Key takeaways
- The key to effective data residency lies in understanding customer motivations, often unrelated to GDPR, and aligning technical solutions with contractual promises. Engaging with various stakeholders helps uncover specific project requirements and tailor data residency to meet customer needs.
- Establishing a clear "atom" as a fundamental unit for data within a region ensures a source of truth. Managing trust between regions involves cryptographic techniques and thorough threat models, with geopolitical factors playing a role.
- Consistently performing the same actions, especially in multi-region scenarios, simplifies system management, enhances predictability, and reduces unforeseen issues. Minimizing complexity and avoiding unnecessary design forks contribute to a more reliable system.
- Tailoring client routing strategies minimizes disruption during region transitions, ensuring flexibility and ease of adaptation. Subdomain-based routing, while effective, may inconvenience customers during region changes, necessitating the exploration of alternatives.
- Recognizing the strengths and limitations of accelerators and true global databases is crucial for data residency success. Understanding challenges in active-active topologies and conflict resolution methods highlights the need for a nuanced approach beyond relying solely on database proxies.
• • •
The main focus of this article is the effective implementation of data residency strategies while ensuring a positive experience for all stakeholders. The central idea revolves around the necessity of placing data in locations beyond a single source. There are various motivations for adopting this approach, such as disaster recovery and geo-redundancy. The core concept is to distribute data, ensuring that specific sets are housed in distinct regions without any shared overlap – a practice referred to as data residency.
First principles: Know Your Customer (KYC)
The crucial initial step in implementing data residency is identifying the intended beneficiaries and motivations behind the decision. Contrary to common misconception, data residency is not a GDPR requirement. Instead, the driving force is often the specific needs and concerns of your customers. This involves delving into the reasons behind the request for data residency, which may vary widely.
Begin by deciphering who initiated the need for data residency and why. Contrary to popular belief, it might not be directly linked to GDPR compliance. Engage with various stakeholders, including sales, customers, and legal teams, to comprehend the specific project requirements. The goal is to align the technical implementation with contractual promises regarding data residency.
At Rippling, for instance, the impetus behind this endeavour was customer requests from the EU seeking assurance around data privacy and regulatory exposure. This drove a set of restrictions, including the prohibition of inter-regional communication, highlighting the importance of tailoring the solution to the unique demands of your clientele.
Furthermore, consider scalability as a driving factor. While cell-based architectures can enhance system scalability, the decision to implement fully separated data residency should be rooted in specific needs. Separation and partitioning of data can be advantageous for scaling, and creating independent databases and architectures.
Additionally, data residency can contribute to your compliance story. For organizations dealing with multiple governments, each with distinct regulations and compliance requirements, separating data by region becomes very useful. For example, compliance jobs related to specific government regulations, such as the UK's unique labour laws, can be efficiently managed when the data resides in the same region. This not only addresses potential data access issues but also ensures alignment with varying compliance needs across different regions.
In essence, the key takeaway is to understand the intricacies of your organization's requirements and motivations. Avoid a one-size-fits-all approach, and instead tailor the data residency strategy to the specific needs of your company, stakeholders, and the regulatory landscape you operate within.
Truth and Trust
A critical principle in the context of multi-region deployments is establishing clarity on truth and trust. While knowing the source of truth for a piece of data is universally important, it becomes especially crucial in multi-region scenarios. Begin by identifying a fundamental unit, an "atom," within which all related data resides in one region. This could be an organizational entity like a company, a team, or an organization, depending on your business structure.
Any operation that involves crossing these atomic boundaries inherently becomes a cross-region scenario. Therefore, defining this atomic unit is essential in determining the source of truth for your multi-region deployment.
In terms of trust, as different regions hold distinct data, communication between them becomes necessary. This could involve scenarios like sharing authentication tokens across regions. The level of trust between regions is a decision rooted in the specific needs and context of your business. Consider the geopolitical landscape if governments are involved, especially if cells are placed in regions with potentially conflicting interests.
Before embarking on multi-region deployments, conduct a thorough threat model analysis in collaboration with your security team or consultants. Understand the potential risks and regulatory requirements in each country involved. Two crucial aspects that demand attention are access tokens and database access, as every application in this context must address these concerns.
The trust between regions can be reduced through cryptographic techniques, but the specific approach will depend on your business requirements. For example, you may need to evaluate the trade-offs between stateless communication and revocation delays based on your application's needs.
