Hangfire — многопоточный и масштабируемый планировщик задач, построенный по клиент-серверной архитектуре на стеке технологий .NET (в первую очередь Task Parallel Library и Reflection), с промежуточным хранением задач в БД. Полностью функционален в бесплатной (LGPL v3) версии с открытым исходным кодом. В статье рассказывается, как пользоваться Hangfire.
Принципы работы
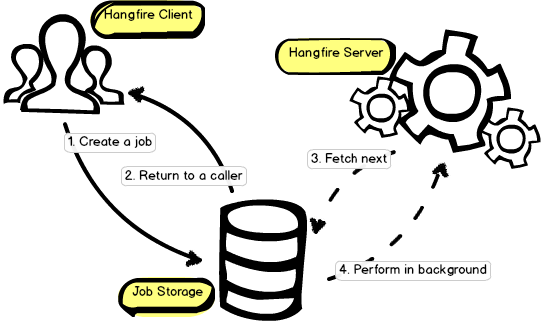
В чем суть? Как вы можете видеть на КДПВ, которую я честно скопировал из официальной документации, процесс-клиент добавляет задачу в БД, процесс-сервер периодически опрашивает БД и выполняет задачи. Важные моменты:
- Всё, что связывает клиента и сервера — это доступ к общей БД и общим сборкам, в которых объявлены классы-задачи.
- Масштабирование нагрузки (увеличение количества серверов) — есть!
- Без БД (хранилища задач) Hangfire не работает и работать не может. По-умолчанию поддерживается SQL Server, есть расширения для ряда популярных СУБД. В платной версии добавляется поддержка Redis.
- В качестве хоста для Hangfire может выступать что угодно: ASP.NET-приложение, Windows Service, консольное приложение и т.д. вплоть до Azure Worker Role.
С точки зрения клиента, работа с задачей происходит по принципу «fire-and-forget», а если точнее — «добавил в очередь и забыл» — на клиенте не происходит ничего, помимо сохранения задачи в БД. К примеру, мы хотим выполнить метод MethodToRun в отдельном процессе:
BackgroundJob.Enqueue(() => MethodToRun(42, "foo"));
Эта задача будет сериализована вместе со значениями входных параметров и сохранена в БД:
{
"Type": "HangClient.BackgroundJobClient_Tests, HangClient, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
"Method": "MethodToRun",
"ParameterTypes": "(\"System.Int32, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089\",\"System.String, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089\")",
"Arguments": "(\"42\",\"\\\"foo\\\"\")"
}
Данной информации достаточно, чтобы вызвать метод MethodToRun в отдельном процессе через Reflection, при условии доступа к сборке HangClient, в которой он объявлен. Естественно, совершенно необязательно держать код для фонового выполнения в одной сборке с клиентом, в общем случае схема зависимостей такая:
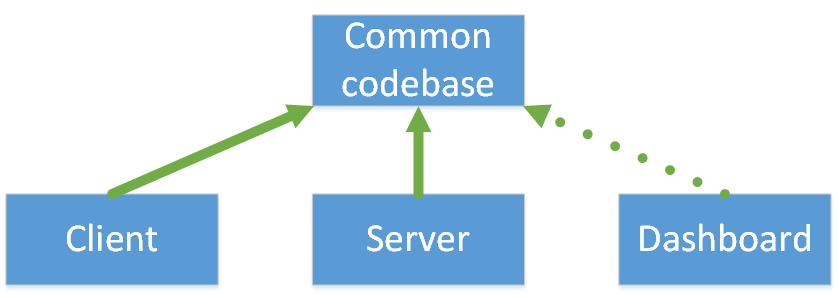
Клиент и сервер должны иметь доступ к общей сборке, при этом для встроенного веб-интерфейса (о нем чуть ниже) доступ необязателен. При необходимости возможно заменить реализацию уже сохраненной в БД задачи — путем замены сборки, на которую ссылается приложение-сервер. Это удобно для повторяемых по расписанию задач, но, конечно же, работает при условии полного совпадения контракта MethodToRun в старой и новой сборках. Единственное ограничение на метод — наличие public модификатора.
