Whether you’ve worked on a large or a small project, throughout your career, someone has initiated an architecture pattern on the project you’re working on; more often than not, it’s you on small personal projects, but you’re not aware you’re using one.
In this article, we’ll endeavour to discuss what software architecture patterns are and, importantly, the most common ones.
Content index
- Layered Pattern (aka N-Tier Architecture)
- Client-Server Pattern
- Microservice Architecture
- Event Driven Architecture (Event Driven Design & Message Driven Design)
- Model-View-Controller (MVC)
- Service-Oriented Architecture (SOA)
- Repository Pattern
- CQRS (Command Query Responsibility Segregation)
- Domain-Driven Design (DDD)
- Pipes and Filters Pattern
What is Software Architecture?
Software architecture represents the overarching plan for a software system, outlining its primary structure, elements, connections, and principles directing its design and development. This foundation supports system design, streamlines communication between stakeholders, aids in decision-making, and guarantees important quality characteristics such as scalability, maintainability and efficiency.
The simplest way of thinking about this is to imagine your software is a finished Lego building. Blocks can come in various shapes and colours, but ultimately, it’s how you place the pieces that give shape to the building; how you place the blogs are integral to the structure and ultimate stability of the building.
1 — Layered Pattern (aka N-Tier Architecture)
Layered Architecture (N-Tier Architecture) is a software design pattern that organizes an application into horizontal layers or tiers. Each layer has a specific responsibility and encapsulates a certain level of functionality, promoting separation of concerns, modularity, and maintainability.
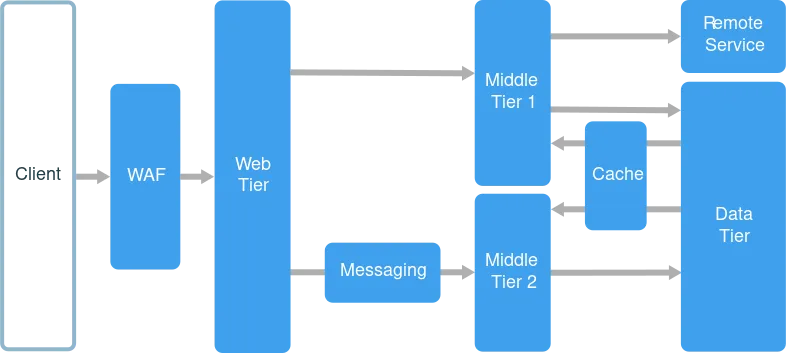
The number of layers in the system can vary depending on the application requirements. Common layers in layered architecture include:
- Presentation Layer: Also known as the user interface layer, this layer is responsible for displaying data and accepting user input. It is the layer that interacts directly with the end users.
- Application Layer: This layer manages the business logic, workflows, and application-specific functionality. It processes user requests, coordinates with other layers, and enforces business rules.
- Domain/Business Logic Layer: This layer contains the core business entities, their relationships, and the rules governing them. It represents the underlying business domain and encapsulates the system’s main functionality.
- Data Access Layer: This layer handles communication with data storage systems, such as databases or external APIs, providing a level of abstraction to isolate the rest of the application from the specifics of data storage and retrieval.
In a Layered Architecture, each layer communicates only with its neighbouring layers. This structure allows for easier maintenance and scaling, as changes in one layer have minimal impact on the other. By following the layered pattern, developers can create modular and flexible applications that are easier to understand, test and evolve.
Pros of Layered Architecture:
- Separation Of Concerns: By dividing the application into distinct layers, each handling a specific aspect of functionality, the architecture promotes modularity and separation of concerns, making the system easier to understand and maintain.
- Reusability: The clear separation of responsibilities in different layers facilitates reusing components and logic across various application parts or other projects.
- Maintainability: With a well-defined structure and clear responsibilities for each layer, developers can easily maintain, debug, and extend the application over time.
- Testability: The modular nature of the architecture simplifies testing by allowing individual layers to be tested independently.
- Encapsulation: Each layer encapsulates its logic and complexity, hiding the implementation details from other layers and reducing the risk of unintended consequences when making changes.
- Flexibility: Abstracting functionality into separate layers makes it easier to replace or modify components without impacting the entire system.
