. But in practice, both of these technologies involve sending an HTTP request and receiving some result, and GraphQL has many elements of the REST model built in.
So what’s the real deal on a technical level? What are the similarities and differences between these two API paradigms? My claim by the end of the article is going to be that GraphQL and REST are not so different after all, but that GraphQL has some small changes that make a big difference to the developer experience of building and consuming an API.
So let’s jump right in. We’ll identify some properties of an API, and then discuss how GraphQL and REST handle them.
Resources
The core idea of REST is the resource. Each resource is identified by a URL, and you retrieve that resource by sending a GET request to that URL. You will likely get a JSON response, since that’s what most APIs are using these days. So it looks something like:
// GET /books/1
{
"title": "Black Hole Blues",
"author": {
"firstName": "Janna",
"lastName": "Levin"
}
// ... more fields here
}
Note: In the example above, some REST APIs would return “author” as a separate resource.
One thing to note in REST is that the type, or shape, of the resource and the way you fetch that resource are coupled. When you talk about the above in REST documentation, you might refer to it as the “book endpoint”.
GraphQL is quite different in this respect, because in GraphQL these two concepts are completely separate. In your schema, you might have Book and Author types:
type Book {
id: ID
title: String
published: Date
price: String
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
books: [Book]
}
Notice that we have described the kinds of data available, but this description doesn’t tell you anything at all about how those objects might be fetched from a client. That’s one core difference between REST and GraphQL — the description of a particular resource is not coupled to the way you retrieve it.
To be able to actually access a particular book or author, we need to create a Query type in our schema:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
Now, we can send a request similar to the REST request above, but with GraphQL this time:
// GET /graphql?query={ book(id: "1") { title, author { firstName } } }
{
"title": "Black Hole Blues",
"author": {
"firstName": "Janna",
}
}
Nice, now we’re getting somewhere! We can immediately see a few things about GraphQL that are quite different from REST, even though both can be requested via URL, and both can return the same shape of JSON response.
First of all, we can see that the URL with a GraphQL query specifies the resource we’re asking for and also which fields we care about. Also, rather than the server author deciding for us that the related author resource needs to be included, the consumer of the API decides.
But most importantly, the identities of the resources, the concepts of Books and Authors, are not coupled to the way they are fetched. We could potentially retrieve the same Book through many different types of queries, and with different sets of fields.
Conclusion
We’ve identified some similarities and differences already:
- Similar: Both have the idea of a resource, and can specify IDs for those resources.
- Similar: Both can be fetched via an HTTP GET request with a URL.
- Similar: Both can return JSON data in the request.
- Different: In REST, the endpoint you call is the identity of that object. In GraphQL, the identity is separate from how you fetch it.
- Different: In REST, the shape and size of the resource is determined by the server. In GraphQL, the server declares what resources are available, and the client asks for what it needs at the time.
Alright, this was pretty basic if you’ve already used GraphQL and/or REST. If you haven’t used GraphQL before, you can play around with an example similar to the above on Launchpad, a tool for building and exploring GraphQL examples in your browser.
URL Routes vs GraphQL Schema
An API isn’t useful if it isn’t predictable. When you consume an API, you’re usually doing it as part of some program, and that program needs to know what it can call and what it should expect to receive as the result, so that it can operate on that result.
So one of the most important parts of an API is a description of what can be accessed. This is what you’re learning when you read API documentation, and with GraphQL introspection and REST API schema systems like Swagger, this information can be examined programmatically.
In today’s REST APIs, the API is usually described as a list of endpoints:
GET /books/:id
GET /authors/:id
GET /books/:id/comments
POST /books/:id/comments
So you could say that the “shape” of the API is linear — there’s a list of things you can access. When you are retrieving data or saving something, the first question to ask is “which endpoint should I call”?
