A large language model is a type of artificial intelligence algorithm that uses deep learning techniques and massively large data sets to understand, summarize, generate and predict new content. The term generative AI also is closely connected with LLMs, which are, in fact, a type of generative AI that has been specifically architected to help generate text-based content.
Over millennia, humans developed spoken languages to communicate. Language is at the core of all forms of human and technological communications; it provides the words, semantics and grammar needed to convey ideas and concepts. In the AI world, a language model serves a similar purpose, providing a basis to communicate and generate new concepts.
The first AI language models trace their roots to the earliest days of AI. The Eliza language model debuted in 1966 at MIT and is one of the earliest examples of an AI language model. All language models are first trained on a set of data, then make use of various techniques to infer relationships before ultimately generating new content based on the trained data. Language models are commonly used in natural language processing (NLP) applications where a user inputs a query in natural language to generate a result.
An LLM is the evolution of the language model concept in AI that dramatically expands the data used for training and inference. In turn, it provides a massive increase in the capabilities of the AI model. While there isn't a universally accepted figure for how large the data set for training needs to be, an LLM typically has at least one billion or more parameters. Parameters are a machine learning term for the variables present in the model on which it was trained that can be used to infer new content.
Modern LLMs emerged in 2017 and use transformer models, which are neural networks commonly referred to as transformers. With a large number of parameters and the transformer model, LLMs are able to understand and generate accurate responses rapidly, which makes the AI technology broadly applicable across many different domains.
Some LLMs are referred to as foundation models, a term coined by the Stanford Institute for Human-Centered Artificial Intelligence in 2021. A foundation model is so large and impactful that it serves as the foundation for further optimizations and specific use cases.
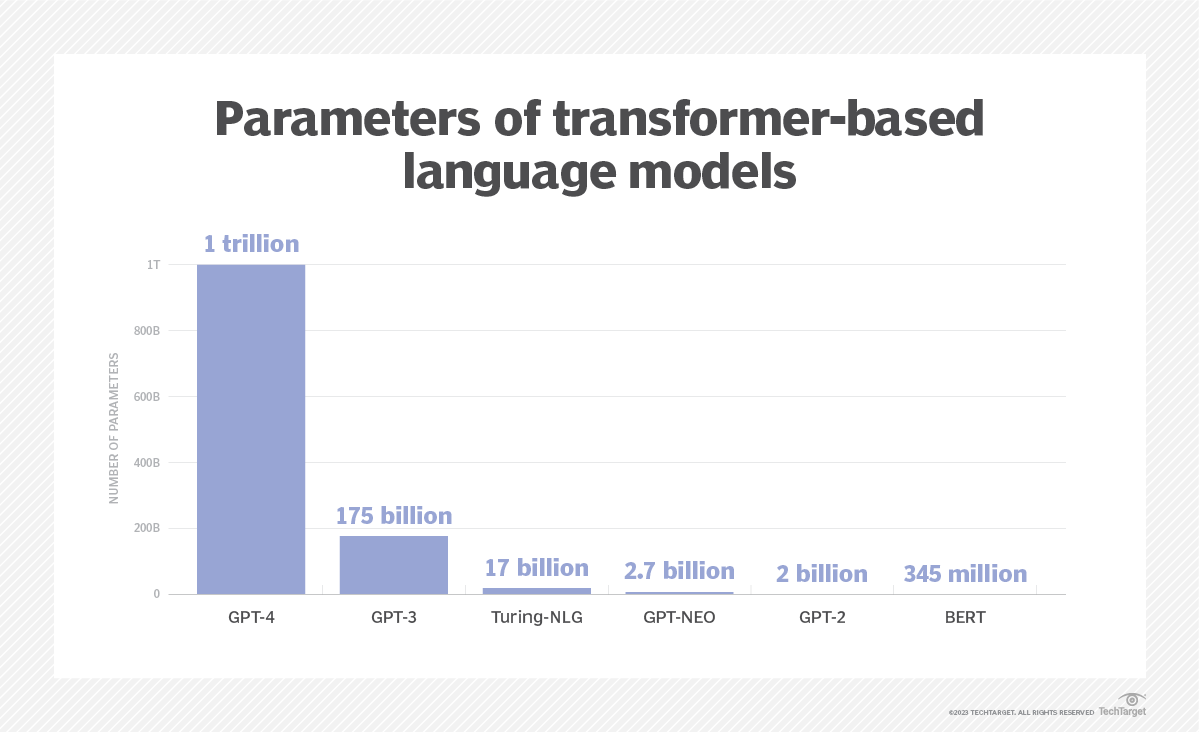
GPT-4, an LLM, dwarfs all predecessors in terms of its parameter count.