Cons of Layered Architecture:
- Performance Overhead: The additional layers can introduce performance overhead due to increased complexity and the need for inter-layer communication.
- Increased Complexity: While separating concerns makes the system more maintainable, it may also increase overall complexity, particularly in systems with numerous layers.
- Rigidity: Layered architectures may impose rigid constraints on the system design, limiting developers’ ability to implement certain features or optimizations that span multiple layers.
- Potential For Misuse: If layers are not designed and implemented correctly, the architecture can become more challenging to maintain, or developers may be tempted to bypass layers to achieve the desired functionality, undermining the benefits of the pattern.
Ultimately, the pros and cons of layered architecture depend on the specific project and implementation. When used effectively, layered architectures can provide a strong foundation for building scalable, maintainable, and flexible software systems.
Scott Duffy explains this concept very concisely in this video.
2 — Client-Server Pattern
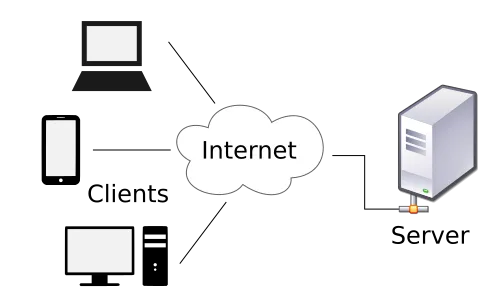
Client-Server architecture is a pattern where one or more clients interact with a centralized server, which provides resources, services and/or data to multiple clients.
For reference, clients refer to the frontend technology a customer/user can browse (mobile, desktop). Whereas a server refers to the technology that handles the logic between requests and talking to the database.
In this pattern, clients request services, and servers process and deliver the requests. This pattern gives the business efficient resource allocation, scalability and easier maintenance by separating responsibilities between clients and servers.
You might also recognize this pattern, as most architectural patterns employ this or a variation in their software design.
Pros of client-server architecture:
- Centralized Management: The server handles most data management tasks, allowing for easier administration, monitoring, and maintenance.
- Scalability: Adding new clients or upgrading server resources can accommodate growth in usage and demand.
- Improved Security: Centralizing data and services on the server allows for more robust security measures and more accessible updates.
- Resource Sharing: Multiple clients can access shared resources from a single server, such as databases or software applications.
- Efficiency: Workload distribution between clients and servers can optimize performance and reduce network congestion.
Cons of client-server architecture:
- Single Point Of Failure: If the server goes down, all connected clients lose access to resources and services.
- Network Dependency: Client-server communication relies on network connections, which can introduce latency or bottlenecks if not appropriately managed.
- Server Workload: The server handles many requests from multiple clients, which may require powerful hardware and can lead to performance degradation if not managed effectively.
- Complexity: Implementing, managing, and maintaining a client-server architecture can be complex and require specialized skills.
- Cost: Depending on the scale and needs of the system, the hardware, software, and maintenance costs associated with client-server architecture can be high.
Nick White (no affiliation) explains this concept excellently in this video.
3 — Microservice Architecture
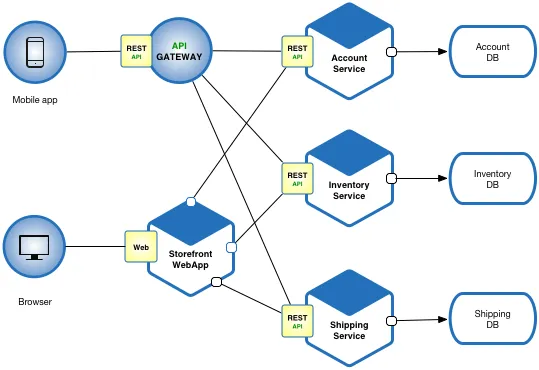
Microservice architecture is a software design system that breaks applications (client and/or server) into small, independent and modular components called microservices. Each microservice is responsible for specific functionality, runs its process and communicates with other services via API requests.
Microservice architecture is sometimes paired with ideas behind reductionism, where large complex ideas can be broken down into smaller parts. Each microservice's breakdown and often specific purpose enable flexibility, faster response times and scalability. Making it easier to develop, maintain and scale as your application gets more complex.