Initiate conversations with your team focusing on these two aspects – access tokens and database access – as they often lead to discussions around other pertinent considerations for your business. Establishing a robust philosophy and architectural foundation before implementation is crucial to avoid reevaluating fundamental design patterns later, especially when expanding into new markets or regions.
Do the same thing every time
The principle of consistently doing the same thing applies universally to software engineering but becomes particularly vital in multi-region scenarios. Avoiding unnecessary forks in the design path is crucial for robustness and reliability. This concept can be illustrated by revisiting a historical example related to network routing.
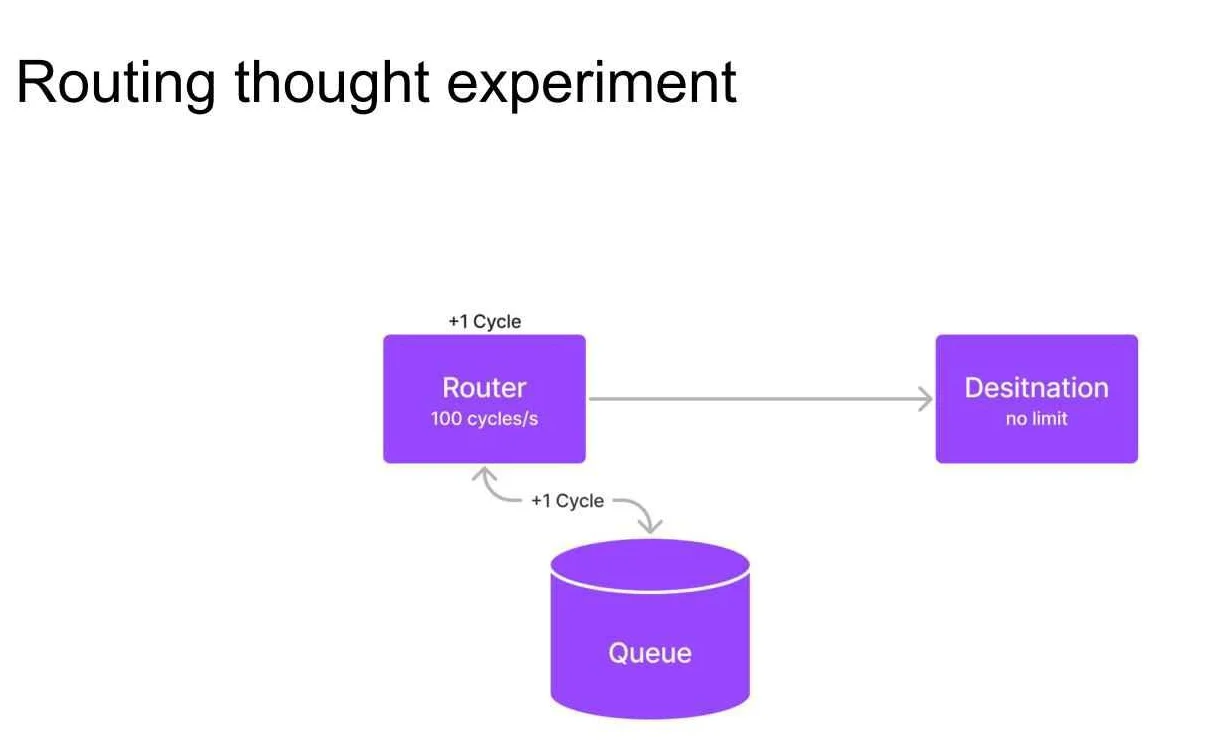
Figure 1: Routing thought experiment
Consider a router design where, in regular routing mode, the system operates efficiently. However, if the load exceeds a certain threshold, a queue is introduced. This seemingly reasonable design can lead to a catastrophic failure if the system operates at over 50% capacity. A single traffic spike can result in perpetual network downtime due to the inherent inefficiency of the design under such conditions.
