
In the world of modern software architecture, reliable communication between different components or microservices is crucial. This is where RabbitMQ, a queue based message broker, can play a vital role. RabbitMQ is a popular choice for implementing message queuing systems, ensuring reliable and scalable communication between various parts of an application.
For a recent migration project, my client needed to (re-)build an existing queuing system integrated in a .NET application. Due to the platform requirements, and the knowledge and experience available within the organisation, we decided to use RabbitMQ. Our approach was to keep it as simple and robust as possible. So we decided to build the implementation according to the RabbitMQ .NET manual and using the official RabbitMQ Client for .NET. Thankfully my client allowed me to share the learnings and decisions we made during the project together with the (slightly simplified) code as well.
In this article, we’ll explore the implementation of RabbitMQ in an ASP.NET Core application. We’ll delve into the decisions and practices that we applied to make our RabbitMQ-based queuing implementation both simple and robust. We found out that, though the documentation is outstanding, we had to make a few implementation decisions that weren’t as trivial as we would suspect. We chose to write a small library that integrates the RabbitMQ Client with the ASP.NET framework with an abstraction layer that is easy to implement by the development teams. Since the information we found on how-to integrate the client was limited, I decided to share what we have learnt and which decisions we made in this blogpost.
Requirements
This projects uses queues for various use cases of asynchronous processing of documents, reporting and handling callbacks of neighbouring services. The load on the queue system is relatively low (thousands of messages per day) and the queue processing is allowed to have a bit of latency, an hour of lead time is acceptable. But, due to the nature of the application, robustness and guaranteed delivery is very important. After a deep-dive into the project’s existing functionality, we concluded that the implementation should be as close to ACID (Atomicity, Consistency, Isolation, Durability) as reasonably possible.
Performance on the other hand is low on the requirement list. Meaning that we are quite happy to make decisions that have performance implications for the sake of robustness. However, our hosing platform (Kubernetes) and the availability requirements that are placed on the system, do require the system to allow for concurrent processing and horizontal scaling and thus multiple instances of consumers and producers on a shared queue.
The system is reasonably large, complex and has a lot of technical debt. It currently uses a lot of different (outdated) frameworks and is in the process of a migration to .NET Core and a Kubernetes platform. This places a relative high cognitive load on the developers, so keeping the new queueing setup simple and easy to understand is important.
Decisions in the Queueing setup
The first hurdle in engineering the queueing system is creating an understanding of which messages are placed on which queue. We decided to make a one-to-one link of queue message types to queues. So no polymorphism in the queue messages, meaning every message type has its own queue. This allows us to keep the naming convention of the queue simple: the queue name is equal to the queue class name within the application.
To further simplify things we will use the default (direct) exchange. This results in only one Consumer-implementation per Queue. And in the case that we need to apply a type of fan-out pattern or routing of messages, we can just implement that logic in a Consumer and having that produce multiple messages to other queues. This is not the most performant approach, but it does meet our requirement of simplicity.
It is essential that the risk of losing messages in case of a failure or outage is as small as possible. So we rely on the Dead Letter exchange to enable us to manually recover from a failure during processing of the message.