Pros of microservice architecture:
- Scalability: Microservices can be scaled independently, allowing for efficient resource allocation based on individual service requirements.
- Flexibility: Independent microservices can be developed, tested, and deployed using different programming languages, frameworks, and tools.
- Fault Tolerance: If a single microservice fails, it’s less likely to disrupt the entire system, as each service is isolated from the others.
- Easier Maintenance: Smaller codebases and clear separation of concerns simplify debugging, updates, and maintenance.
- Faster Development And Deployment: Development teams can work on individual microservices concurrently, speeding up the development process and allowing for continuous integration and deployment.
Cons of microservice architecture:
- Increased Complexity: Microservice architectures can become complex, with many services to manage, monitor, and maintain.
- Communication Overhead: Inter-service communication can introduce latency, as microservices rely on network calls and API interactions.
- Data Consistency: Ensuring data consistency across microservices can be challenging due to the distributed nature of the architecture.
- Deployment And Management: Orchestrating and managing many microservices may require additional tools and expertise.
- Security: The distributed nature of microservices can increase the attack surface, requiring more effort to implement robust security measures.
Nana from Techworld does a great job explaining this concept in this video.
4 — Event Driven Architecture (Event Driven Design & Message Driven Design)
Event-Driven Architecture uses events as a central instrument for communication between components. This is usually split into two design patterns, Event-Driven Design and Message Driven Design. It’s essential to look at both Event Driven Design and Message Driven Design separately.
Let’s start with Event-Driven Design. This pattern is where components communicate and react to events actioned by the event producer. An example could be a customer who has logged in to their order history pages and requires a list of their previous orders. This pattern listens for an event and then responds asynchronously.
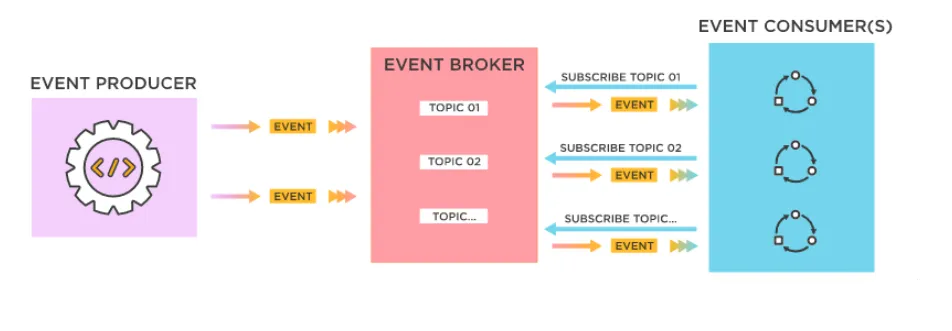
This design promotes loose coupling, improved scalability, and flexibility, as components can be added, removed, or modified independently without affecting the overall system functionality.
On the other hand, message-driven design is a design pattern where components communicate through asynchronous message-passing, often via message queues or brokers. In this pattern, event producers send messages containing data or instructions to an event broker queue, whilst event consumer consumers receive and process those messages served to it from the queue.
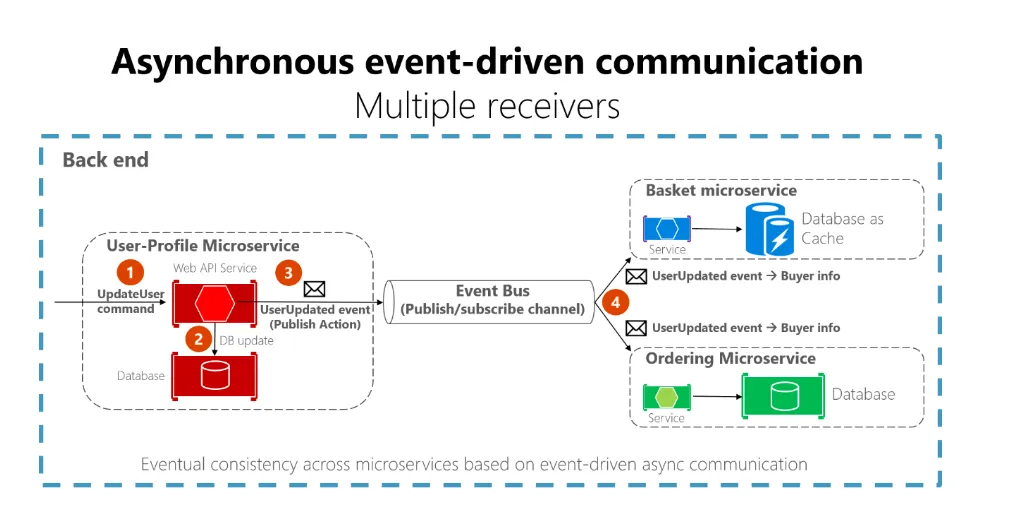
An example is a customer who has registered for our website; we don’t need to instantly send a welcome email to them as it doesn’t matter if it takes a few minutes, so this request is added to the event broker queue and actioned sometime in the future.