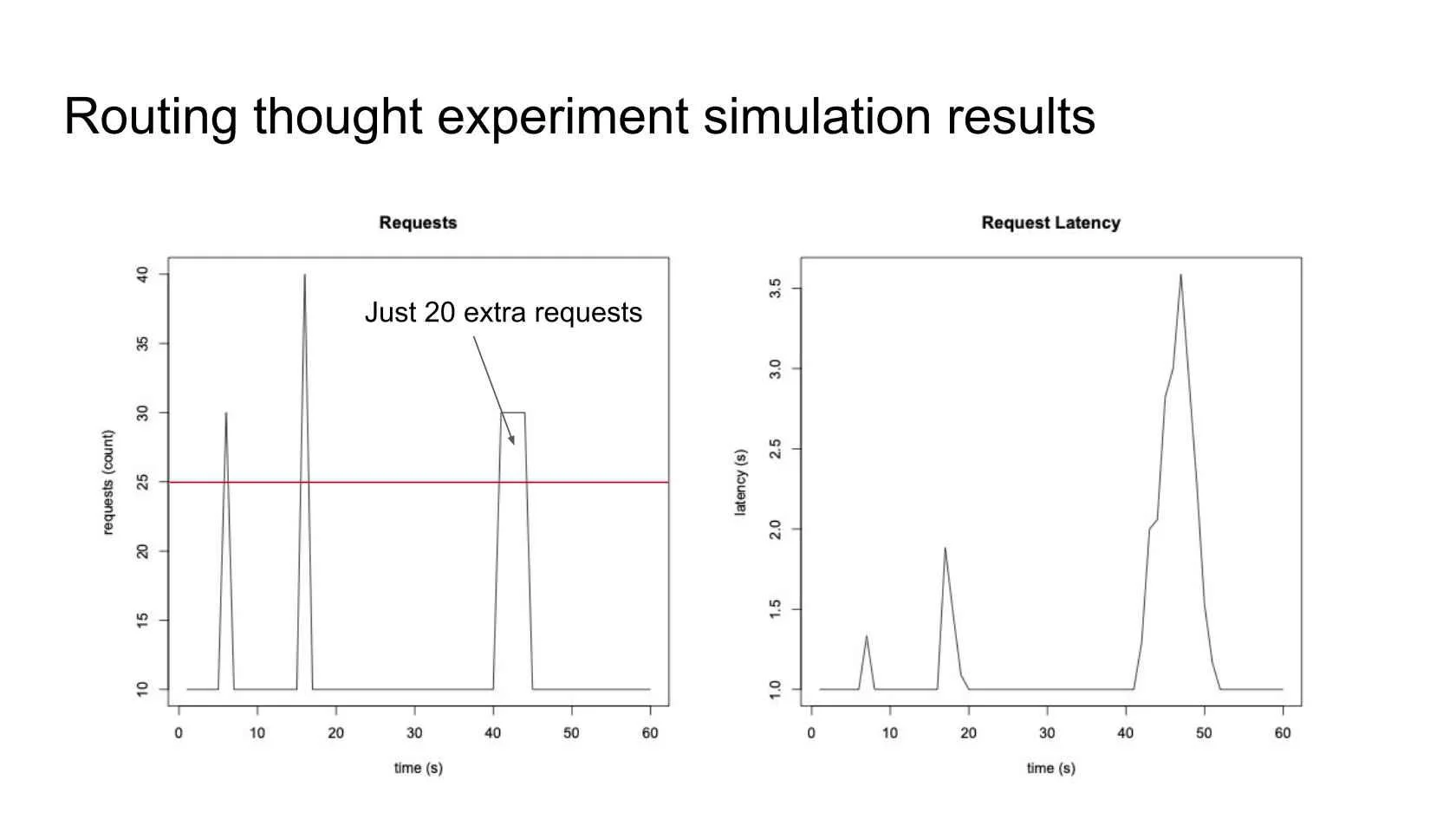
Figure 2: Simulation results
Applying this to multi-region scenarios, where routing decisions are frequent, it's essential to opt for designs where the same action is taken consistently. For instance, routing incoming traffic, avoid designs that include logical forks like "if multiregion; then". Doing the same thing every time simplifies the system, making it more predictable and easier to maintain.
Moreover, minimizing complexity and reducing the number of branches in the system enhances the likelihood of success. The addition of features, especially those with low user percentages, increases the chances of encountering unforeseen issues. The probability of a feature working is directly proportional to the fraction of users using it divided by the complexity of the feature.
Specifically, in multi-region scenarios, caution is advised when considering geographic proximity for routing decisions. Implementing rare code paths for exceptional circumstances, like diverting to another region, can be brittle and challenging to test thoroughly. Asymmetry in the application's behaviour between regions, especially concerning synchronous consistency, can lead to subtle bugs that are hard to track down.
