
The core difference between GraphQL and REST APIs is that GraphQL is a specification, a query language, while REST is an architectural concept for network-based software.
Note: This article is mostly server-side related.
GraphQL is gaining momentum as a successor to REST APIs. However, it isn’t always a “replacement”, and making the decision to opt for GraphQL comes with several considerations.
Traditionally and when used “out of the box”, REST has had limitations like multiple network requests and overfetching data. To overcome these, Facebook developed GraphQL as an open-source data query and manipulation language for APIs.
GraphQL is a syntax for requesting data and lets you specify precisely what you need.
Depending on your use cases, you will need to choose between GraphQL or REST API, or a combination of both. To make a more informed decision, let’s take a look at REST and GraphQL, and understand some of the reasons for choosing GraphQL.
REST APIs
What is a REST API?
REST (Representational State Transfer) is an architectural style that conforms to a set of constraints when developing web services. It was introduced as a successor to SOAP APIs. REST, or RESTful APs, are Web Service APIs that follow the REST standards. Unlike SOAP, a REST API is not constrained to an XML format and can return multiple data formats depending on what is needed. The data formats supported by REST API include JSON, XML, and YAML.
When a client calls REST APIs the server transfers the resources in a standardized representation. They work by returning information about the source that was requested - and is translated into an interpretable format.
REST APIs allow for modifications and additions from the client-side to the server, drawing certain parallels with GraphQL Mutations, which we’ll cover more on.
Working with REST APIs
A REST request is made up of the endpoint, HTTP method, Header, and Body.
An endpoint contains a URI (Uniform Resource Identifier) that helps in identifying the resource online.
An HTTP method describes the type of request that is sent to the server. They are:
GET reads a representation of a specified source.POST creates a new specified source.PUT updates/replaces every resource in a collection.PATCH modifies a source.DELETE deletes a source.
When working with data, a RESTful API uses HTTP methods to perform CRUD (Create, Read, Update and Delete) operations.
Headers provide information to clients and servers for purposes like caching, AB Testing, authentication, and more.
The body contains information that a client wants to send to a server, such as the payload of the request.
GraphQL APIs
What is GraphQL?
GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. Maintained and developed primarily via the GraphQL Foundation, GraphQL has had incredible adoption across a variety of verticals and use cases with organizations like Twitter, Expedia, Shopify, and Hygraph to name a few.
To get into the details of GraphQL, refer to our post on What is GraphQL?
Advantages of GraphQL APIs
Let’s cover some of the basic advantages that help GraphQL stand out.
Data Fetching
One of the most common limitations of REST out-of-the-box is that of overfetching and underfetching. This happens because the only way for a client to download data is by hitting endpoints that return fixed data sets. It’s very difficult to design the API in a way that it’s able to provide clients with their exact data needs.
Overfetching means getting more information than you need. For example, if the endpoint holds data on burgers available at a restaurant, you’d hit the /burgers endpoint, and instead of only getting the names that you’re interested in, you may get everything that endpoint has to offer - including price, ingredients, calories, etc. With GraphQL, you’d simply need to dictate what you want in a query:
{
burgers {
name
}
}
Your response wouldn’t include any other information that the endpoint may be able to provide, giving you a predictable dataset to work with based on what you requested.
Schema and Type Safety
GraphQL uses a strongly typed system to define the capabilities of an API. All the types that are exposed in an API are written down in a schema using the GraphQL Schema Definition Language (SDL) and/or code-first.
Frontend teams can now work with the typed GraphQL API knowing that if any changes occur from the backend team on the APIs design, they’ll get this instant feedback when querying it from the frontend.
Popular tools like the GraphQL Code Generator can automatically build all of the code for queries, and mutations, directly from your codebase GraphQL query files. This speeds up development and prevents errors in production.
