
Entity Framework Core is recommended and the most popular tool for interacting with relational databases on ASP NET Core. It is powerful enough to cover most possible scenarios, but like any other tool, it has its limitations. Long time people said (not without reason) that Entity Frmaework does not match high load systems and for these scenarios it is better to use Dapper. But time goes by and Entity Framework is growing and getting better, especially from the performance perspective. In addition to internal performance improvements for standard APIs of Entity Framework and performance improvements of the platform itself, Entity Framework provides a special set of features and configuration options dedicated to significantly increase performance. In this article we will consider Entity Framework Core from the performance perspective and compare it with Dapper as of July 2022. Let’s check if recommendation “rewrite everything on Dapper” is still actual :)
This article could be useful for developers who use Entity Framework Core in everyday development. Also, this article could be helpful to high-load system developers to update their knowledge about Entity Framework latest performance-oriented features.
Introduction to EF
Before diving into performance topic, it will be useful to remember what EF is and describe some aspects of its work, so we can better understand optimization approaches which we will consider in this article. So EF is an object-relational mapper, or in other words tool that binds C# object model (classes, collections, properties) with relational database model (tables, columns, rows, foreign keys etc). The main EF object, which allows developers to interact with the database, is class inherited from `DbContext`. The context contains several collection objects `DbSet`, which usually represent a database table. To access data from table we call these collections using LINQ queries, which are behind the scenes translated into SQL by calling methods `ToArray`, `ToList`, `FirstOrDefault` etc., so we can work with data as we usually work with regular C# objects.
public class AdventureWorksContext : DbContext
{
public virtual DbSet<Product> Products { get; set; }
...
}
...
public void ApplicationLogic()
{
using var context = new AdventureWorksContext();
// get list of products with filter
var bookProducts = context.Products.Where(p => p.Type == "Book").ToList();
// get single product by name
var singleBook = context.Products.Where(p => p.Name == "Harry Potter").FirstOrDefault();
// do data handling
...
}
The way how EF works gives developers several advantages. Firstly EF takes responsibility for forming correct and SQL injection safe requests to database using strictly typed LINQ queries. The same C# code will work for MSSQL, Oracle and MySQL, because concrete database provider implementations are hidden from developers using abstractions. Developers in most cases shouldn’t deal with SQL syntax at all and can fully concentrate on application logic. Secondly, EF includes a mechanism that tracks changes in object properties (change-tracking), allowing to form Update and Delete database queries without interaction with any SQL code. For example:
public void ApplicationLogic()
{
using var context = new AdventureWorksContext();
var bookProduct = context.Products.Where(p => p.Name == "Harry Potter").Single();
bookProduct.Name = "Harry Potter and the Sorcerer's Stone"
context.SaveChanges();
// name in DB was updated !
context.Remove(bookProduct);
context.SaveChanges();
// book was deleted from DB !
...
}
EF has reach functionality, which makes development process significantly easier and faster. Still, it comes with a price and each stage of processing before sending SQL request to database and after receiving a response consumes additional resources. Let’s try to make a simplified scheme of how EF works from constructing LINQ requests to receiving data in client code.
- Getting an instance of `DbContext`. To begin the work we need to get an instance of `DbContext`, which contains everything we need.
- Compiling LINQ query to SQL. `IQueryable` interface implementation, which we receive by calling LINQ extension methods on `DbSet`, is a request object which should be executed. The object is constructed in builder-like way: each extension method as `Where`, `OrderBy`, `Select` adds some additional information to request object, which should be translated to SQL. `IQueryable` inherits from `IEnumerable`, but until you explicitly call `IEnumerable` (or `IAsyncEnumerable`) methods — SQL query will not be constructed and executed. Translation process begins when method casting `IQueryable` to `IEnumerable` (or `IAsyncEnumerable`) such as `ToArray`, `ToList`, `FirstOrDefault` etc. was called. EF translates `IQueryable` to SQL while supporting an internal caching mechanism, which allows reusing calculation results for same LINQ queries.
- Sending SQL to database and receiving a response. (server-side calculations)
- Results materialization into C# objects.
