Два способа отправки данных по протоколу HTTP: в чем разница?
GraphQL часто представляют как революционно новый путь осмысления API. Вместо работы с жестко определенными на сервере конечными точками (endpoints) вы можете с помощью одного запроса получить именно те данные, которые вам нужны. И да — GraphQL гибок при внедрении в организации, он делает совместную работу команд frontend- и backend-разработки гладкой, как никогда раньше. Однако на практике обе эти технологии подразумевают отправку HTTP-запроса и получение какого-то результата, и внутри GraphQL встроено множество элементов из модели REST.
Так в чем же на самом деле разница на техническом уровне? В чем сходства и различия между этими двумя парадигмами API? К концу статьи я покажу вам, что GraphQL и REST отличаются не так уж сильно, но у GraphQL есть небольшие отличия, которые существенно меняют процесс построения и использования API разработчиками.
Так что давайте сразу к делу. Мы определим некоторые свойства API, а затем обсудим, как они реализованы в GraphQL и REST.
Ресурсы
Ключевое для REST понятие — ресурс. Каждый ресурс идентифицируется по его URL, и для получения ресурса надо отправить GET-запрос к этому URL. Скорее всего, ответ придет в формате JSON, так как именно этот формат используется сейчас в большинстве API. Выглядит это примерно так:
GET /books/1
{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
"lastName": "Левин"
}
// ... другие поля
}
Замечание: для рассмотренного выше примера некоторые REST API могут возвращать данные об авторе (поле «author») как отдельный ресурс.
Одна из заметных особенностей REST состоит в том, что тип, или форма ресурса, и способ получения ресурса сцеплены воедино. Говоря о рассмотренном выше примере в документации по REST API, вы можете сослаться на него как на «book endpoint».
GraphQL весьма отличается в этом аспекте, потому что в GraphQL эти два понятия полностью отделены друг от друга. В вашей схеме может быть два типа, Book и Author:
type Book {
id: ID
title: String
published: Date
price: String
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
books: [Book]
}
Заметьте: мы описали типы доступных нам данных, но это описание совершенно ничего не говорит вам о том, как эти объекты могут быть извлечены клиентом. Это одно из ключевых различий между REST и GraphQL : описание отдельного ресурса не связано со способом его получения.
Чтобы действительно получить доступ к отдельно взятой книге или автору, нам понадобится создать тип Query в нашей схеме:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
Теперь мы можем отправить запрос, аналогичный REST-запросу, рассмотренному выше, но на этот раз с помощью GraphQL:
GET /graphql?query={ book(id: "1") { title, author { firstName } } }
{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
}
}
Отлично, это уже что-то! Мы немедленно видим несколько особенностей GraphQL, весьма отличающих его от REST, даже несмотря на то, что оба они могут быть запрошены через URL, и оба могут вернуть одну и ту же форму JSON-ответа.
Прежде всего, мы видим, что в GraphQL-запросе URL содержит как нужный нам ресурс, так и описание интересующих нас полей. Кроме того, уже не разработчик сервера решает за нас, что нужно включить в ответ связанный ресурс author, — это теперь решение клиента, использующего API.
Но, что более важно, сущности ресурсов, понятия Books и Authors, не привязаны к способу их извлечения. Мы могли бы извечь одну и ту же книгу с помощью запросов различного типа и с различным набором полей.
Выводы
Мы уже обнаружили некоторые сходства и различия:
- Сходство: есть понятие ресурса, есть возможность назначать идентификаторы для ресурсов.
- Сходство: ресурсы могут быть извлечены с помощью GET-запроса URL-адреса по HTTP.
- Сходство: ответ на запрос может возвращать данные в формате JSON.
- Различие: в REST вызываемая вами конечная точка (endpoint) — это и есть сущность объекта. В GraphQL сущность объекта отделена от того, как именно вы его получаете.