Examples of LLMs
Here is a list of the top 10 LLMs on the market, listed in alphabetical order based on internet research:
- Bidirectional Encoder Representations from Transformers, commonly referred to as Bert.
- Claude.
- Cohere.
- Enhanced Representation through Knowledge Integration, or Ernie.
- Falcon 40B.
- Galactica.
- Generative Pre-trained Transformer 3, commonly known as GPT-3.
- GPT-3.5.
- GPT-4.
- Language Model for Dialogue Applications, or Lamda.
Why are LLMs becoming important to businesses?
As AI continues to grow, its place in the business setting becomes increasingly dominant. This is shown through the use of LLMs as well as machine learning tools. In the process of composing and applying machine learning models, research advises that simplicity and consistency should be among the main goals. Identifying the issues that must be solved is also essential, as is comprehending historical data and ensuring accuracy.
The benefits associated with machine learning are often grouped into four categories: efficiency, effectiveness, experience and business evolution. As these continue to emerge, businesses invest in this technology.
How do large language models work?
LLMs take a complex approach that involves multiple components.
At the foundational layer, an LLM needs to be trained on a large volume -- sometimes referred to as a corpus -- of data that is typically petabytes in size. The training can take multiple steps, usually starting with an unsupervised learning approach. In that approach, the model is trained on unstructured data and unlabeled data. The benefit of training on unlabeled data is that there is often vastly more data available. At this stage, the model begins to derive relationships between different words and concepts.
The next step for some LLMs is training and fine-tuning with a form of self-supervised learning. Here, some data labeling has occurred, assisting the model to more accurately identify different concepts.
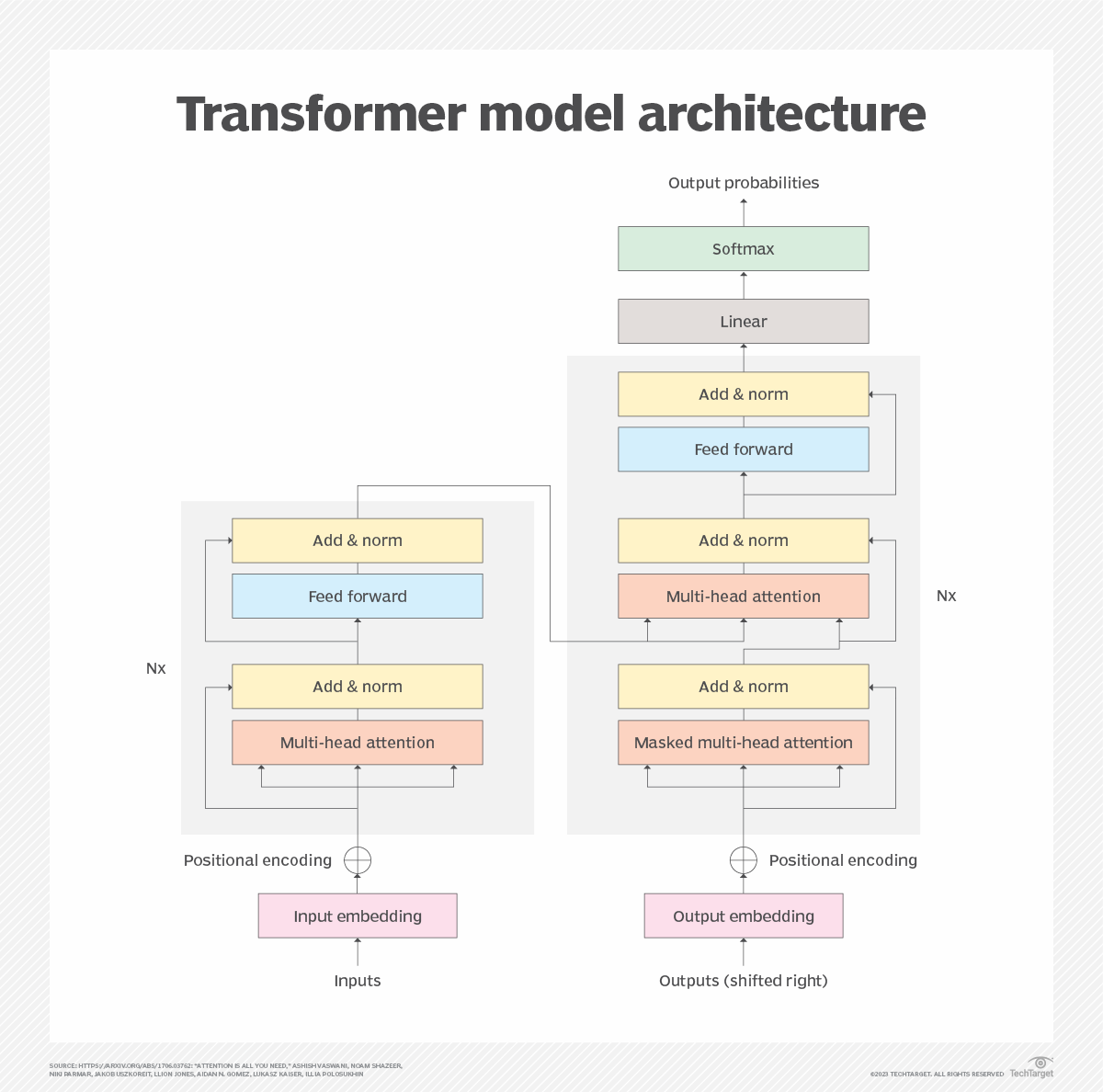
Next, the LLM undertakes deep learning as it goes through the transformer neural network process. The transformer model architecture enables the LLM to understand and recognize the relationships and connections between words and concepts using a self-attention mechanism. That mechanism is able to assign a score, commonly referred to as a weight, to a given item -- called a token -- in order to determine the relationship.