- Objects registration into the change-tracking system. After materialization happens, EF by default registers objects in internal change-tracking system, which tracks object property changes and on calling `SaveChanges` forms the corresponding Update database query. Supporting change-tracking creates an overhead and consumes resources.
- Performing client-side part of LINQ query (client-side calculations). When receiving LINQ request EF tries to transform it to SQL so it can be executed on database side (server-side calculations). But in some cases requests cannot be fully translated to SQL so part of the expression should be calculated on client side after results from the database are received. In earlier versions of EF developers could know that request is executing on client side only from EF logs or by configuring throwing exceptions in such cases, but with the latest EF versions, when EF cannot fully convert LINQ query to SQL it will always throw an exception, requiring explicit call of `AsEnumerable`, `ToList` etc before LINQ expression part, which could be executed only on client code side (client-side calculations). You can get more detailed description of this mechanism by visiting this Microsoft article. It is for the benefit of the developer to write code in a way when most of the calculations, especially in `Where` block, is performed on database server side.
- Receiving results by calling client code.
As we can see, a lot of resource-consuming operations are happening between creating `DbContext` instance, calling ADO NET and receiving results in client code. These operations consume CPU resources, create a lot of objects, save references on them, create GC pressure, fill and flush internal caches etc. Dapper in its turn is a minimalistic proxy between ADO NET and client code, which lacks EF functionality, but has huge performance benefits over EF. Let’s demonstrate some code using Dapper:
public void ApplicationLogic()
{
using var sqlConnection = new SqlConnection(connectionString);
var product = connection.QuerySingleOrDefault<Product>(@"
select * from Products
where Name = @name
", new { name = "Harry Potter" });
}
Now when we better understand how EF works and what it does under the hood, we can move on to the system under test review, which we will try to optimize.
System Under Test (SUT)
For demonstration purposes we need some web API, which will interact with test MSSQL database AdventureWorks, implementing some of most common data access scenarios:
- GET request by Id with data from one table. Get product by Id
- GET request by Id with data from multiple related tables (JOIN-s). Get product with model and product category by id
- GET request of paged data from single table. Get products page
- GET request of paged data from multiple related tables (JOIN-s). Get products page with model and product category datas
- POST request for resourse creation. Create product
- PUT request for edit resourse. Edit product name
We need to implement several versions of API with different implementations of `IProductsRepository` using EF or Dapper for data access. For a complete load testing we will use NBomber for each of these scenarious one by one. To get more details on working with NBomber you can visit this article. For more fast running local test we in some cases will use some BenchmarkDotNet scenarious, which will repeat our API in miniature by calling different `IProductsRepository` implementations (Dapper, EF Default, EF with different improvement options) in DI scope:
private ServiceProvider EFCoreDefaultImplementationServiceProvider;
...
[GlobalSetup]
public void GlobalSetup()
{
BuildDefaultImplementationServiceProvider();
}
...
[Benchmark]
public async Task GetProduct_Benchmark()
{
// we will do several iterations, emulating several requests, to see difference in time and memory better
for (int i = 0; i < IterationsCount; i++)
{
// as for each HTTP request in web api, we will create DI scope
using var scope = EFCoreDefaultImplementationServiceProvider.CreateScope();
// ... from which we will resolve implementation under test
var repository = scope.ServiceProvider.GetRequiredService<IProductsRepository>();
// get product by id scenario as example
var product = await repository.GetProduct(ProductIds[i % (ProductIds.Length - 1)]);
}
}
After we get through all performance improvement recommendations in the list we will perform the last NBomber test, where we combine all improvements to make some conclusions. All code used in this article, demos, load testing scenarios etc. is available on GitHub repository.
Before we start optimization let’s do some initial measurements for Dapper and “out of the box” EF version. We will run each version of application sequentially, testing each scenario using 30 parallel clients and sending requests non-stop.