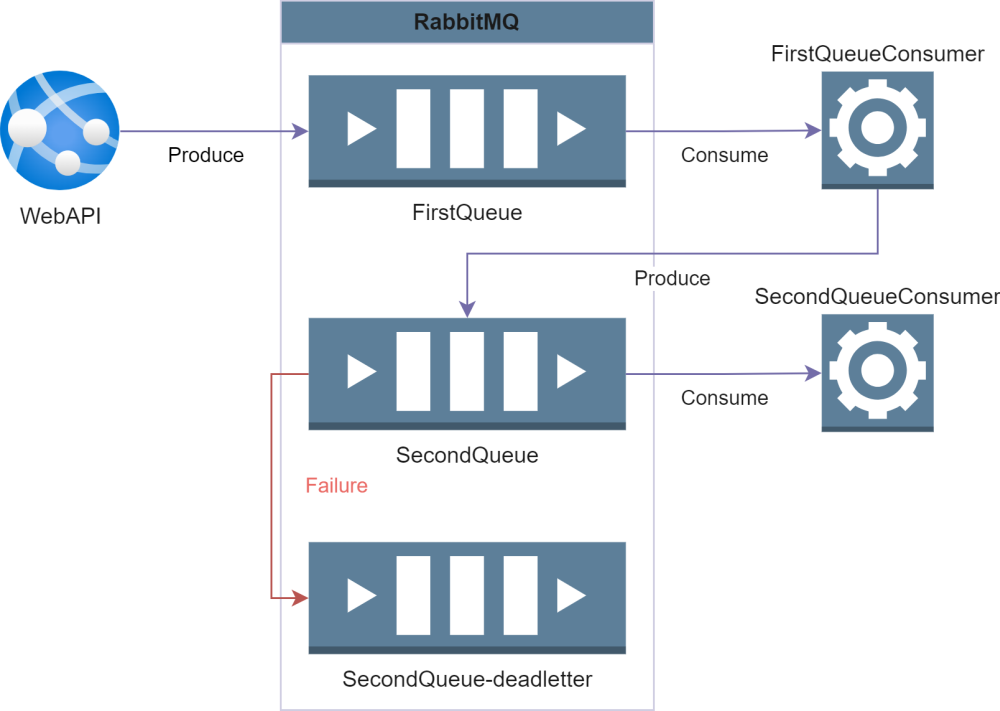
We will also be using Quorum queues in a three node cluster. Quorum queues, as the name suggest, use a quorum to establish a consensus on the state of the queue. This shared truth protects the cluster from failure or temporary outage of a node. Quorum queues have some drawbacks in terms of memory consumption and overall performance, but given our requirements that is totally acceptable.
• • •
Connecting with RabbitMQ
The RabbitMQ documentation has a very detailed HelloWorld example. But it does not provide any guidance as to how we should implement this in a application that uses the default ASP.NET Dependency Injector. So we will start constructing our library at the base, the connection to RabbitMQ and its integration with the Dependency Injector (DI).
RabbitMQ uses a ConnectionFactory that can create one, or more connections. On that subject the documentation states:
The connection then will be used to perform all subsequent operations. Connections are meant to be long-lived. Opening a connection for every operation (e.g. publishing a message) would be very inefficient and is highly discouraged.
So we can conclude that the connection should be provided as a Singleton, resulting in one connection for the entire host. The responsibility of creating and disposing of that single connection is placed in the ConnectionProvider:
internal sealed class ConnectionProvider : IDisposable, IConnectionProvider
{
private readonly ILogger<ConnectionProvider> _logger;
private readonly ConnectionFactory _connectionFactory;
private IConnection _connection;
public ConnectionProvider(ILogger<ConnectionProvider> logger, ConnectionFactory connectionFactory)
{
_logger = logger;
_connectionFactory = connectionFactory;
}
public void Dispose()
{
try
{
if (_connection != null)
{
_connection?.Close();
_connection?.Dispose();
}
}
catch (Exception ex)
{
_logger.LogCritical(ex, "Cannot dispose RabbitMq connection");
}
}
public IConnection GetConnection()
{
if (_connection == null || !_connection.IsOpen)
{
_connection = _connectionFactory.CreateConnection();
}
return _connection;
}
}
services.AddSingleton<IAsyncConnectionFactory>(provider =>
{
var factory = new ConnectionFactory
{
UserName = settings.RabbitMqUsername,
Password = settings.RabbitMqPassword,
HostName = settings.RabbitMqHostname,
Port = settings.RabbitMqPort,
DispatchConsumersAsync = true,
AutomaticRecoveryEnabled = true,
// Configure the amount of concurrent consumers within one host
ConsumerDispatchConcurrency = settings.RabbitMqConsumerConcurrency.GetValueOrDefault(),
};
return factory;
});
services.AddSingleton<IConnectionProvider, ConnectionProvider>();
Setting up a Channel
When the connectioni s successfully created, it is time to open a Channel. AMQP (the protocol used by RabbitMQ) uses Channels as a way to multiplex multiple streams of communications over one connection. This limits the amount of TCP connections, while still separating different communications with the queueing server.