- Различие: в REST структура и объем ресурса определяются сервером. В GraphQL сервер определяет набор доступных ресурсов, а клиент указывает необходимые ему данные прямо в запросе.
Если вы уже использовали GraphQL и/или REST, пока все было довольно просто. Если раньше вы не использовали GraphQL, можете поиграть на Launchpad с примером, подобным приведенному выше.
URL-маршруты и схемы GraphQL
API бесполезен, если он непредсказуем. Когда вы используете API, вы обычно делаете это в рамках какой-то программы, и этой программе нужно знать, что она может вызвать и что ей ожидать в качестве результата такого вызова, чтобы этот результат мог быть обработан программой.
Итак, одна из важнейших частей API — это описание того, к чему возможен доступ. Это как раз то, что вы изучаете, читая документацию по API, а с помощью GraphQL-интроспекции или систем поддержки схем REST API вроде Swagger эта информация может быть получена прямо из программы.
В существующих сегодня REST API чаще всего API описывается как список конечных точек (endpoints):
GET /books/:id
GET /authors/:id
GET /books/:id/comments
POST /books/:id/comments
Можно сказать, что «форма» API линейна — это просто список доступных вам вещей. При извлечении данных или сохранении какой-либо информации первый вопрос, который вы задаете себе: «Какой endpoint мне следует вызвать»?
В GraphQL, как мы разобрались ранее, вы не используете URL-адреса для идентификации того, что вам доступно в API. Вместо этого вы используете GraphQL-схему:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
type Mutation {
addComment(input: AddCommentInput): Comment
}
type Book { ... }
type Author { ... }
type Comment { ... }
input AddCommentInput { ... }
Здесь есть несколько интересных особенностей по сравнению с маршрутами REST для аналогичного набора данных. Первое: вместо выполнения HTTP-запросов одного и того же URL-адреса с помощью разных методов (GET, PUT, DELETE и т.п.) GraphQL использует для различения чтения и записи разный начальный тип — Mutation или Query. В GraphQL-документе вы можете выбрать, какой тип операции вы отправляете, с помощью соответствующего ключевого слова:
query { ... }
mutation { ... }
Более детально язык запросов разбирается в более ранней моей статье «Анатомия запросов GraphQL» (англ.), перевод на Хабрахабре.
Как видите, поля типа Query довольно хорошо совпадают с маршрутами REST, рассмотренными выше. Это потому, что данный специальный тип является входной точкой для доступа к нашим данным, так что в GraphQL это наиболее близкий эквивалент понятию «URL конечной точки (endpoint URL)».
Способ получения начального ресурса от GraphQL API довольно похож на то, как это делается в REST: вы передаете имя и некоторые параметры; но главное отличие здесь в том, куда вы сможете двинуться после этого. В GraphQL вы можете отправить сложный запрос, который извлечет дополнительные данные согласно связям, определенным в схеме, а в REST вам для этого пришлось бы сделать несколько запросов, встроить связанные данные в начальный запрос, или же включить какие-то особые параметры в URL-запрос для модификации ответа.
Выводы
В REST пространство доступных данных описывается как линейный список конечных точек (endpoints), а в GraphQL это схема со связями между ее элементами.
- Сходство: список конечных точек в REST API похож на список полей в типах Query и Mutation, используемых в GraphQL API. Оба они являются точками входа для доступа к данным.
- Сходство: есть возможность различать запросы к API на чтение и на запись данных.
- Различие: в GraphQL вы можете внутри одиночного запроса перемещаться от точки входа к связанным данным, следуя связям, определенным в схеме. В REST для получения связанных ресурсов вам придется выполнить запросы к нескольким конечным точкам.
- Различие: в GraphQL нет разницы между полями типа Query и полями любого другого типа, за исключением того, что в корне запроса доступен только тип query. Например, у вас в запросе любое поле может иметь аргументы. В REST не существует понятия первого класса в случае вложенного URL.