In GraphQL, as we covered above, you don’t use URLs to identify what is available in the API. Instead, you use a GraphQL schema:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
type Mutation {
addComment(input: AddCommentInput): Comment
}
type Book { ... }
type Author { ... }
type Comment { ... }
input AddCommentInput { ... }
There are a few interesting bits here when compared to the REST routes for a similar data set. First, instead of sending a different HTTP verb to the same URL to differentiate a read vs. a write, GraphQL uses a different initial type — Mutation vs. Query. In a GraphQL document, you can select which type of operation you’re sending with a keyword:
query { ... }
mutation { ... }
For all of the details about the query language, read my earlier post, “The Anatomy of a GraphQL Query”.
You can see that the fields on the Query type match up pretty nicely with the REST routes we had above. That’s because this special type is the entry point into our data, so this is the most equivalent concept in GraphQL to an endpoint URL.
The way you get the initial resource from a GraphQL API is quite similar to REST — you pass a name and some parameters — but the main difference is where you can go from there. In GraphQL, you can send a complex query that fetches additional data according to relationships defined in the schema, but in REST you would have to do that via multiple requests, build the related data into the initial response, or include some special parameters in the URL to modify the response.
Conclusion
In REST, the space of accessible data is described as a linear list of endpoints, and in GraphQL it’s a schema with relationships.
- Similar: The list of endpoints in a REST API is similar to the list of fields on the
Query and Mutation types in a GraphQL API. They are both the entry points into the data.
- Similar: Both have a way to differentiate if an API request is meant to read data or write it.
- Different: In GraphQL, you can traverse from the entry point to related data, following relationships defined in the schema, in a single request. In REST, you have to call multiple endpoints to fetch related resources.
- Different: In GraphQL, there’s no difference between the fields on the
Query type and the fields on any other type, except that only the query type is accessible at the root of a query. For example, you can have arguments in any field in a query. In REST, there’s no first-class concept of a nested URL.
- Different: In REST, you specify a write by changing the HTTP verb from
GET to something else like POST. In GraphQL, you change a keyword in the query.
Because of the first point in the list of similarities above, people often start referring to fields on the Query type as GraphQL “endpoints” or “queries”. While that’s a reasonable comparison, it can lead to a misleading perception that the Query type works significantly differently from other types, which is not the case.
Route Handlers vs. Resolvers
So what happens when you actually call an API? Well, usually it executes some code on the server that received the request. That code might do a computation, load data from a database, call a different API, or really do anything. The whole idea is you don’t need to know from the outside what it’s doing. But both REST and GraphQL have pretty standard ways for implementing the inside of that API, and it’s useful to compare them to get a sense for how these technologies are different.
In this comparison I’ll use JavaScript code because that’s what I’m most familiar with, but of course you can implement both REST and GraphQL APIs in almost any programming language. I’ll also skip any boilerplate required for setting up the server, since it’s not important to the concepts.
Let’s look at a hello world example with express, a popular API library for Node:
app.get('/hello', function (req, res) {
res.send('Hello World!')
})
Here you see we’ve created a /hello endpoint that returns the string 'Hello World!'. From this example we can see the lifecycle of an HTTP request in a REST API server:
- The server receives the request and retrieves the HTTP verb (
GET in this case) and URL path.
- The API library matches up the verb and path to a function registered by the server code.
- The function executes once, and returns a result.
- The API library serializes the result, adds an appropriate response code and headers, and sends it back to the client.
GraphQL works in a very similar way, and for the same hello world example it’s virtually identical:
const resolvers = {
Query: {
hello: () => {
return 'Hello world!';
},
},
};
As you can see, instead of providing a function for a specific URL, we’re providing a function that matches a particular field on a type, in this case the hello field on the Query type. In GraphQL, this function that implements a field is called a resolver.
To make a request we need a query:
query {
hello
}
So here’s what happens when our server receives a GraphQL request:
- The server receives the request, and retrieves the GraphQL query.
- The query is traversed, and for each field the appropriate resolver is called. In this case, there’s just one field,
hello, and it’s on the Query type.
- The function is called, and it returns a result.