On the subject of implementing the Channels, the documentation is more vague:
Channels are also meant to be long-lived but since many recoverable protocol errors will result in channel closure, channel lifespan could be shorter than that of its connection. Closing and opening new channels per operation is usually unnecessary but can be appropriate. When in doubt, consider reusing channels first.
After a bit more research we found out that in our use case there are two reasons to create a multiple Channels:
- RabbitMQ states that “Channel instances must not be shared by threads that publish on them.“ And after some experimenting we found out that sharing a connection with multiple threads does in fact result in exceptions.
- Make using of transactions is only possible when creating one transaction per channel at the same time. More on that later in this article.
With this information we concluded that, for our use case, it would be the most logical option to create a new Channel with every Scope of the Dependency Injector (DI). This will result in every request to our API having its own Channel. And the concurrent consumption of every queue message will also have a dedicated Channel. Creating that many Channels, will have some performance drawbacks. We looked at alternatives such as using a pool of Channels and supplying those to the threads. But since robustness and simplicity are more important to us than performance, we found that this is an acceptable trade-off.
Similar to the ConnectionProvider, we built a ChannelProvider which we registered as a Scoped service.
internal sealed class ChannelProvider : IDisposable, IChannelProvider
{
private readonly IConnectionProvider _connectionProvider;
private readonly ILogger<ChannelProvider> _logger;
private IModel _model;
public RabbitMqChannelProvider(
IConnectionProvider connectionProvider,
ILogger<ChannelProvider> logger)
{
_connectionProvider = connectionProvider;
_logger = logger;
}
public IModel GetChannel()
{
if (_model == null || !_model.IsOpen)
{
_model = _connectionProvider.GetConnection().CreateModel();
}
return _model;
}
public void Dispose()
{
try
{
if (_model != null)
{
_model?.Close();
_model?.Dispose();
}
}
catch (Exception ex)
{
_logger.LogCritical(ex, "Cannot dispose RabbitMq channel or connection");
}
}
}
services.AddScoped<IChannelProvider, ChannelProvider>();
Declaring the Queue
Before we can start producing and consumer messages, we must declare our Queues. We built a layer over the ChannelProvider that is responsible for the declaration and configuration of the queue’s and its deadlettering properties, the QueueChannelProvider. This class uses a generic-type that indicates for which QueueMessage the queue will be declared.
During the declaration of the Queues, a few arguments are provided to indicate the use of Quorum queues and ensuring guaranteed delivery of the message. And in a similar manner the deadletter-queue is declared, configured and linked to the message queue.
internal class QueueChannelProvider<TQueueMessage> : IQueueChannelProvider<TQueueMessage> where TQueueMessage : IQueueMessage
{
private readonly IChannelProvider _channelProvider;
private IModel _channel;
private readonly string _queueName;
public QueueChannelProvider(IChannelProvider channelProvider)
{
_channelProvider = channelProvider;
_queueName = typeof(TQueueMessage).Name;
}
public IModel GetChannel()
{
_channel = _channelProvider.GetChannel();
DeclareQueueAndDeadLetter();
return _channel;
}
private void DeclareQueueAndDeadLetter()
{
var deadLetterQueueName = $"{_queueName}{QueueingConstants.DeadLetterAddition}";
// Declare the DeadLetter Queue
var deadLetterQueueArgs = new Dictionary<string, object>
{
{ "x-queue-type", "quorum" },
{ "overflow", "reject-publish" } // If the queue is full, reject the publish
};
_channel.ExchangeDeclare(deadLetterQueueName, ExchangeType.Direct);
_channel.QueueDeclare(deadLetterQueueName, true, false, false, deadLetterQueueArgs);
_channel.QueueBind(deadLetterQueueName, deadLetterQueueName, deadLetterQueueName, null);
// Declare the Queue
var queueArgs = new Dictionary<string, object>
{
{ "x-dead-letter-exchange", deadLetterQueueName },
{ "x-dead-letter-routing-key", deadLetterQueueName },
{ "x-queue-type", "quorum" },
{ "x-dead-letter-strategy", "at-least-once" }, // Ensure that deadletter messages are delivered in any case see: https://www.rabbitmq.com/quorum-queues.html#dead-lettering
{ "overflow", "reject-publish" } // If the queue is full, reject the publish
};
_channel.ExchangeDeclare(_queueName, ExchangeType.Direct);
_channel.QueueDeclare(_queueName, true, false, false, queueArgs);
_channel.QueueBind(_queueName, _queueName, _queueName, null);
}
}
services.AddScoped(typeof(IQueueChannelProvider<>), typeof(QueueChannelProvider<>));
Defining the queue message
Before we can start to Publish and Consume messages there is one last step we need to figure out, the message itself. We defined a queue message as an implementation of our IQueueMessage interface.