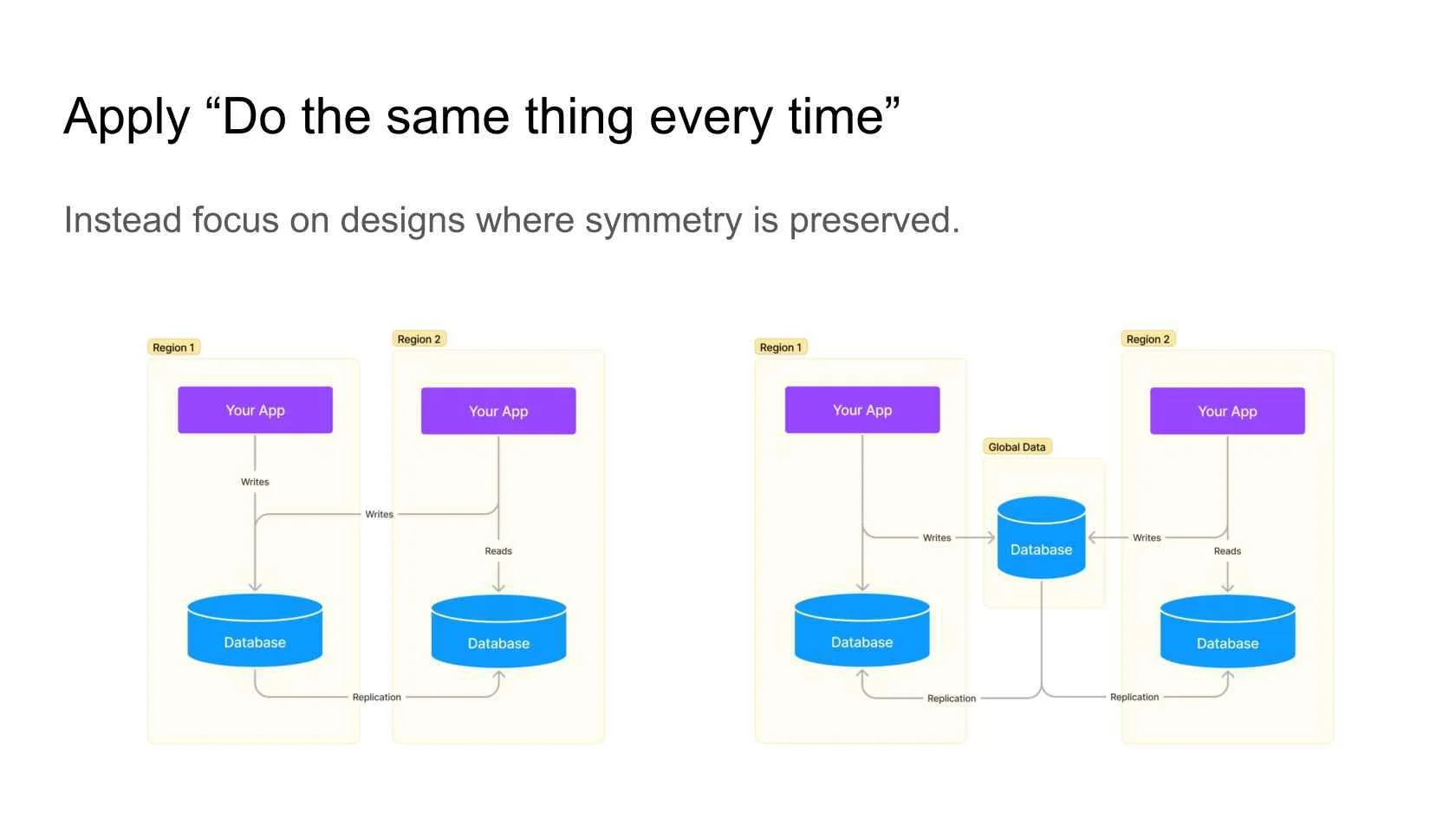
Figure 3: Apply "Do the same thing every time"
To illustrate, consider scenarios where one region writes synchronously to its local database, while another region writes asynchronously to a remote database. Reading just-written data in the first region will give immediately correct results where in the second region you would read stale data. Such inconsistencies can result in unpredictable behaviour and should be avoided. Striving for symmetry in designs, where both regions share similar code paths, ensures a more straightforward and reliable system. While this might introduce some complexity, the benefits of uniformity across regions outweigh the potential downsides.
Designs: Where to draw the Circles
In a cell-based architecture, where your application is likened to an onion with distinct layers (edge, app servers, and database), implementing effective client routing becomes pivotal. The objective is to encapsulate the inner contents of each layer as a single unit visible to external entities.