- Различие: в REST вы определяете запись данных, меняя HTTP-метод запроса с GET на что-то вроде POST. В GraphQL вы меняете ключевое слово в запросе.
Из-за первого пункта в списке сходств, указанных выше, люди часто начинают воспринимать поля типа Query как «конечные точки» или «запросы» GraphQL. Хотя такое сравнение и имеет определенный смысл, оно может привести к искаженному восприятию, будто тип Query работает совершенно иначе, чем другие типы, а это совсем не так.
Обработчики маршрутов и распознаватели
Итак, что происходит, когда вы вызываете API? Ну, обычно при этом на сервере выполняется какой-то код, получивший ваш запрос. Этот код может выполнять расчеты, загружать данные из базы, вызывать другой API, и вообще делать все, что угодно. Весь смысл в том, что вам снаружи нет необходимости знать, что именно делает этот код. Но и в REST, и в GraphQL есть стандартные способы реализации внутренней части API, и будет полезно сравнить их для понимания того, насколько различны эти технологии.
В этом сравнении я буду использовать код на JavaScript, потому что я знаю этот язык лучше всего, но вы, конечно же, можете использовать практически любой язык программирования для реализации и REST, и GraphQL API. Я также пропущу все подготовительные этапы, требуемые для поднятия и запуска сервера, потому что это не важно для рассматриваемых вопросов.
Рассмотрим пример реализации «Hello World» с помощью express, популярного фреймворка для построения API на Node:
app.get('/hello', function (req, res) {
res.send('Hello World!')
})
Как видите, мы создали конечную точку /hello, которая возвращает строку 'Hello World!'. Из этого примера становится понятен жизненный цикл HTTP-запроса на сервере REST API:
- Сервер получает запрос и извлекает HTTP-метод (в нашем случае GET) и путь URL
- API-фреймворк сопоставляет метод и путь с функцией, зарегистрированной в серверном коде
- Функция выполняется один раз и возвращает результат
- API-фреймворк преобразует результат, добавляет соответствующие код и заголовки ответа и отправляет все это обратно клиенту
GraphQL работает очень похожим способом, и для того же примера код практически тот же самый:
const resolvers = {
Query: {
hello: () => {
return 'Hello world!';
},
},
};
Как видите, вместо предоставления функции для выбранного URL мы указываем функцию, которая сопоставляет отдельное поле типу, в нашем случае — поле hello типу Query. В GraphQL функция, реализующая такое сопоставление, называется распознавателем (resolver).
Чтобы получить данные, нам нужен запрос (query):
query {
hello
}
Итак, что происходит, когда наш сервер получает GraphQL-запрос:
- Сервер получает HTTP-запрос и извлекает из него GraphQL-запрос
- Запрос (query) проходится насквозь, и для каждого поля вызывается соответствующий распознаватель (resolver). В нашем случае поле всего одно, hello, и ему соответствует тип Query.
- Функция вызывается и возвращает результат
- Библиотека GraphQL и сервер прикрепляют полученный результат к ответу, который соответствует форме запроса (query)
Вы получаете от сервера ответ:
{ "hello": "Hello, world!" }
Но есть один трюк: мы можем вызвать одно поле дважды!
query {
hello
secondHello: hello
}
В этом случае цикл обработки тот же, но так как мы запросили одно и то же поле дважды (используя псевдоним), распознаватель hello на самом деле будет вызван дважды. Пример соврешенно надуманный, но смысл в том, что множество полей могут выполняться в рамках одного запроса, а одно и то же поле может вызываться множество раз в разных местах запроса.
Объяснение не было бы полным без примера с вложенными распознавателями («nested» resolvers):
{
Query: {
author: (root, { id }) => find(authors, { id: id }),
},
Author: {
posts: (author) => filter(posts, { authorId: author.id }),
},
}
Эти распознаватели способны разрешить запрос вроде такого:
query {
author(id: 1) {
firstName
posts {
title
}
}
}
Итак, хотя список распознавателей на самом деле плоский, из-за прикрепления их к различным типам вы можете построить из них вложенные запросы. Подробнее о том, как работает выполнение GraphQL, читайте в статье «GraphQL Explained».