Every message gets a Time To Live (TTL) property. When the TTL is exceeded, the message will be dead-lettered by RabbitMQ. This ensures that processing will be done in a timely manner and messages do not populate the queue indefinitely. The developer is responsible for picking a TTL that is realistic and makes sense giving the functional requirement of that particular queue message. For example, a notification might be due within a few minutes and is otherwise irrelevant. But a background process can be allowed to have a lot more time and might have a deadline of the next day before it becomes an issue.
To enable log correlation we added an unique identifier to every message. That will be set on the moment of publishing and can be attached to log-messages during the handling of the message.
public interface IQueueMessage
{
Guid MessageId { get; set; }
TimeSpan TimeToLive { get; set; }
}
Publishing messages
At this point we have everything ready to start producing messages. We created an interface (and implementation) that can be used to produce queue messages using a single function call. That QueueProducer is responsible to deliver the message to the Queue, or throw an exception.
public interface IQueueProducer<in TQueueMessage> where TQueueMessage : IQueueMessage
{
void PublishMessage(TQueueMessage message);
}
The RabbitMQ client requires the message to be serialized to a byte array. We decided on a JSON formatting with UTF8 encoding, since most of our API-calls use a similar serialization format.
There are all kinds of headers and properties that can be added to the published message. But the two that matter are the Delivery mode and the Expiration (or TTL). Given our requirements we chose the Persistent delivery mode, which means that the message is stored on a persistent storage medium instead of in-memory. The TTL is provided by the message itself.
internal class QueueProducer<TQueueMessage> : IQueueProducer<TQueueMessage> where TQueueMessage : IQueueMessage
{
private readonly ILogger<QueueProducer<TQueueMessage>> _logger;
private readonly string _queueName;
private readonly IModel _channel;
public QueueProducer(IQueueChannelProvider<TQueueMessage> channelProvider, ILogger<QueueProducer<TQueueMessage>> logger)
{
_logger = logger;
_channel = channelProvider.GetChannel();
_queueName = typeof(TQueueMessage).Name;
}
public void PublishMessage(TQueueMessage message)
{
if (Equals(message, default(TQueueMessage))) throw new ArgumentNullException(nameof(message));
if (message.TimeToLive.Ticks <= 0) throw new QueueingException($"{nameof(message.TimeToLive)} cannot be zero or negative");
// Set message ID
message.MessageId = Guid.NewGuid();
try
{
var serializedMessage = SerializeMessage(message);
var properties = _channel.CreateBasicProperties();
properties.Persistent = true;
properties.Type = _queueName;
properties.Expiration = message.TimeToLive.TotalMilliseconds.ToString(CultureInfo.InvariantCulture);
_channel.BasicPublish(_queueName, _queueName, properties, serializedMessage);
}
catch (Exception ex)
{
_logger.LogError(ex, msg);
throw new QueueingException(msg);
}
}
private static byte[] SerializeMessage(TQueueMessage message)
{
var stringContent = JsonConvert.SerializeObject(message);
return Encoding.UTF8.GetBytes(stringContent);
}
}
services.AddScoped(typeof(IQueueProducer<>), typeof(QueueProducer<>));
Consuming messages
After constructing the components to produce messages, we can dive into the most complex part; the consumption of the queue messages. The setup we designed is comprised of three parts
- IQueueConsumer — an interface for the consumer that can be implemented with the logic of processing the queue message
- QueueConsumerHandler — A handler that handles the registration of the consumer to RabbitMQ. The handler is responsible for delegating any incoming messages to an instance of an implementation of the IQueueConsumer. But also handling any errors that might occur during the handling of the queue message.