Message-driven architecture enhances system scalability, modularity, and fault tolerance by allowing components to operate independently and to be added, removed, or updated without impacting the overall system.
Pros of event-driven architecture:
- Scalability: Event-driven systems can quickly scale horizontally by adding more event consumers or producers, improving performance and load-handling capabilities.
- Loose Coupling: Components in event-driven architecture interact only through events, reducing dependencies and promoting modularity and flexibility.
- Asynchronous Processing: Components can process events independently and concurrently, enhancing system responsiveness and efficiency.
- Real-Time Responsiveness: EDA supports real-time event handling and notification, making it suitable for systems with high volumes of data and rapidly changing states.
- Easier Integration: EDA simplifies integration with other systems or applications, as components can listen for and respond to events from different sources.
Cons of event-driven architecture:
- Complexity: Managing, monitoring, and debugging event-driven systems can be complex, as the flow of events might not be as explicit as traditional request-response architectures.
- Event Ordering: Ensuring correct event ordering can be challenging in distributed environments or high-latency systems, potentially causing processing issues or inconsistencies.
- Data Consistency: Ensuring data consistency across components may require implementing additional strategies, such as eventual consistency or compensating transactions.
- Messaging Overhead: Event-driven systems may introduce additional overhead regarding message processing, serialization, and transmission.
- Testing And Validation: Testing and validating event-driven architectures can be more complex due to the asynchronous and distributed nature of the components.
A Dev’s Story has done a fantastic video covering this topic, including other architecture videos on his channel.
5 — Model-View-Controller (MVC)
The Model View Controller pattern separates data management (Model), user interface (View) and control flow (Controller). This separation of concerns promotes modularity, maintainability, and easier testing by allowing components to be developed and updated independently.
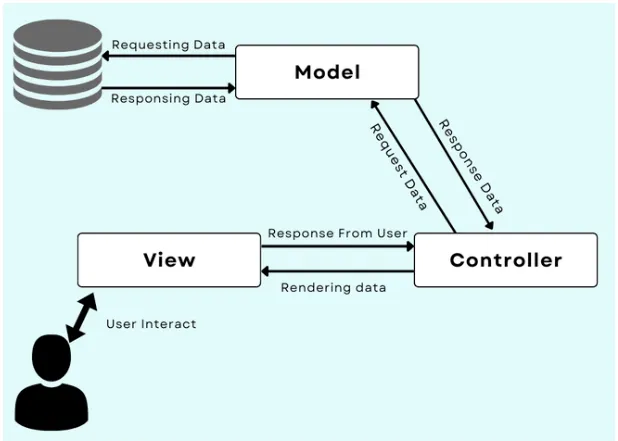
Pros of MVC architecture:
- Separation Of Concerns: The distinct roles of Model, View, and Controller enhance modularity, making the code easier to understand, maintain, and extend.
- Reusability: Components in MVC architecture can be reused, reducing development time and promoting consistency.
- Easier Testing: Separating the application logic into different components allows for more straightforward unit testing and debugging.
- Parallel Development: Different development teams can work on the Model, View, and Controller components simultaneously, accelerating the development process.
- Flexible UI Updates: Changes to the View can be made independently of the Model and Controller, simplifying UI updates without impacting the underlying application logic.
Cons of MVC architecture:
- Complexity: Implementing MVC architecture can introduce complexity, particularly for small applications where the added structure might not be necessary.
- Learning Curve: Developers unfamiliar with MVC may need time to understand the architecture and its components.