Rapid Product Development
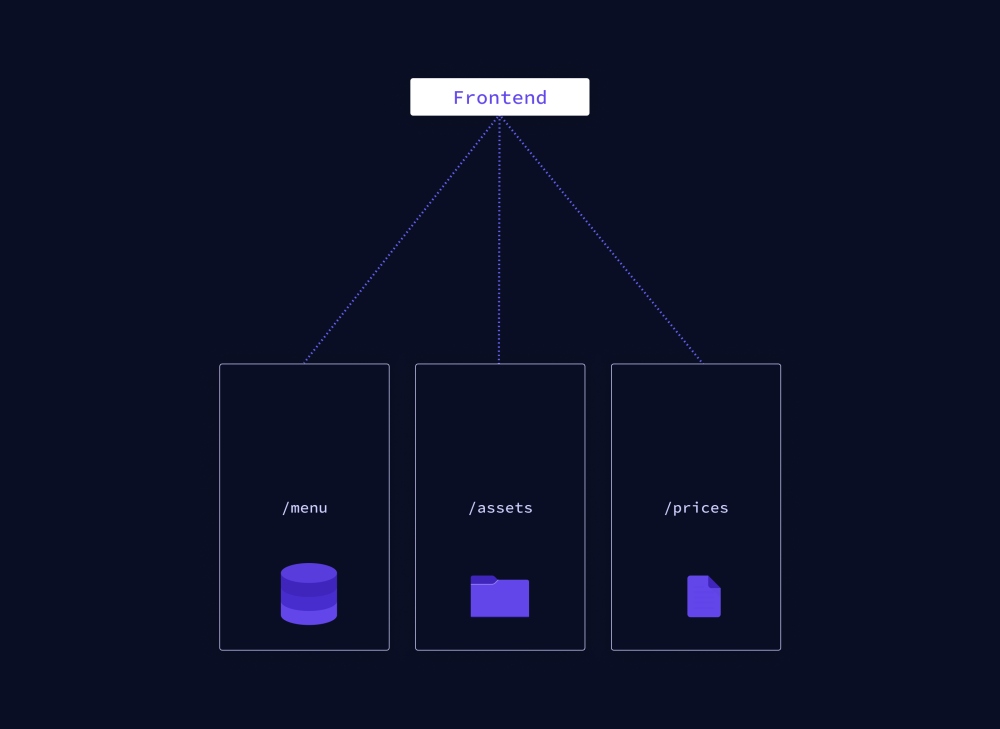
A common pattern with REST APIs is to structure the endpoints according to the views that you have inside your app (example /menu, /prices, /images, etc.). This is handy since it allows the client to get all required information for a particular view by simply accessing the corresponding endpoint.
The drawback of this approach is that it doesn’t allow for rapid iterations. With every change that is made to the UI, there is a risk that there is more (or less) data required than before.
Consequently, the backend needs to be adjusted as well to factor in those new data needs, being counterproductive and slowing down the process of product development.
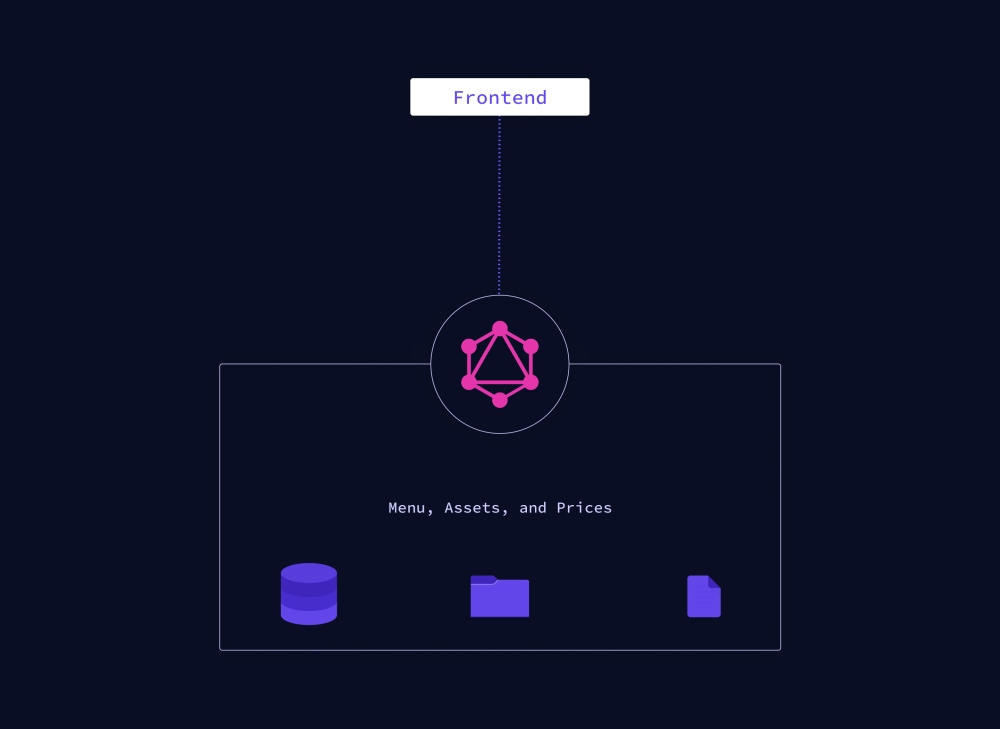
With the flexible nature of GraphQL, changes on the client-side can be made without any extra work on the server. Since clients can specify their exact data requirements, no backend adjustments need to be made when the design and data needs on the frontend change.