- QueueConsumerRegistratorService — A (Hosted) service that triggers the QueueConsumerHandler to registrate its consumer and start handling messages.
The IQueueConsumer interface is quite simple and easy implement. Since most of our application logic is async, we choose an async consumer implementation. These Consumers will be registered as Scoped services to the DI.
public interface IQueueConsumer<in TQueueMessage> where TQueueMessage : class, IQueueMessage
{
Task ConsumeAsync(TQueueMessage message);
}
Registering is done by the QueueConsumerHandler via a subscription to the RabbitMQ queue using the BasicConsume command. Linked to this registration is a handler function (HandleMessage) that is triggered upon each incoming message. This can happen concurrently, depending on how the ConsumerDispatchConcurrency setting is configured in the ConnectionFactory.
Given our ACID-like requirements, we would like the processing of the queue message to happen atomicly. Meaning that either the message is successfully processed and all the queue messages that are created during the process are published on their respective Queues. Or in, case of a failure, the whole processing is reverted and the message is rejected. In order to achieve this, we considered two options:
- Building a list of messages that have to be published, and publishing them all at once right before Acking the incoming message.
- Using the transaction mechanism of AMQP/RabbitMQ and committing the transaction before Acking the message.
As stated in the requirements, we would like the to keep our implementation as simple as possible. So we decided to go with a transaction based implementation. However that implementation does come with a small risk:
RabbitMQ provides no atomicity guarantees even in case of transactions involving just a single queue, e.g. a fault during tx.commit can result in a sub-set of the transaction’s publishes appearing in the queue after a broker restart.
Meaning that atomicity is not fully guaranteed in case of a RabbitMQ failure during the commit of a transaction. The alternative of building a list and returning it before Acking poses a similar (possibly greater) risk of a system failure during the publishing or acking. So we had to accept this downside and try to mitigate it as much a possible.
Transactions in RabbitMQ are linked to Channels. Each Channel is either in normal or transaction mode. When enabling transaction mode, every action on the Channel is placed in a transaction until either the transaction is committed or rolled back. Since we do not want consumers to have conflicts with each others transactions, we must ensure that every transaction occurs on its own dedicated Channel.
The handler function (HandleMessage) request the DI for new Scope from which the IQueueConsumer implementation can be injected. Remember that the ChannelProvider is registed as a Scoped service, so any logic that is triggered from within the QueueConsumer is now happening on a new dedicated channel for the processing of that particular queue message. The Handler then enables transaction mode on this Channel, so any message that is produced on this Channel is placed in the transaction.
It then delegates the queue message to the QueueConsumer instance which contains (or calls) all logic that is needed for handling the queue message. When the QueueConsumer is finished processing the message, the transaction can be committed and the message is Acked. Or, in case of a failure or exception, the transaction is rolled back and the message is Rejected. In our case, the latter one will trigger the dead-lettering of the queue message. To mitigate the risk mentioned earlier, the handler validates the state of the Channels before committing the transaction.
Finally, after all the processing is done. The Handler will dispose of the DI Scope, which will result in the producing channel being closed and disposed.