- Potential Performance Overhead: The additional layers of abstraction in MVC can sometimes introduce performance overhead.
- Inefficient Data Flow: In some scenarios, the strict separation of components might result in inefficient data flow or communication between the Model, View, and Controller.
- Framework Dependence: When using specific MVC frameworks, developers may become dependent on their design choices, potentially limiting flexibility in implementing custom solutions.
Web Dev Simplified did a smashing job succinctly explaining this topic in this video.
6 — Service-Oriented Architecture (SOA)
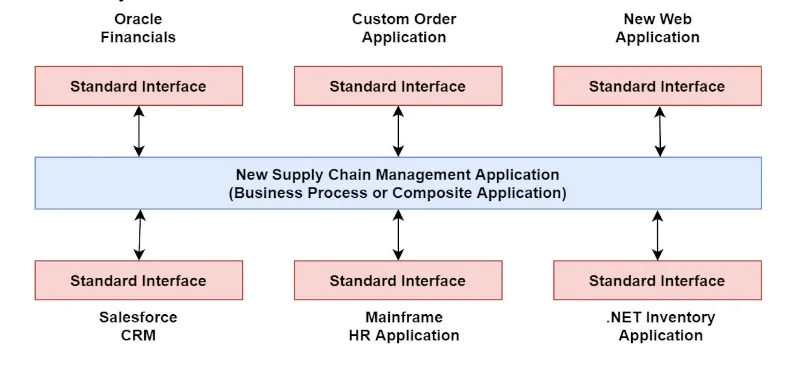
Service-oriented architecture organises applications as a collection of modular, loosely-coupled services that communicate using standard protocols. Each service is self-contained, performs specific functionality and exposes an interface for interaction. Service-Oriented architecture allows the development, deployment and updating of services independently without impacting the overall design, promoting reusability, flexibility and maintainability.
Pros of Service-Oriented Architecture (SOA):
- Reusability: Services can be reused across multiple applications, reducing development time and promoting consistency.
- Flexibility: SOA allows for independent development and updates of services without affecting the entire system, enabling more effortless adaptability to changing business requirements.
- Maintainability: The modular nature of SOA simplifies maintenance, as services can be modified or replaced individually without impacting other components.
- Scalability: Services can be scaled independently to accommodate changing loads, enhancing the system’s overall performance.
- Interoperability: SOA supports standard communication protocols and interfaces, enabling seamless integration of services developed using different technologies or platforms.
Cons of Service-Oriented Architecture (SOA):
- Complexity: Implementing and managing SOA can be complex, especially when dealing with many services and their interactions.
- Performance Overhead: Communication between services through standard protocols and message formats may introduce performance overhead and latency.
- Security: Ensuring secure communication between services can be challenging due to the distributed nature of SOA, requiring additional measures such as authentication and encryption.
- Governance: Proper management and governance of services, including versioning, monitoring, and policy enforcement, are critical to ensure a well-functioning SOA system, which may require specialized tools or expertise.
- Initial Development Cost: Establishing a robust SOA infrastructure may involve higher upfront costs in development, planning, and tooling. However, these costs can be offset by the long-term benefits of SOA, such as reusability and easier maintenance.
Here’s a really clear video that explains this concept further.
7 — Repository Pattern
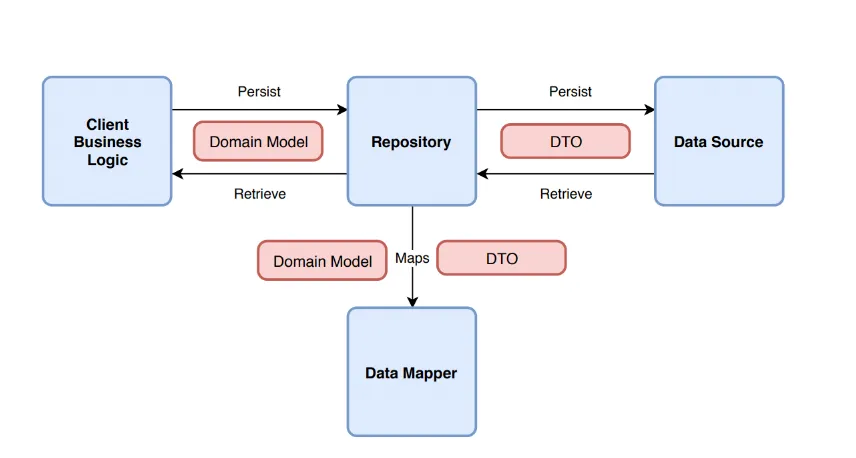
The Repository Pattern provides an abstraction layer between data access logic and the rest of the underlying application. This acts as a bridge between the domain and data mapping layers. Succinctly, this pattern separates data storage and data access by providing a central repository that handles the storage, retrieval, and querying of data.