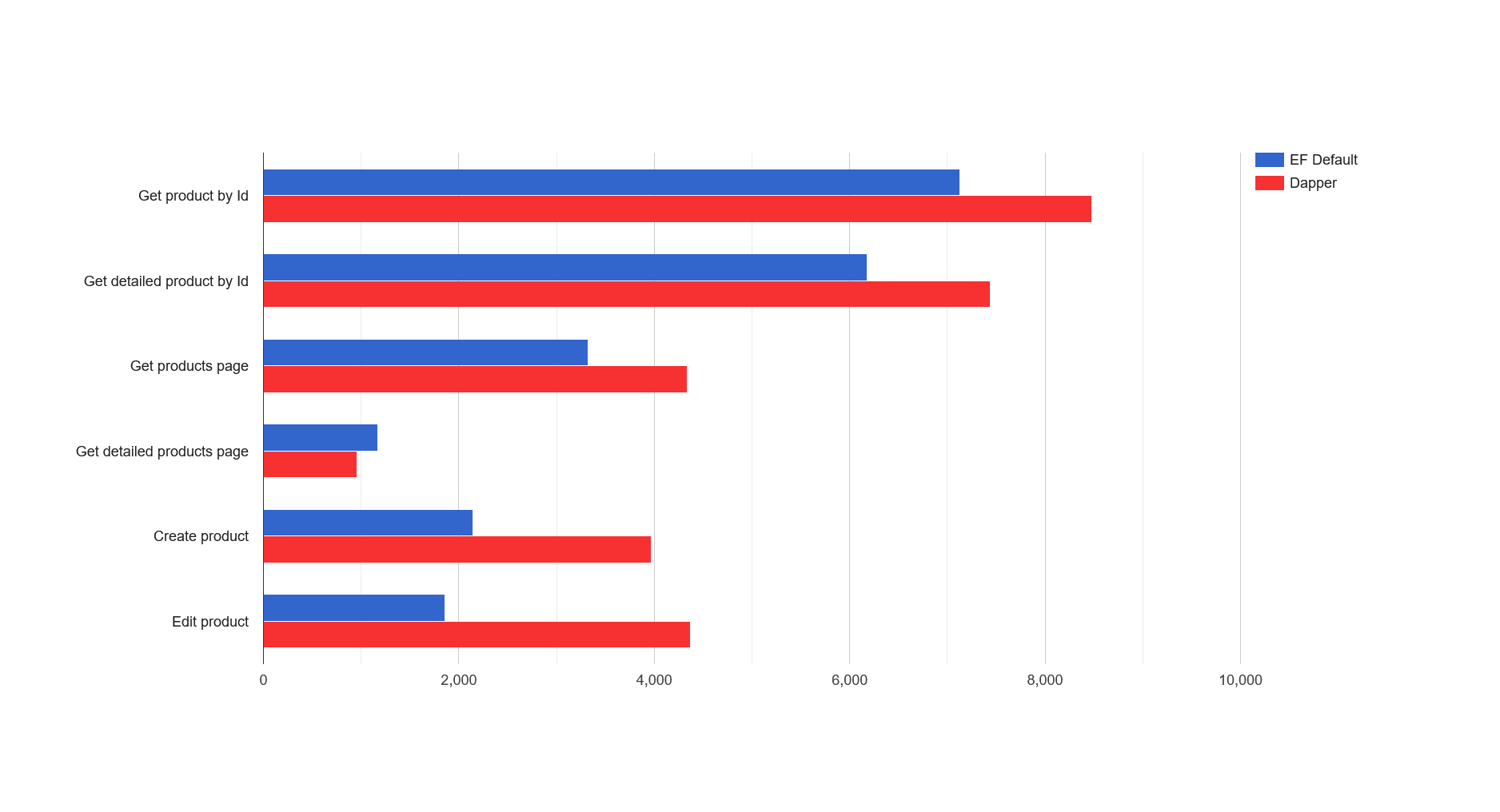
EF Default and Dapper
| Scenario |
EF Default (RPS) |
Dapper (RPS) |
| Get product by Id |
7124,1 |
8478,0 |
| Get detailed product by Id |
6180,5 |
7439,9 |
| Get products page |
3320,7 |
4341,2 |
| Get detailed products page |
1174,8 |
954,8 |
| Create product |
2146,2 |
3967,9 |
| Edit product |
1859,8 |
4371,7 |
As we can see, in this configuration EF is 19–30 percent less performant than Dapper in most read scenarios, and significantly inferior in creation and editing scenarios. Now we have a starting point to compare with, so let’s start improving.