Once an LLM has been trained, a base exists on which the AI can be used for practical purposes. By querying the LLM with a prompt, the AI model inference can generate a response, which could be an answer to a question, newly generated text, summarized text or a sentiment analysis report.
What are large language models used for?
LLMs have become increasingly popular because they have broad applicability for a range of NLP tasks, including the following:
- Text generation. The ability to generate text on any topic that the LLM has been trained on is a primary use case.
- Translation. For LLMs trained on multiple languages, the ability to translate from one language to another is a common feature.
- Content summary. Summarizing blocks or multiple pages of text is a useful function of LLMs.
- Rewriting content. Rewriting a section of text is another capability.
- Classification and categorization. An LLM is able to classify and categorize content.
- Sentiment analysis. Most LLMs can be used for sentiment analysis to help users to better understand the intent of a piece of content or a particular response.
- Conversational AI and chatbots. LLMs can enable a conversation with a user in a way that is typically more natural than older generations of AI technologies.
Among the most common uses for conversational AI is through a chatbot, which can exist in any number of different forms where a user interacts in a query-and-response model. The most widely used LLM-based AI chatbot is ChatGPT, which is developed by OpenAI. ChatGPT currently is based on the GPT-3.5 model, although paying subscribers can use the newer GPT-4 LLM.
What are the advantages of large language models?
There are numerous advantages that LLMs provide to organizations and users:
- Extensibility and adaptability. LLMs can serve as a foundation for customized use cases. Additional training on top of an LLM can create a finely tuned model for an organization's specific needs.
- Flexibility. One LLM can be used for many different tasks and deployments across organizations, users and applications.