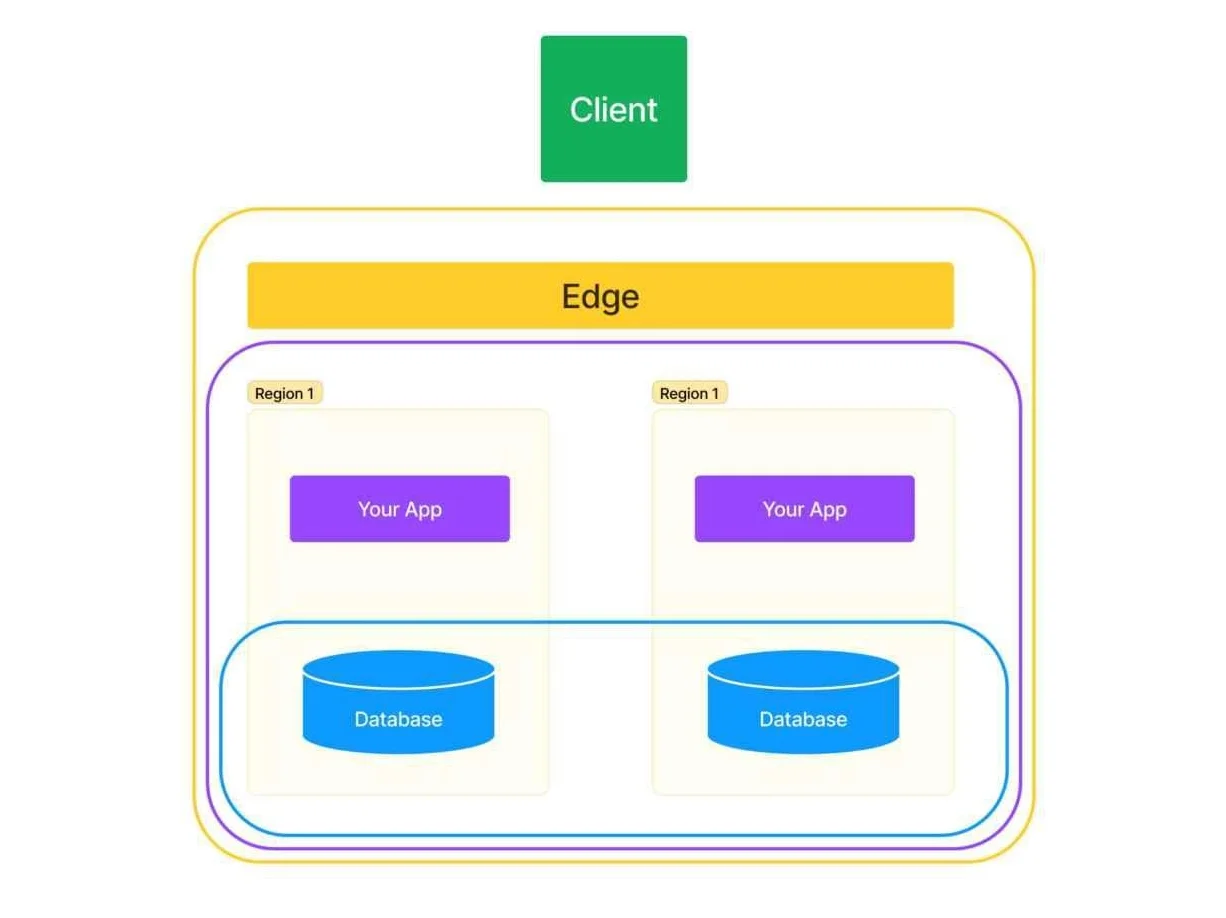
Figure 4: Application Onion
Client routing
For client routing, a straightforward approach is to allocate subdomains for each region, such as eu1.yourapp.com and us1.yourapp.com. This method simplifies the client's role in routing decisions and has been an initial solution employed by early adopters of cell-based architectures. While effective, it may inconvenience customers who need to manage routing logic themselves, particularly when their domain of concern aligns with the designated atom for data residency.
Despite its simplicity, this approach presents challenges when customers need to switch regions. If a user submits a request to change from Region 1 to Region 2, all their integrations relying on specific URLs and assumptions tied to the client domain knowledge of routing will break. While there are cases where this strategy is necessary, especially in data residency shifts, it might not be the optimal first-choice strategy.
Consider alternatives that offer a smoother experience for customers and minimize disruption during region transitions. Prioritize strategies that provide flexibility and ease of adaptation, reducing the burden on customers when navigating changes in the underlying infrastructure.
Gateway routing
In the context of a cell-based architecture, where atoms represent indivisible components of an application, introducing gateway routing can offer an efficient approach to client requests. The idea involves embedding the atom ID in the request and leveraging a mapping mechanism at the edge to determine the appropriate region.