Необходимо создать объект и вызвать его метод? Hangfire сделает это за нас:
BackgroundJob.Enqueue<EmailSender>(x => x.Send(13, "Hello!"));
И даже получит экземпляр EmailSender через DI-контейнер при необходимости.
Развернуть сервер (например в отдельном Windows Service) проще некуда:
public partial class Service1 : ServiceBase
{
private BackgroundJobServer _server;
public Service1()
{
InitializeComponent();
GlobalConfiguration.Configuration.UseSqlServerStorage("connection_string");
}
protected override void OnStart(string() args)
{
_server = new BackgroundJobServer();
}
protected override void OnStop()
{
_server.Dispose();
}
}
После старта сервиса наш Hangfire-сервер начнет подтягивать задачи из БД и выполнять их.
Необязательным для использования, но полезным и очень приятным является встроенный web dashboard, позволяющий управлять обработкой задач:
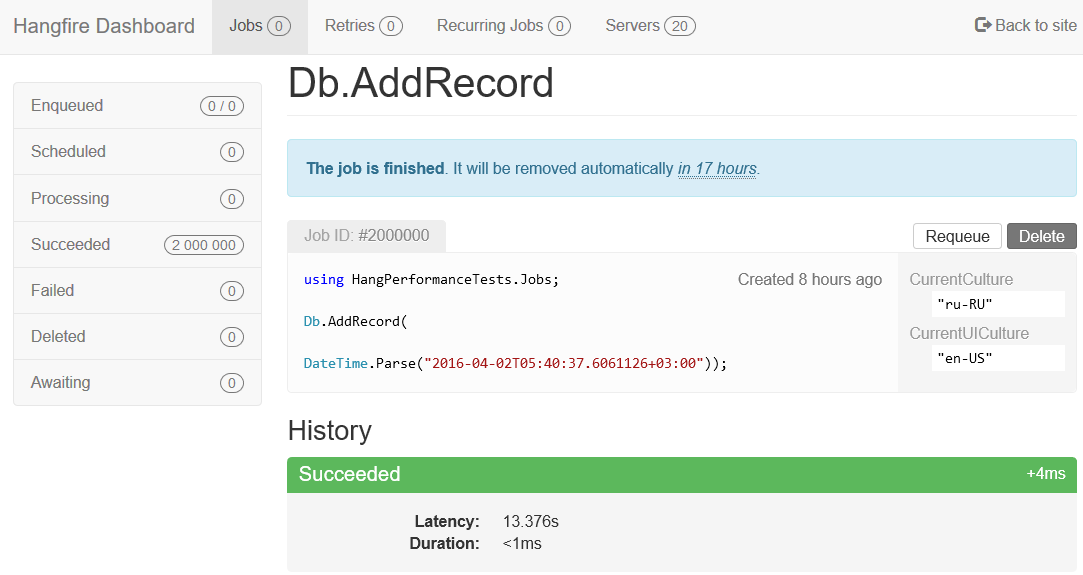
Внутренности и возможности Hangfire-сервера
Прежде всего, сервер содержит свой пул потоков, реализованный через Task Parallel Library. А в основе лежит всем известный Task.WaitAll (см. класс BackgroundProcessingServer).
Горизонтальное масштабирование? Web Farm? Web Garden? Поддерживается:
You don’t want to consume additional Thread Pool threads with background processing – Hangfire Server uses custom, separate and limited thread pool.
You are using Web Farm or Web Garden and don’t want to face with synchronization issues – Hangfire Server is Web Garden/Web Farm friendly by default.
Мы можем создать произвольное количество Hangfire-серверов и не думать об их синхронизации — Hangfire гарантирует, что одна задача будет выполнена одним и только одним сервером. Пример реализации — использование sp_getapplock (см. класс SqlServerDistributedLock).