Repositories encapsulate data retrieval and storage, offering a standardised interface for performing CRUD (Create, Read, Update, Delete) operations. This pattern promotes separation of concerns, maintainability and easier testing by decoupling data access from the underlying data source and allowing for centralized control over data management.
Pros of the Repository pattern:
- Separation Of Concerns: The Repository pattern decouples data access logic from the rest of the application, promoting modularity and maintainability.
- Abstraction: By providing a consistent interface for data access, the pattern enables easy swapping of data sources or storage implementations without affecting the application logic.
- Centralized Data Management: Repositories are a central point for data access, simplifying data management and improving code readability.
- Easier Testing: The pattern allows for creating mock repositories or dependency injection, facilitating unit testing and improving testability.
- Code Reusability: Repositories can be reused across multiple applications or components, reducing redundancy and promoting consistency in data access.
Cons of the Repository pattern:
- Implementing the Repository pattern can add complexity to the application, particularly for small projects requiring a more straightforward data access approach.
- Performance Overhead: The additional abstraction layer introduced by the pattern can result in performance overhead, especially if not optimized properly.
- Learning Curve: Developers unfamiliar with the Repository pattern may need time to understand its principles and implementation.
- Over-Engineering: Applying the pattern to simple projects or where it is not required might lead to unnecessary overhead and complexity.
- Generic Interfaces: Sometimes, repositories with generic interfaces might not cater to specific use cases or requirements, necessitating customization or additional layers of abstraction.
Coding Concepts did a well in-depth video on this topic.
8 — CQRS (Command Query Responsibility Segregation)
CQRS (Command Query Responsibility Segregation) architecture is a software design pattern that separates read and write operations into defined models (components) with different interfaces for handling commands (write operations) and queries (read operations). Utilising this segregation enabled more optimised processing, storage and scaling for different operation types. Thus, improving overall performance, maintainability and flexibility in complex applications. CQRS is often used with Event Sourcing and other architectural patterns to build responsive and scalable systems.
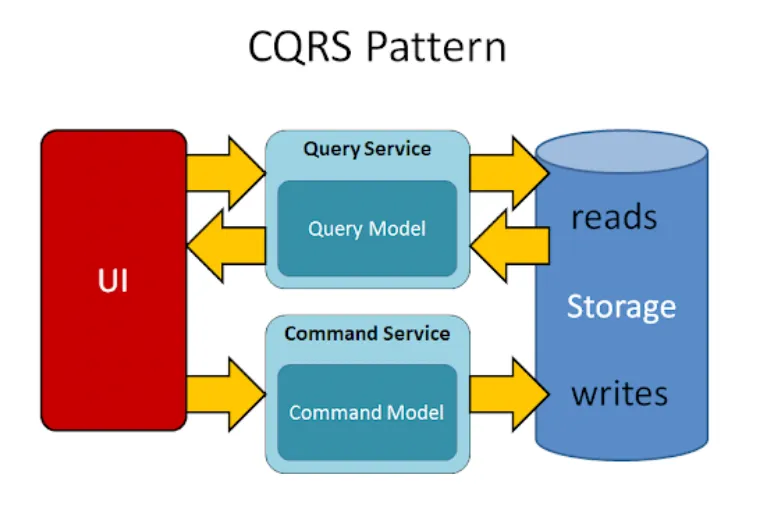
Pros of CQRS:
- Separation Of Concerns: CQRS enforces a clear separation between read and writes operations, leading to a cleaner and more modular architecture. This can improve the maintainability of the system.
- Scalability: By separating read and write operations, it’s possible to scale each part independently based on the specific performance requirements of the system. This can lead to improved overall system performance.