DbContext pooling
To raise EF Core performance we need to gradually reduce the influence of intermediate stages ,described earlier, by reducing allocations, repeated calculations and by doing some calculations in advance if possible. First of all Microsoft recommends using pool for objects of type `DbContext`. Obvious advantage for this recomendation is reducing GC pressure by reusing “heavy” objects, which will positively influence application behavior under load. Easy configuration is another advantage — for enabling pooling you need to change single method call from `AddDbContext` to `AddDbContextPool` in Program.cs. Your data access code (in our case it is implementation of `IProductsRepository`) will not be affected. But worth noting that in this case your `DbContext` essentially becomes a singleton (instance of `DbContext` in the pool will leave during all application lifetime) and should not store any state between usings. However, if you need to use some scoped context data, EF developers created a good guide describing such possibility, which you can visit using this link. Also it is important to set correct pool size because when pool size exceeded, new instances of `DbContext` will be created.
public static void AddEfCore(this IServiceCollection services, IConfiguration config)
{
//services.AddDbContext<AdventureWorksContext>((dbContextConfig) =>
services.AddDbContextPool<AdventureWorksContext>((dbContextConfig) =>
{
dbContextConfig.UseSqlServer(config.GetConnectionString(ConnectionStringName));
});
services.AddScoped<IProductsRepository, EFCoreProductsRepository>();
}
Disable change tracking for read-only scenarios
As we mentioned before, change-tracking system allows us to update data by transforming changed properties of C# objects to SQL Update statements. This system is enabled by default but it makes sense only in scenarios when we need to edit or update something. In read-only scenario this system just creates additional overhead. Fortunately, this system can be easily disabled by calling `AsNoTracking` on your `IQueryable` expression.
public async Task<Product> GetProduct(int productId, CancellationToken cancellationToken = default)
{
return await _context.Products
.AsNoTracking()
.FirstOrDefaultAsync(x => x.ProductId == productId, cancellationToken);
}
For a couple of years, I got into the habit of always writing requests with `AsNoTracking`, because read-only scenarios usually appear more often than edit. But if you have no such habit, you need to do some work to analyze your data access code, add `AsNoTracking` and do some testing to be sure any edit scenario was not broken.
Worth adding that default request behavior could be configured in EF in a way where all requests will by default copy `AsNoTracking` behavior without calling it explicitly. You can configure it in `AddDbContext` call. Then you should manually add `AsTracking` in scenarios where you need to edit something.
public static void AddEfCore(this IServiceCollection services, IConfiguration config)
{
services.AddDbContext<AdventureWorksContext>((dbContextConfig) =>
{
...
dbContextConfig.UseQueryTrackingBehavior(QueryTrackingBehavior.NoTracking);
});
}
public void ApplicationLogic()
{
using var context = new AdventureWorksContext();
var bookProduct = context.Products.AsTracking().Where(p => p.Name == "Harry Potter").Single();
bookProduct.Name = "Harry Potter and the Sorcerer's Stone"
context.SaveChanges();
}
Using DbContext.Entry for editing
Let’s highlight and investigate test results for editing scenario (Edit product), where Dapper is two times more performant than EF. This result can be easily explained by looking into editing code in EF version of `IProductsRepository`:
...
var bookProduct = dbContext.Products.Where(p => p.Name == "Harry Potter").Single(); // < -- 1-st query to db
bookProduct.Name = "Harry Potter and the Sorcerer's Stone"
context.SaveChanges(); // <-- 2-nd query to DB
...