For traffic residing within the atom boundary, this method is highly effective. By including a unique identifier, such as the company ID, in the request (as a header, query parameter, or path parameter), it serves as the routing key. The mapping at the edge then ensures that the traffic is directed to the correct region. If a region change occurs, updating the mapping at the edge suffices to reroute the traffic seamlessly.
However, this approach encounters challenges when dealing with cross-atom traffic. In scenarios where a partner needs to access multiple companies, each operating in different regions with distinct functionalities, the traditional gateway routing method falls short. Simply fanning out to the partner's first region and performing operations won't suffice.
Addressing cross-atom traffic requires additional considerations and strategies. It’s unlikely that gateway routing will be sufficient to address all use cases but it’s an effective approach for handling the large majority of traffic volumes in most applications.
Application routing
An effective strategy to address cross-atom traffic is allowing communication between regions. By enabling regions to communicate with each other, you create a framework where they can make calls, facilitating data access and interactions across regions. The feasibility of this approach hinges on the level of trust established between the regions, governed by your security policies and compliance requirements.
If your security policies permit cross-region data access for legitimate business purposes, which is often the case, enabling inter-region communication becomes a valuable tool. For instance, if your application requires a query that spans multiple companies, having regions capable of cross-talk can be advantageous.
Utilizing the atoms as a routing key, you can implement a batch API for efficient handling of queries involving multiple companies. This way, you can automate the routing to the appropriate regions based on the list of company IDs involved. While leveraging atoms is preferred when feasible, there might be instances, such as when conducting audit jobs across all regions, where a service operates independently of atoms.
However, it's crucial to note that allowing cross-region communication introduces complexity and may result in increased latency due to the geographical distance between regions. Regional latency, especially in cases like New York to Shanghai with a potential round trip time of 400 milliseconds, needs careful consideration. It's essential to assess the trade-offs and structure your application to minimize the impact of inter-region calls, perhaps by collecting data requirements upfront and optimizing the flow of requests to avoid unnecessary and latency-intensive calls.
Database-managed locality
There are a lot of databases out there that will say, "we're a global database". They often are. They're cool. They do stuff like replication. You can give a region key and it'll store the data in that region. We do have to talk through that a little bit because you have to think through what kind of use case they were trying to enable to decide whether this magic database is going to work for you.
Database-managed locality: Accelerators
- Adopt an active-passive topology, reminiscent of CDN functionality.
- Involve writing data once, with all regions receiving an eventually consistent copy.
- Ideal for accelerating local data flow, but not inherently tailored for data residency due to the data-copying nature.
Despite not being the core solution for data residency, accelerators excel in scenarios involving universal, consistent, and infrequently changing data. The U.S. tax code serves as a prime example, showcasing the effectiveness of replicating such data cross-region using an accelerator-type pattern.
Database-managed locality: Global databases
- Embrace a true global presence with active-active topology across regions.
- Allow both write and read operations from any location, guaranteeing eventual consistency.
While true global databases provide powerful capabilities, challenges arise in scenarios where an active-active topology follows a last-write-wins approach. This can lead to conflicts when multiple regions act on the same object simultaneously, requiring careful consideration of conflict resolution methods beyond a simple last-write-wins strategy.
Synchronous conflict resolution may necessitate a quorum between all nodes, incurring significant cross-region latency. Additionally, partial replication, where specific data sets are chosen for replication, is not universally supported and requires a thorough examination of database specifications.
In the pursuit of data residency solutions, relying solely on placing a database proxy in front is not a one-size-fits-all remedy. A nuanced understanding of technology capabilities, careful examination of specifications, and thoughtful consideration of conflict resolution methods are essential components of a successful data residency strategy.
Summary
Pulling it all together, you are going to have to ask your team who it is you're building this for, and what exactly the requirements are. It may surprise you, the answers aren’t one-size-fits all and will likely differ from your expectations. This is an incredibly important part of the exercise. When you're working through trust and truth, it's important to define an indivisible part of your architecture and then an encapsulating idea, so things above can be cross-region and things below never are cross-region. That will help immensely in keeping yourself sane when developing code.
Do the same thing every time. When you see forks in the road, especially related to region resolution related to business logic in that domain, I would strongly encourage you to think of ways to try to work around those forks in the road so that the code path followed is consistent. Again, when you're testing, when you're building your test and rollout plan when you're making changes in the future, it's going to be hard to know that you've broken one of these delicate mechanisms that are on a rare code path, try to get rid of those.