- Flexibility: CQRS allows developers to optimize read and write models for specific use cases. This can lead to more efficient and performant systems and the ability to evolve each model independently over time.
- Event Sourcing Compatibility: CQRS works well with event sourcing, a technique that stores the state of a system as a series of events. This combination can provide a rich audit trail and make troubleshooting issues or recreating past system states easier.
- Enhanced Performance: By separating read and write operations, you can optimize each part individually, leading to potential performance improvements for both the query and command sides.
Cons Of CQRS:
- Complexity: Introducing CQRS into a system can increase its complexity. The need to manage separate models for reading and writing and any synchronization mechanisms can add development and maintenance overhead.
- Increased Learning Curve: Developers need to learn and understand the CQRS pattern and any supporting technologies like event sourcing, which can slow down the development and onboarding of new team members.
- Data Consistency: CQRS systems often use eventual consistency, meaning that read and write models might not always be perfectly synchronized. This can lead to temporary inconsistencies, which may not be suitable for some applications or business requirements.
- Not Suitable For All Applications: CQRS is more beneficial in systems with a high degree of complexity, where read and write workloads are significantly different. For more straightforward applications or those with balanced read and write loads, CQRS might not provide enough benefits to justify its implementation.
- Risk Of Over-Engineering: The temptation to apply CQRS everywhere can lead to unnecessary complexity and over-engineering, even when the pattern isn’t appropriate for a specific problem domain. It’s essential to carefully evaluate the system’s requirements and ensure that CQRS is a good fit before adopting it.
This video again comes from A Dev’s Story, who combined this topic with Event Sourcing in an easy-to-understand video.
9 — Domain-Driven Design (DDD)
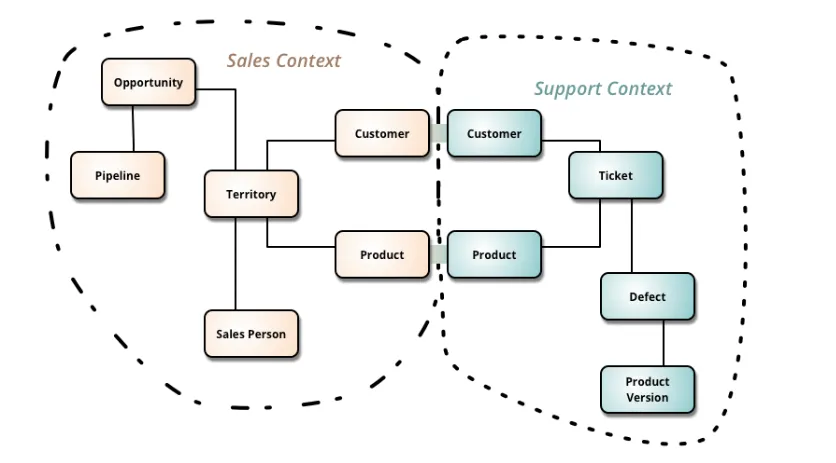
Domain Driven Design (DDD) is a software architectural pattern that focuses on building software by prioritising a deep understanding of the problem domain(the area of expertise or business that the software aims to address), its complexities and business requirements. Simply, it focuses on understanding the real-world problem you’re trying to solve and creating a well-organised, easy-to-maintain and flexible software solution.
DDD is loved and hated by the developer community; unlike others on this list, it’s very divisive because it prioritises business logic into your software build over functionality, frameworks and methodologies. I love DDD because I believe every project should be invented with a clean slate; we should challenge our uses of languages, frameworks, methods etc, with the core business objective in mind.
Pros of DDD:
- Improved Communication: DDD fosters better communication and collaboration between domain experts and developers by establishing a shared, ubiquitous language. This helps to reduce misunderstandings and ensures that the software accurately reflects the domain’s needs.
- Maintainability: DDD promotes organizing the software into modular components called Bounded Contexts, which encapsulate specific domain functionality. This modularity helps to minimize coupling between different parts of the system, making it easier to maintain and extend over time.
- Flexibility And Adaptability: By focusing on the domain’s core concepts and designing software closely mirrors the domain, DDD helps create flexible and adaptable solutions that can evolve as business requirements change.