- The GraphQL library and server attaches that result to a response that matches the shape of the query.
So you would get back:
{ "hello": "Hello, world!" }
But here’s one trick, we can actually call the field twice!
query {
hello
secondHello: hello
}
In this case, the same lifecycle happens as above, but since we’ve requested the same field twice using an alias, the hello resolver is actually called twice. This is clearly a contrived example, but the point is that multiple fields can be executed in one request, and the same field can be called multiple times at different points in the query.
This wouldn’t be complete without an example of “nested” resolvers:
{
Query: {
author: (root, { id }) => find(authors, { id: id }),
},
Author: {
posts: (author) => filter(posts, { authorId: author.id }),
},
}
These resolvers would be able to fulfill a query like:
query {
author(id: 1) {
firstName
posts {
title
}
}
}
So even though the set of resolvers is actually flat, because they are attached to various types you can build them up into nested queries.
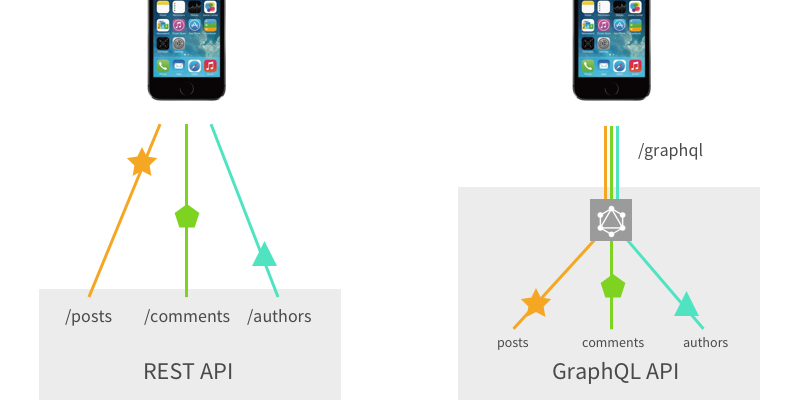
An artists’ interpretation of fetching resources with multiple REST roundtrips vs. one GraphQL request
Conclusion
At the end of the day, both REST and GraphQL APIs are just fancy ways to call functions over a network. If you’re familiar with building a REST API, implementing a GraphQL API won’t feel too different. But GraphQL has a big leg up because it lets you call several related functions without multiple roundtrips.
- Similar: Endpoints in REST and fields in GraphQL both end up calling functions on the server.
- Similar: Both REST and GraphQL usually rely on frameworks and libraries to handle the nitty-gritty networking boilerplate.
- Different: In REST, each request usually calls exactly one route handler function. In GraphQL, one query can call many resolvers to construct a nested response with multiple resources.
- Different: In REST, you construct the shape of the response yourself. In GraphQL, the shape of the response is built up by the GraphQL execution library to match the shape of the query.
Essentially, you can think of GraphQL as a system for calling many nested endpoints in one request. Almost like a multiplexed REST.
What does this all mean?
There are a lot of things we didn’t have space to get into in this particular post. For example, object identification, hypermedia, or caching. Perhaps that will be a topic for a later time. But I hope you agree that when you take a look at the basics, REST and GraphQL are working with fundamentally similar concepts.
I think some of the differences are in GraphQL’s favor. In particular, I think it’s really cool that you can implement your API as a set of small resolver functions, and then have the ability to send a complex query that retrieves multiple resources at once in a predictable way. This saves the API implementer from having to create multiple endpoints with specific shapes, and enables the API consumer to avoid fetching extra data they don’t need.
On the other hand, GraphQL doesn’t have as many tools and integrations as REST yet. For example, you can’t cache GraphQL results using HTTP caching as effectively as you can with REST results. However, there are tools that help remedy this. For example, you can cache GraphQL results in your frontend using Apollo Client, urql, and Relay. On the server side, RESTDataSource can help with caching GraphQL results fetched from REST endpoints.