For performing an update with C# first you need to receive object, by requesting it from the database, then modify it in code and call `SaveChanges`, which sends another request to the database. Dapper is two times faster for editing because EF needs two times more database requests to perform an edit. But EF has one more way of editing entities, which allows us to perform single database request. For this we need to create `Product` instance manually, assign required values to properties, manually attach instance to `DbContext` change tracking, select only important properties for an update if needed, and then call `SaveChanges`. In our case, we only need to change product name, so the code will be:
public async Task EditProductName(int productId, string productName)
{
var product = new Product { ProductId = productId, Name = productName };
_context.Products.Attach(product);
_context.Entry(product).Property(x => x.Name).IsModified = true;
try
{
_ = await _context.SaveChangesAsync();
}
catch (DbUpdateConcurrencyException)
{
// exception is throws when @@ROWCOUNT is equal to 0
// which means no entity with such Id was updated
throw new ProductNotFoundException();
}
}
LINQ to SQL pre-compilation
An important part of EF work is the transformation of LINQ expressions, created by C# developer, to SQL queries, consumed by database. Requests compiling is often performed operation, so it should be considered as an optimization target. To avoid LINQ to SQL transformations during application handling workload, EF developers provide a mechanism for pre-compilation of LINQ code into a thread-safe delegate, for which all calculation was already performed and which could be saved in a static variable to be reused in the application. To create such a delegate, you need to pass your LINQ code into static method `EF.CompileQuery`/`EF.CompileAsyncQuery`, also passing all external variables used by your LINQ code as method parameters. As a result you will get a delegate of type `Func<TDbContext, TParameter1, …, TResult>` which you could call not wasting resources on LINQ to SQL translation while application handling workload.
private readonly AdventureWorksContext _context;
...
private static Func<AdventureWorksContext, int, CancellationToken, Task<Product>> _getProductByIdQuery =
EF.CompileAsyncQuery<AdventureWorksContext, int, Product>((ctx, productId, ct) =>
ctx.Products.AsQueryable().FirstOrDefault(x => x.ProductId == productId));
...
public async Task<Product> GetProduct(int productId, CancellationToken cancellationToken = default)
{
return await _getProductByIdQuery.Invoke(_context, productId, cancellationToken);
}
Despite the expected benefits of using this approach, such as reducing allocations and CPU use, it also comes at a cost. Firstly, as you can notice from code sample, the code became a bit less readable. Secondly, to use this approach you should consider spending more time than adding `AsNoTracking`, especially for rewriting and testing existing code. Separately I would like to note that `EF.CompileAsyncQuery` method interface is, in my opinion, a bit confusing and its documentation is not very detailed. To get familiar with existing documentation, please follow this link.
Disable internal concurrency checks
`DbContext` in Entity Framework Core, unlike the full framework version, is not supporting multithread scenarios. To support this limitation, EF contains internal checks, which detects accessing `DbContext` from several threads and through clear exception notify developers of improper context using. However, if your application was repeatedly tested in production for a long time, you are absolutely sure that you have no concurrency errors and you are using `DbContext` in a correct way, should we consider such checks as an overhead that we can optimize ? All recommendations above could create some discomfort while developing and have some limitations, but none of them compromise the correctness and operability of EF. Disabling concurrency checking code could have unpredictable effects and there is a direct warning about it in EF documentation:
WARNING: Only disable thread safety checks after thoroughly testing that your application doesn’t contain such concurrency bugs.
But in the context of this article when listing ways to improve EF performance it is worth noting that we have the ability to disable such checks for `DbContext`. To do this you need to call correspondent configuration method in `AddDbContext`/`AddDbContextPool`:
public static void AddEfCore(this IServiceCollection services, IConfiguration config)
{
services.AddDbContextPool<AdventureWorksContext>(
dbContextConfig =>
{
...
dbContextConfig.EnableThreadSafetyChecks(enableChecks: false);
});
...
}
This optimization option was tested with BenchmarkDotNet but compared to others shows minimal influence on application performance. Unfortunately, I could not reproduce 5 percent performance improvement described in this GitHub issue. It is up to you whether to apply this optimization or not.
| Scenario name |
EF Default (ms) |
EF Disable concurrency check (ms) |
EF Context Pooling (ms) |
EF Context Pooling and Disable concurrency check (ms) |
| Create |
2,015.9 |
2,031.8 |
1,867.9 |
1,876.7 |
| Edit |
2,404.7 |
2,400.6 |
2,245.6 |
2,258.2 |
| Get by Id |
1,067.5 |
1,055.8 |
859.2 |
886.6 |
| Get by Id full |
1,186.6 |
1,246.2 |
984.8 |
973.0 |
| Get page |
8,752 |
8,426 |
8,105 |
8,102 |
| Get page full |
3,413 |
3,429 |
3,368 |
3,394 |
Combining improvements
We have considered Microsoft’s main recommendations for improving EF’s performance, explored how they work and pointed out possible pitfalls. Let’s summarize the list:
- use `DbContext` pooling
- use `AsNoTracking` for read-only scenarios
- use pre-compiled LINQ to SQL queries
- disable EF internal concurrency checks (remembering the risks)
It is time to combine them and run a load test.