Schema Stitching
A major differentiation is the ability for stitching schemas. GraphQL can combine multiple schemas into a single schema to make it accessible to the client. For example, merging the schemas of a Burgers API and a Nutrition API by getting the details of a particular menu and the nutrition facts of the item into a single schema, from different sources.
{
burgers(where: { name: "cheeseburger"})
# from Menu endpoint
name
description
price
# from Nutrition endpoint
calories
carbohydrates
# from Restaurant endpoint
inStock
}
At Hygraph we believe that the next step from Schema Stitching is the ability to federate GraphQL and REST APIs into a single GraphQL endpoint.
GraphQL vs. REST
The core difference between GraphQL and REST APIs is that GraphQL is a specification, a query language, while REST is an architectural concept for network-based software.
GraphQL is great for being strongly typed, and self-documenting based on schema types and descriptions and integrates with code generator tools to reduce development time.
When thinking of one of the most known differentiations - the differences in expected responses for queries - in very simple terms, we can think of the process of ordering burgers. While the GraphQL burger meme has been around for some time, the clarification it provides still makes it simple to grasp the concepts.
Imagine you’re walking into a burger restaurant, and you order their cheeseburger. Regardless of how many times you order (calling your RESTful API), you get every ingredient in that double cheeseburger every time. It will always be the same shape and size (what’s returned in a RESTful response).
https://api.com/cheeseburger/
With GraphQL, you can “have it your way” by describing exactly how you want that cheeseburger to be. You can now have your cheeseburger (response) as a bun on top, followed by a patty, pickle, onion, and cheese (unless you’re vegan), without a bottom bun.
query getCheeseburger ($vegan: Boolean) {
cheeseburger {
bun
patty
pickle
onion
cheese @skip(if: $vegan)
}
}
Your GraphQL response is shaped and sized to be exactly how you describe it. Your response is exactly what you wanted, or queried - no more, no less, no different.

A REST API is an "architectural concept" for network-based software. GraphQL, on the other hand, is a query language and a set of tools that operate over a single endpoint. In addition, over the last few years, REST has been used to make new APIs, while the focus of GraphQL has been to optimize for performance and flexibility.
When using REST, you’d likely get a response of complete "datasets". If you wanted to request information from x objects, you’d need to perform x REST API requests. If you're requesting information on a product for a menu website, your requests may be structured in this way:
- Request
menu for burger names, descriptions, ingredients, etc. in one request
- Request
prices for prices pertaining to that menu in another request
- Request
images for menu shots from another dataset
- ... and so on
Conversely, if you wanted to gather some information from a specific endpoint, you couldn’t limit the fields that the REST API returns; you’ll always get a complete data set - or overfetching - when using REST APIs out of the box without added configurations.
GraphQL uses its query language to tailor the request to exactly what you need, from multiple objects down to specific fields within each entity. GraphQL would take x endpoint, and it can do a lot with that information, but you have to tell it what you want first.
Using the same example, the request would simply be to get menuItem, menuIngredients, menuImage, and menuPrice from the same endpoint, within one request, and no more. All other content within the database wouldn't be returned, so the issue of overfetching wouldn't be a concern.
Very similar to the burger analogy we highlighted before - REST gets you the cheeseburger that the restaurant has on the menu, but GraphQL lets you modify that burger to get exactly how much of what you want.
Opting for GraphQL against or with REST is a highly subjective decision, heavily influenced by the use-case. It is important not to consider GraphQL as an alternative to REST, nor as a replacement. To help simplify that decision, here are some key differentiators:
| GraphQL |
REST |
| A query language for solving common problems when integrating APIs |
An architectural style largely viewed as a conventional standard for designing APIs |
| Deployed over HTTP using a single endpoint that provides the full capabilities of the exposed service |
Deployed over a set of URLs where each of them exposes a single resource |
| Uses a client-driven architecture |
Uses a server-driven architecture |
| Lacks in-built caching mechanism |
Uses caching automatically |
| No API versioning required |
Supports multiple API versions |
| Response output in JSON |
Response output usually in XML, JSON, and YAML |
| Offers type-safety and auto-generated documentation |
Doesn't offer type-safety or auto-generated documentation |
| Allows for schema stitching and remote data fetching |
Simplifying work with multiple endpoints requires expensive custom middleware |