Как уже отмечалось, Hangfire-сервер не требователен к процессу-хосту и может быть развернут где угодно от Console App до Azure Web Site. Однако, он не всемогущ, поэтому при хостинге в ASP.NET следует учитывать ряд общих особенностей IIS, таких как process recycling, авто-старт (startMode=«AlwaysRunning» ) и т.п. Впрочем, документация планировщика предоставляет исчерпывающую информацию и на этот случай.
Кстати! Не могу не отметить качество документации — оно выше всяких похвал и находится где-то в районе идеального. Исходный код Hangfire окрыт и качественно оформлен, нет никаких препятствий к тому, чтобы поднять локальный сервер и походить по коду отладчиком.
Повторяемые и отложенные задачи
Hangfire позволяет создавать повторяемые задачи с минимальным интервалом в минуту:
RecurringJob.AddOrUpdate(() => MethodToRun(42, "foo"), Cron.Minutely);
Запустить задачу вручную или удалить:
RecurringJob.Trigger("task-id");
RecurringJob.RemoveIfExists("task-id");
Отложить выполнение задачи:
BackgroundJob.Schedule(() => MethodToRun(42, "foo"), TimeSpan.FromDays(7));
Создание повторяющейся И отложенной задачи возможно при помощи CRON expressions (поддержка реализована через проект NCrontab). К примеру, следующая задача будет выполняться каждый день в 2:15 ночи:
RecurringJob.AddOrUpdate("task-id", () => MethodToRun(42, "foo"), "15 2 * * *");
Микрообзор Quartz.NET
Рассказ о конкретном планировщике задач был бы неполон без упоминания достойных альтернатив. На платформе .NET таковой альтернативой является Quartz.NET — порт планировщика Quartz из мира Java. Quartz.NET решает схожие задачи, как и Hangfire — поддерживает произвольное количество «клиентов» (добавление задачи) и «серверов» (выполнение задачи), использующих общую БД. Но исполнение разное.
Мое первое знакомство с Quartz.NET нельзя было назвать удачным — взятый из официально GitHub-репозитория исходный код просто не компилировался, пока я вручную не поправил ссылки на несколько отсутствующих файлов и сборок (disclaimer: просто рассказываю, как было). Разделения на клиентскую и серверную часть в проекте нет — Quartz.NET распространяется в виде единственной DLL. Для того, чтобы конкретный экземляр приложения позволял только добавлять задачи, а не исполнять их — необходимо его настроить.
Quartz.NET полностью бесплатен, «из коробки» предлагает хранение задач как in-memory, так и с использованием многих популярных СУБД (SQL Server, Oracle, MySQL, SQLite и т.п.). Хранение in-memory представляет собой по-сути обычный словарь в памяти одного единственного процесса-сервера, выполняющего задачи. Реализовать несколько процессов-серверов становится возможным только при сохранении задач в БД. Для синхронизации, Quartz.NET не полагается на специфичные особенности реализации конкретной СУБД (те же Application Lock в SQL Server), а использует один обобщенный алгоритм. К примеру, путем регистрации в таблице QRTZ_LOCKS гарантируется единовременная работа не более чем одного процесса-планировщика с конкретным уникальным id, выдача задачи «на исполнение» осуществляется простым изменением статуса в таблице QRTZ_TRIGGERS.
Класс-задача в Quartz.NET должен реализовывать интерфейс IJob:
public interface IJob
{
void Execute(IJobExecutionContext context);
}
С подобным ограничением, очень просто сериализовать задачу: в БД хранится полное имя класса, что достаточно для последующего получения типа класса-задачи через Type.GetType(name). Для передачи параметров в задачу используется класс JobDataMap, при этом допускается изменение параметров уже сохраненной задачи.