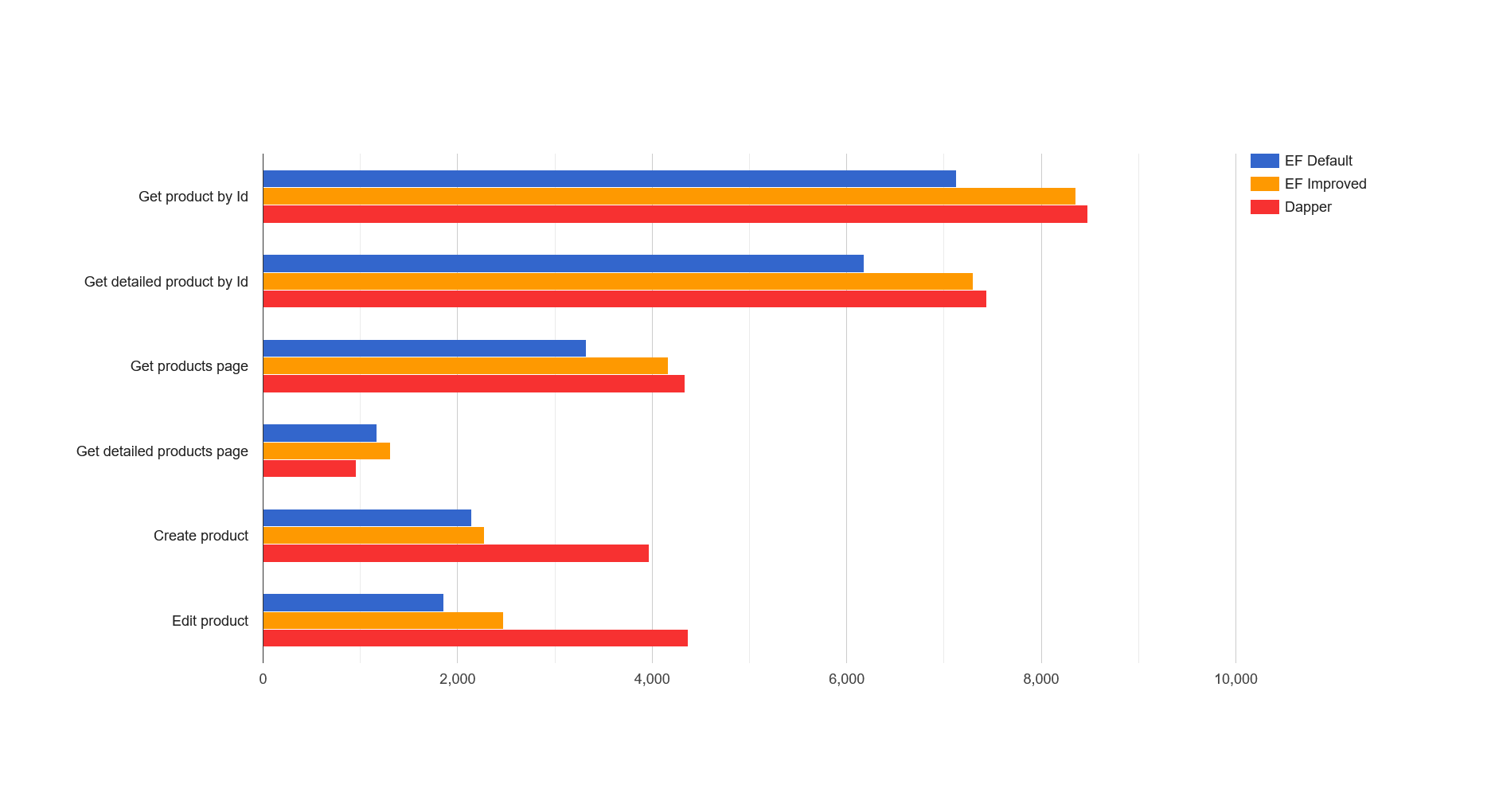
EF Default, EF Improved and Dapper
| Scenario |
EF Default (RPS) |
EF Improved (RPS) |
Dapper (RPS) |
| Get product by Id |
7124,1 |
8354,3 |
8478,0 |
| Get detailed product by Id |
6180,5 |
7297,5 |
7439,9 |
| Get products page |
3320,7 |
4165,5 |
4341,2 |
| Get detailed products page |
1174,8 |
1306,2 |
954,8 |
| Create product |
2146,2 |
2279,1 |
3967,9 |
| Edit product |
1859,8 |
2472,0 |
4371,7 |
According to testing results of three API versions, we can see that improvements allow us to increase performance of EF compared to “out of the box” configuration by 6–25 percent. Also, the gap between Dapper and EF was significantly reduced and now Dapper is only 1.5–4.2 percent better for read scenarios.