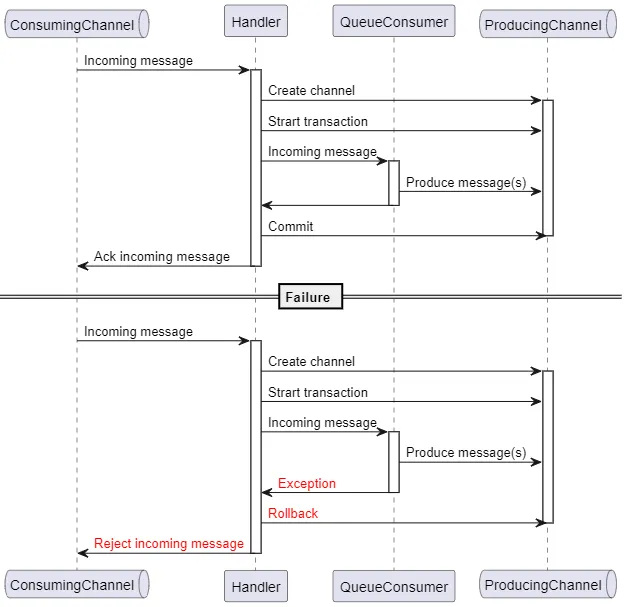
Sequence diagram of the transactional consumption process of a queue message
internal class QueueConsumerHandler<TMessageConsumer, TQueueMessage> : IQueueConsumerHandler<TMessageConsumer, TQueueMessage> where TMessageConsumer : IQueueConsumer<TQueueMessage> where TQueueMessage : class, IQueueMessage
{
private readonly IServiceProvider _serviceProvider;
private readonly ILogger<QueueConsumerHandler<TMessageConsumer, TQueueMessage>> _logger;
private readonly string _queueName;
private IModel _consumerRegistrationChannel;
private string _consumerTag;
private readonly string _consumerName;
public QueueConsumerHandler(IServiceProvider serviceProvider,
ILogger<QueueConsumerHandler<TMessageConsumer, TQueueMessage>> logger)
{
_serviceProvider = serviceProvider;
_logger = logger;
_queueName = typeof(TQueueMessage).Name;
_consumerName = typeof(TMessageConsumer).Name;
}
public void RegisterQueueConsumer()
{
var scope = _serviceProvider.CreateScope();
// Request a channel for registering the Consumer for this Queue
_consumerRegistrationChannel = scope.ServiceProvider.GetRequiredService<IQueueChannelProvider<TQueueMessage>>().GetChannel();
var consumer = new AsyncEventingBasicConsumer(_consumerRegistrationChannel);
// Register the trigger
consumer.Received += HandleMessage;
try
{
_consumerTag = _consumerRegistrationChannel.BasicConsume(_queueName, false, consumer);
}
catch (Exception ex)
{
var exMsg = $"BasicConsume failed for Queue '{_queueName}'";
_logger.LogError(ex, exMsg);
throw new QueueingException(exMsg);
}
}
public void CancelQueueConsumer()
{
try
{
_consumerRegistrationChannel.BasicCancel(_consumerTag);
}
catch (Exception ex)
{
var message = $"Error canceling QueueConsumer registration for {_consumerName}";
_logger.LogError(message, ex);
throw new QueueingException(message, ex);
}
}
private async Task HandleMessage(object ch, BasicDeliverEventArgs ea)
{
// Create a new scope for handling the consumption of the queue message
var consumerScope = _serviceProvider.CreateScope();
// This is the channel on which the Queue message is delivered to the consumer
var consumingChannel = ((AsyncEventingBasicConsumer)ch).Model;
IModel producingChannel = null;
try
{
// Within this processing scope, we will open a new channel that will handle all messages produced within this consumer/scope.
// This is neccessairy to be able to commit them as a transaction
producingChannel = consumerScope.ServiceProvider.GetRequiredService<IChannelProvider>()
.GetChannel();
// Serialize the message
var message = DeserializeMessage(ea.Body.ToArray());
// Enable transaction mode
producingChannel.TxSelect();
// Request an instance of the consumer from the Service Provider
var consumerInstance = consumerScope.ServiceProvider.GetRequiredService<TMessageConsumer>();
// Trigger the consumer to start processing the message
await consumerInstance.ConsumeAsync(message);
// Ensure both channels are open before committing
if (producingChannel.IsClosed || consumingChannel.IsClosed)
{
throw new QueueingException("A channel is closed during processing");
}
// Commit the transaction of any messages produced within this consumer scope
producingChannel.TxCommit();
// Acknowledge successfull handling of the message
consumingChannel.BasicAck(ea.DeliveryTag, false);
}
catch (Exception ex)
{
var msg = $"Cannot handle consumption of a {_queueName} by {_consumerName}'";
_logger.LogError(ex, msg);
RejectMessage(ea.DeliveryTag, consumingChannel, producingChannel);
}
finally
{
// Dispose the scope which ensures that all Channels that are created within the consumption process will be disposed
consumerScope.Dispose();
}
}
private void RejectMessage(ulong deliveryTag, IModel consumeChannel, IModel scopeChannel)
{
try
{
// The consumption process could fail before the scope channel is created
if (scopeChannel != null)
{
// Rollback any massages within the transaction
scopeChannel.TxRollback();
}
// Reject the message on the consumption channel
consumeChannel.BasicReject(deliveryTag, false);
}
catch (Exception bex)
{
var bexMsg =
$"BasicReject failed";
_logger.LogCritical(bex, bexMsg);
}
}
private static TQueueMessage DeserializeMessage(byte[] message)
{
var stringMessage = Encoding.UTF8.GetString(message);
return JsonConvert.DeserializeObject<TQueueMessage>(stringMessage);
}
}
The QueueConsumerRegistratorService is responsible for initating the handler logic and shutting down the application correctly. The implementation is built as a HostedService. A hosted service is part of the ASP.NET framework provides an interface to implement long-running background tasks that are started when an application starts and stopped when the application shuts down.