Что касается многопоточности, то Quartz.NET использует классы из пространства имен System.Threading: new Thread() (см. класс QuartzThread), свои пулы потоков, синхронизация через Monitor.Wait/Monitor.PulseAll.
Немалой ложкой дегтя является качество официальной документации. К примеру, вот материал по кластеризации: Lesson 11: Advanced (Enterprise) Features. Да-да, это всё, что есть на официальном сайте по данной теме. Где-то на просторах SO встречался фееричный совет просматривать также гайды по оригинальному Quartz, там тема раскрыта подробнее. Желание разработчиков поддерживать похожее API в обоих мирах — Java и .NET — не может не сказываться на скорости разработки. Релизы и обновления у Quartz.NET нечасто.
Пример клиентского API: регистрация повторяемой задачи HelloJob:
IScheduler scheduler = GetSqlServerScheduler();
scheduler.Start();
IJobDetail job = JobBuilder.Create<HelloJob>().Build();
ITrigger trigger = TriggerBuilder.Create()
.StartNow()
.WithSimpleSchedule(x => x
.WithIntervalInSeconds(10)
.RepeatForever())
.Build();
scheduler.ScheduleJob(job, trigger);
Основные характеристики двух рассмотренных планировщиков сведены в таблицу:
| Характеристика |
Hangfire |
Quartz.NET |
| Неограниченное количество клиентов и серверов |
Да |
Да |
| Исходный код |
github.com/HangfireIO |
github.com/quartznet/quartznet |
| NuGet-пакет |
Hangfire |
Quartz |
| Лицензия |
LGPL v3 |
Apache License 2.0 |
| Где хостим |
Web, Windows, Azure |
Web, Windows, Azure |
| Хранилище задач |
SQL Server (по-умолчанию), ряд СУБД через расширения, Redis (в платной версии) |
In-memory, ряд БД (SQL Server, MySQL, Oracle...) |
| Реализация многопоточности |
TPL |
Thread, Monitor |
| Web-интерфейс |
Да |
Нет. Планируется в будущих версиях. |
| Отложенные задачи |
Да |
Да |
| Повторяемые задачи |
Да (минимальный интервал 1 минута) |
Да (минимальный интервал 1 миллисекунда) |
| Cron Expressions |
Да |
Да |
Про (не)нагрузочное тестирование
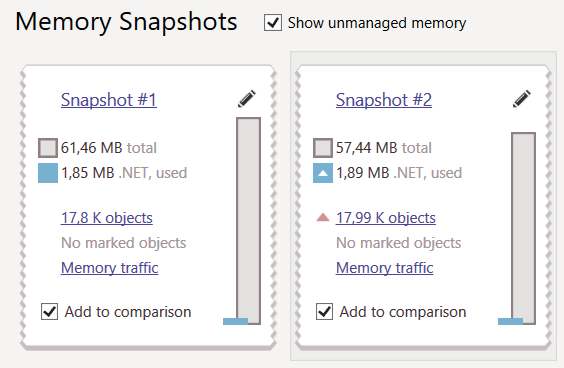
Необходимо было проверить, как справится Hangfire с большим количеством задач. Сказано-сделано, и я написал простейшего клиента, добавляющего задачи с интервалом в 0,2 с. Каждая задача записывает строку с отладочной информацией в БД. Поставив на клиенте ограничение в 100К задач, я запустил 2 экземпляра клиента и один сервер, причем сервер — с профайлером (dotMemory). Спустя 6 часов, меня уже ожидало 200К успешно выполненных задач в Hangfire и 200К добавленных строк в БД. На скриншоте приведены результаты профилирования — 2 снимка состояния памяти «до» и «после» выполнения:
На следующих этапах работало уже 20 процессов-клиентов и 20 процессов-серверов, а время выполнения задачи было увеличено и стало случайной величиной. Вот только на Hangfire это не отражалось вообще никак:
Выводы
Лично мне понравился Hangfire. Бесплатный, открытый продукт, сокращает расходы на разработку и поддержку распределенных систем.