- Better Alignment With Business Requirements: DDD emphasizes the importance of understanding the problem domain and its complexities, resulting in software better aligned with the actual business needs and processes.
- Scalability: Organizing the software into Bounded Contexts can improve the system’s scalability, as different components can evolve and scale independently.
Cons of DDD:
- Complexity: DDD can be complex to learn and implement, particularly for developers unfamiliar with its principles, patterns, and practices.
- Time-Consuming: DDD requires a significant investment of time and effort, especially during the initial stages when developing a deep understanding of the domain and establishing a ubiquitous language. This can slow down the development process.
- Not Suitable For All Projects: DDD is most effective for complex, evolving systems with rich domain logic. DDD may not provide enough benefits for more straightforward projects or those with minimal domain complexity to justify its implementation.
- Overemphasis On Modelling: More on modelling can sometimes lead to over-engineering and unnecessary complexity. It’s essential to balance modelling the domain and implementing practical solutions.
- Dependency On Domain Experts: DDD relies heavily on the input and collaboration of domain experts. If domain experts are not available or unwilling to collaborate, the effectiveness of DDD can be significantly reduced.
Amichai Mantinband made a very detailed yet succinct video on this topic.
10 — Pipes and Filters Pattern
The Pipe and Filters pattern is a design pattern that processes data through a sequence of filters arranged in a pipeline. Each filter performs a specific task and passes the result to the next filter in the pipeline. The pattern is commonly used in data processing systems and can improve the scalability and maintainability of complex data processing workflows.
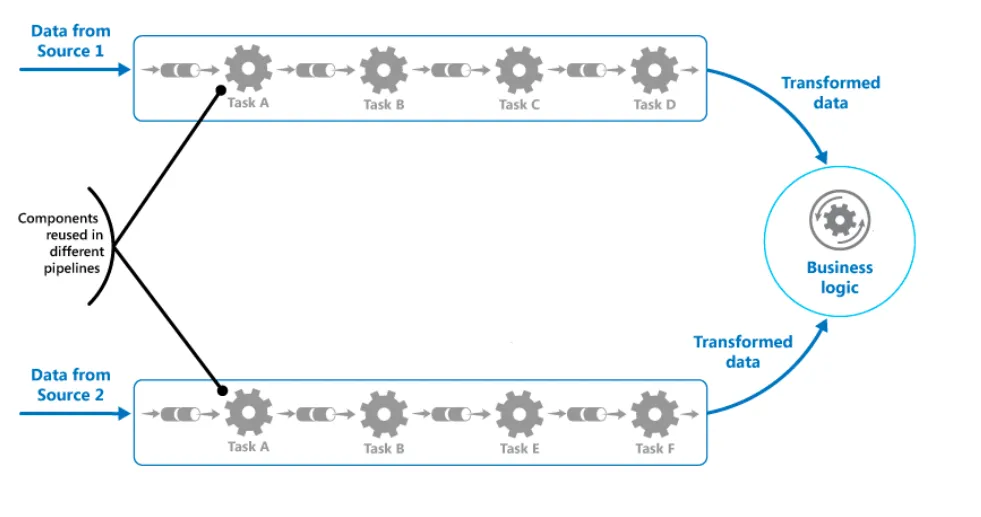
Pros Of The Pipes And Filters Pattern:
- Modularization: The pattern promotes modularization by breaking the data processing logic into smaller, more manageable filters. This makes it easier to develop and maintain complex data processing systems.
- Reusability: Filters can be reused in different pipelines, reducing the need to create redundant processing logic.
- Scalability: The pattern is inherently scalable because filters can be added or removed from the pipeline.
- Testability: Each filter can be tested independently, making identifying and fixing bugs easier.
Cons Of The Pipes And Filters Pattern:
- Overhead: Using a pipeline can introduce some overhead due to the need to pass data between filters. This can impact performance, mainly if the pipeline is long or the data volumes are large.
- Complexity: The pattern can be complex to implement and debug, mainly if the pipeline involves many filters with complex interdependencies.
- Maintenance: Maintenance can become difficult if the pipeline becomes too large or complex or if filters must be added or removed frequently.
- Data Loss: There is a risk of data loss if one of the filters in the pipeline fails to handle errors correctly. This can result in incomplete or incorrect results.