- Performance. Modern LLMs are typically high-performing, with the ability to generate rapid, low-latency responses.
- Accuracy. As the number of parameters and the volume of trained data grow in an LLM, the transformer model is able to deliver increasing levels of accuracy.
- Ease of training. Many LLMs are trained on unlabeled data, which helps to accelerate the training process.
- Efficiency. LLMs can save employees time by automating routine tasks.
What are the challenges and limitations of large language models?
While there are many advantages to using LLMs, there are also several challenges and limitations:
- Development costs. To run, LLMs generally require large quantities of expensive graphics processing unit hardware and massive data sets.
- Operational costs. After the training and development period, the cost of operating an LLM for the host organization can be very high.
- Bias. A risk with any AI trained on unlabeled data is bias, as it's not always clear that known bias has been removed.
- Ethical concerns. LLMs can have issues around data privacy and create harmful content.
- Explainability. The ability to explain how an LLM was able to generate a specific result is not easy or obvious for users.
- Hallucination. AI hallucination occurs when an LLM provides an inaccurate response that is not based on trained data.
- Complexity. With billions of parameters, modern LLMs are exceptionally complicated technologies that can be particularly complex to troubleshoot.
- Glitch tokens. Maliciously designed prompts that cause an LLM to malfunction, known as glitch tokens, are part of an emerging trend since 2022.
- Security risks. LLMs can be used to improve phishing attacks on employees.
What are the different types of large language models?
There is an evolving set of terms to describe the different types of large language models. Among the common types are the following:
- Zero-shot model. This is a large, generalized model trained on a generic corpus of data that is able to give a fairly accurate result for general use cases, without the need for additional training. GPT-3 is often considered a zero-shot model.
- Fine-tuned or domain-specific models. Additional training on top of a zero-shot model such as GPT-3 can lead to a fine-tuned, domain-specific model. One example is OpenAI Codex, a domain-specific LLM for programming based on GPT-3.
- Language representation model. One example of a language representation model is Google's Bert, which makes use of deep learning and transformers well suited for NLP.
- Multimodal model. Originally LLMs were specifically tuned just for text, but with the multimodal approach it is possible to handle both text and images. GPT-4 is an example of this type of model.
The future of large language models
The future of LLMs is still being written by the humans who are developing the technology, though there could be a future in which the LLMs write themselves, too. The next generation of LLMs will not likely be artificial general intelligence or sentient in any sense of the word, but they will continuously improve and get "smarter."
LLMs will also continue to expand in terms of the business applications they can handle. Their ability to translate content across different contexts will grow further, likely making them more usable by business users with different levels of technical expertise.
LLMs will continue to be trained on ever larger sets of data, and that data will increasingly be better filtered for accuracy and potential bias, partly through the addition of fact-checking capabilities. It's also likely that LLMs of the future will do a better job than the current generation when it comes to providing attribution and better explanations for how a given result was generated.
Enabling more accurate information through domain-specific LLMs developed for individual industries or functions is another possible direction for the future of large language models. Expanded use of techniques such as reinforcement learning from human feedback, which OpenAI uses to train ChatGPT, could help improve the accuracy of LLMs too. There's also a class of LLMs based on the concept known as retrieval-augmented generation — including Google's Realm, which is short for Retrieval-Augmented Language Model — that will enable training and inference on a very specific corpus of data, much like how a user today can specifically search content on a single site.
There's also ongoing work to optimize the overall size and training time required for LLMs, including development of Meta's Llama model. Llama 2, which was released in July 2023, has less than half the parameters than GPT-3 has and a fraction of the number GPT-4 contains, though its backers claim it can be more accurate.
On the other hand, the use of large language models could drive new instances of shadow IT in organizations. CIOs will need to implement usage guardrails and provide training to avoid data privacy problems and other issues. LLMs could also create new cybersecurity challenges by enabling attackers to write more persuasive and realistic phishing emails or other malicious communications.
Nonetheless, the future of LLMs will likely remain bright as the technology continues to evolve in ways that help improve human productivity.