Можете посмотреть полный пример и протестировать его, запуская разные запросы!
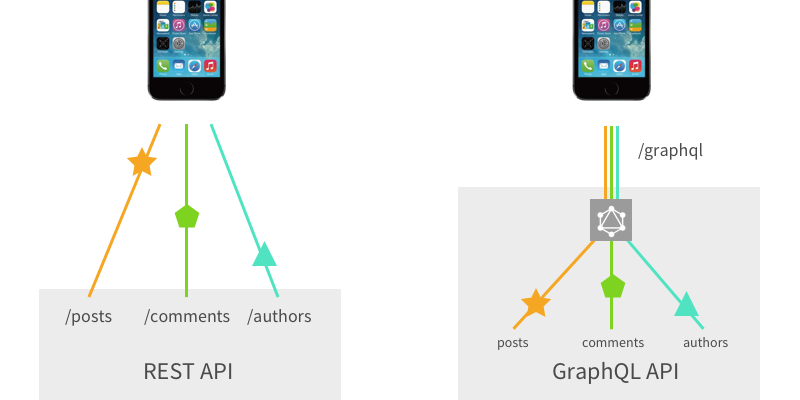
Художественная интерпретация извлечения ресурсов: в REST множество данных гоняются туда и обратно, в GraphQL все делается одним-единственным запросом.
Выводы
На настоящий момент как REST, так и GraphQL API являются лишь причудливыми способами вызывать функции по сети. Если вам знакомо построение REST API, реализация GraphQL API не будет особо отличаться. Однако GraphQL имеет большое преимущество: возможность вызова нескольких взаимосвязанных функций в рамках одного запроса.
- Сходство: конечные точки в REST и поля в GraphQL в конечном итоге вызывают функции на сервере.
- Сходство: как REST, так и GraphQL обычно полагаются на фрейморки и библиотеки в части рутинной работы по организации сетевого взаимодействия.
- Различие: в REST каждый запрос обычно вызывает ровно одну функцию-обработчик маршрута. В GraphQL один запрос может вызвать множество функций-распознавателей для построения сложного ответа с множеством вложенных ресурсов.
- Различие: в REST вы строите форму ответа самостоятельно. В GraphQL форма ответа определяется библиотекой, выполняющей GraphQL, для сопоставления форме запроса.
По сути, вы можете думать о GraphQL как о системе для вызова множества вложенных конечных точек в одном запросе. Почти как мультиплексированный REST.
Что все это значит?
Есть множество тем, на которые в данной статье не хватило места. Например, идентификация объектов, гипермедиа или кэширование. Возможно, это станет темой одной из следующих статей. Я надеюсь, теперь вы согласитесь, что если взглянуть на основные принципы, то окажется, что REST и GraphQL работают с понятиями, которые принципиально очень похожи.
Я думаю, некоторые из различий говорят в пользу GraphQL. В частности, мне кажется, действительно здорово иметь возможность реализовать свой API как набор небольших функций-распознавателей, а затем отправлять сложные запросы, которые предсказуемым способом извлекают множество ресурсов за один раз. Это ограждает разработчика API от необходимости создавать множество конечных точек с различной формой, а клиенту API позволяет избежать извлечения лишних данных, которые ему не нужны.
С другой стороны, для GraphQL пока нет такого множества инструментов и решений по интеграции, как для REST. Например, у вас не получится с помощью HTTP-кэширования кэшировать результаты работы GraphQL API так же легко, как это делается для результатов работы REST API. Однако сообщество упорно работает над улучшением инструментов и инфраструктуры, а для кэширования GraphQL вы можете использовать такие инструменты, как Apollo Client и Relay.