On startup the registrator Service creates a DI Scope for the QueueConsumerHandler and calls the registration function. Creating a new Scope will result in the consumer registration logic in the handler to occur on a dedicated Channel for incoming messages for that particular queue. On shutdown the service calls the cancels the consumer registration and disposes of the created scope, thereby closing the Channel.
internal class QueueConsumerRegistratorService<TMessageConsumer, TQueueMessage> : IHostedService where TMessageConsumer : IQueueConsumer<TQueueMessage> where TQueueMessage : class, IQueueMessage
{
private readonly ILogger<QueueConsumerRegistratorService<TMessageConsumer, TQueueMessage>> _logger;
private IQueueConsumerHandler<TMessageConsumer, TQueueMessage> _consumerHandler;
private readonly IServiceProvider _serviceProvider;
private IServiceScope _scope;
public QueueConsumerRegistratorService(ILogger<QueueConsumerRegistratorService<TMessageConsumer, TQueueMessage>> logger,
IServiceProvider serviceProvider)
{
_logger = logger;
_serviceProvider = serviceProvider;
}
public Task StartAsync(CancellationToken cancellationToken)
{
// Every registration of a IQueueConsumerHandler will have its own scope
// This will result in messages to the QueueConsumer will have their own incoming RabbitMQ channel
_scope = _serviceProvider.CreateScope();
_consumerHandler = _scope.ServiceProvider.GetRequiredService<IQueueConsumerHandler<TMessageConsumer, TQueueMessage>>();
_consumerHandler.RegisterQueueConsumer();
return Task.CompletedTask;
}
public Task StopAsync(CancellationToken cancellationToken)
{
_logger.LogInformation($"Stop {nameof(QueueConsumerRegistratorService<TMessageConsumer, TQueueMessage>)}: Canceling {typeof(TMessageConsumer).Name} as Consumer for Queue {typeof(TQueueMessage).Name}");
_consumerHandler.CancelQueueConsumer();
_scope.Dispose();
return Task.CompletedTask;
}
}
The last piece of the consumer implementation is the DI-registration. We decided on a ServiceCollection extension method that takes care of registering the Consumer implementation, Handler and Service for a particular queue message type.
public static void AddQueueMessageConsumer<TMessageConsumer, TQueueMessage>(this IServiceCollection services) where TMessageConsumer : IQueueConsumer<TQueueMessage> where TQueueMessage : class, IQueueMessage
{
services.AddScoped(typeof(TMessageConsumer));
services.AddScoped<IQueueConsumerHandler<TMessageConsumer, TQueueMessage>, QueueConsumerHandler<TMessageConsumer, TQueueMessage>>();
services.AddHostedService<QueueConsumerRegistratorService<TMessageConsumer, TQueueMessage>>();
}
• • •
Conclusion
The combination of the code snippets in this article result in a library that the developers can use to create RabbitMQ queue-based applications and features. It provides a few simple interfaces that can easily be implemented by development teams without concerning themselves with the details of the underlying queuing system. Our requirements of guaranteed delivery are met by making use of dead letter exchanges, quorum queues and transactions. And we leverage the power of the Dependency Injector (DI) in ASP.NET to manage the lifetime of resources like connections and channels.
If you want to use (part) of this implementation in your own project, the full library and an example implementation can be found on my GitLab account. In the next article in this series, we will dive into effectivly testing the integration a queuing system.