Unfortunately, we were not able to get performance similar to Dapper for edit and create scenarios, while isolating C# developer from writing SQL code. Dapper is 76 better in edit scenario and 74 better in create scenario. However, EF still allows developer to write SQL queries manually using `DbContext.Database.ExecuteSqlRaw`. This way you can optimize the bottleneck without using external libraries except for EF. Benchmark results show us that EF `ExecuteSqlRaw` performance is almost identical to code written with Dapper for both scenarios:
public async Task EditProductName(int productId, string productName)
{
var rowsAffected = await _context.Database.ExecuteSqlRawAsync(@"UPDATE [Production].[Product]
SET [Name] = {0}
WHERE [ProductID] = {1}
SELECT @@ROWCOUNT", productName, productId);
...
}
| Benchmark name |
Mean (ms) |
Allocated (MB) |
| Edit_Default |
2,404.7 |
70 |
| Edit_CombinedImprovements |
1,780.5 |
21 |
| Edit_ContextPoolingRawSql |
940.6 |
4 |
| Edit_Dapper |
916.6 |
3 |
public async Task<int> CreateProduct(Product product)
{
var productId = await _context.Database.ExecuteSqlRawAsync(@"INSERT INTO [Production].[Product]
(Name, ProductNumber, SafetyStockLevel, ReorderPoint, StandardCost, ListPrice, Class, Style, Color, SellStartDate, DaysToManufacture)
VALUES
({0}, {1}, {2}, {3}, {4}, {5}, {6}, {7}, {8}, {9}, {10})
SELECT CAST(SCOPE_IDENTITY() as int)",
product.Name, product.ProductNumber, product.SafetyStockLevel, product.ReorderPoint, product.StandardCost, product.ListPrice,
product.Class, product.Style, product.Color, product.SellStartDate, product.DaysToManufacture);
return productId;
}
| Benchmark name |
Mean (ms) |
Allocated (MB) |
| Create_Default |
2,015.9 |
77 |
| Create_ContextPoolingRawSql |
947.9 |
9 |
| Create_Dapper |
941.3 |
7 |
Worth noting that in EF 7 roadmap it is planned to perform optimization of change-tracking mechanism and improve performance for Insert and Update scenarious:
For EF7, we plan to focus on performance related to database inserts and updates. This includes performance of change-tracking queries, performance of `DetectChanges`, and performance of the insert and update commands sent to the database.
We can track the development process on GitHub, hoping that gap between EF and Dapper will be significantly reduced with the next release.
Summary
As we can see, EF Core as for July 2022 with correct configuration can show results comparable to Dapper for most read scenarios while saving advantage of the generation of correct and safe SQL code while using strictly-typed C# LINQ expressions. However, EF is still far behind Dapper in Insert and Update scenarios while using C# objects and change-tracking for editing. Still, developers can optimize this by using the raw-SQL approach if needed. We could expect reducing the gap between EF and Dapper in these scenarios in the next release. In my opinion, and as the practice has shown, the latest versions of EF Core are quite applicable for high-load systems. Given the rich functionality, support, powerful community and evolving performance of EF Core and NET platform with each release, you will make the right decision by choosing EF Core. Hope this article was useful for you.
Thank you for your attention!