In-depth overview of 18 essential Software Architecture design patterns.
Table of contents
What is Software Architecture?
Software architecture refers to the high-level structure of a software system, defining how different components and modules of the system interact with each other. It encompasses various design decisions and patterns that shape the system’s overall behavior, performance, scalability, and maintainability.
Software architecture is the process of defining the high-level structure and organization of a software system. It involves identifying and selecting the right components, deciding how they will interact with each other, and determining how they should be organized to achieve specific goals. The goal of software architecture is to create a maintainable, scalable, and secure system that meets the needs of users and the organization.
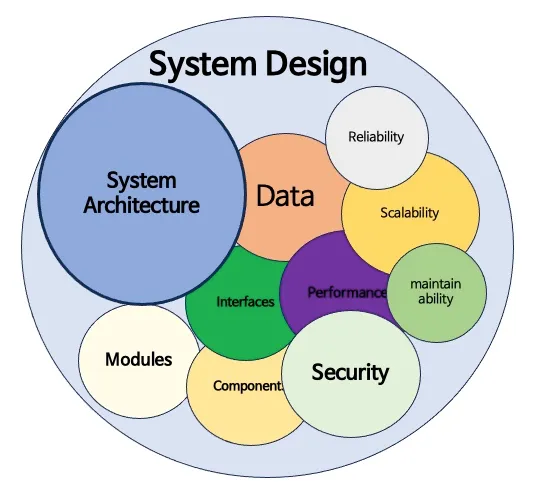
Why do we need software architecture?
A strong architecture provides a solid foundation for building software that meets the needs of users and stakeholders. It ensures that the system meets its functional and non-functional requirements such as performance, security and reliability. With a well-designed architecture, developers can build software that is easy to modify and extend, making it easier to adapt to changing business needs.
Software architecture is also critical to managing complexity. As software systems become more complex, understanding how different components interact with each other becomes challenging. A well-designed architecture provides a high-level view of the system, making it easier to understand its structure and operation. This in turn helps developers identify potential problems and make informed decisions on how to modify the system.

Software Architecture vs Software Design
Software Architecture
Software architecture refers to the high-level structure of the entire software system. It defines the components or modules of the system, their relationships, and the principles and guidelines governing their design and evolution. Software architecture focuses on ensuring that the software meets the required quality attributes such as performance, scalability, reliability, and security.
Example: Consider designing a modern e-commerce platform. The software architecture would define:
- Components: Such as client interfaces (web, mobile apps), backend services (product catalog, user authentication), and databases.
- Interactions: How these components communicate with each other, such as through RESTful APIs or message queues.
- Deployment: Strategies for deploying components across servers or cloud services like AWS or Azure.
- Scalability: How the system can handle varying loads during peak shopping seasons.
- Security: Measures to protect user data and transactions.
Software Design
Software design, also known as detailed design, focuses on designing individual components or modules identified in the software architecture. It involves specifying the internal structure of each component, their interfaces, algorithms, and data structures. Software design aims to translate the architectural blueprint into detailed specifications that developers can implement.
Example: In the e-commerce platform example:
- Detailed component design: Designing the product catalog service to handle querying and updating product information efficiently, including choosing the appropriate database schema.
- Interface design: Defining APIs and data formats used by different services to communicate with each other.
- Algorithm cesign: Developing algorithms for search functionality to quickly retrieve relevant products based on user queries.
- Data storage design: Determining how user information and transaction data will be stored securely in the database.
Software architecture is more abstract and conceptual, defining the system’s blueprint. Software design is more concrete, specifying how components will be built and integrated.
Software architecture ensures that the Software meets functional and non-functional requirements. Software design ensures that each component operates effectively within the defined architecture.
In summary, Software design is a more detailed and specific activity focused on designing the internal components and behavior of a Software, while Software architecture provides a broader perspective and focuses on the overall structure and organization of the Software.
Software architecture sets the foundation for Software design by defining the high-level structure and principles that guide the design process.
How to document architecture? 4C model.
Document architecture refers to the structured approach and methodology used to document the design, structure, components, and behaviors of a software system or application.
“Big design up front is dumb, but doing no design up front is even dumber.”
Dave Thomas
Document architecture is essential because it ensures clarity, facilitates collaboration, supports maintenance and evolution, and provides a structured approach to software development and system management.
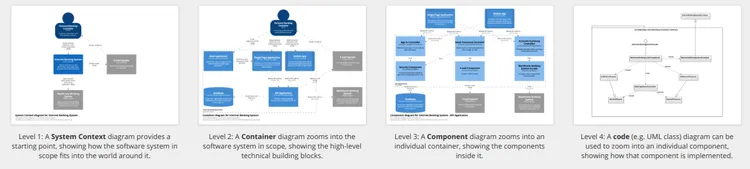
Context level
Context refers to the high-level view of the system, including its goals, stakeholders, and the environment in which it operates.
Example: Imagine you are documenting the architecture of a new e-commerce platform:
- Goals: Enable users to browse and purchase products online.
- Stakeholders: Customers, administrators, support staff, developers.
- Environment: Web-based application accessible via browsers and mobile devices.
Documentation approach:
- Diagrams: Use context diagrams showing the system in relation to external entities (users, external systems).
- Descriptions: Provide textual descriptions of the system’s purpose, user demographics, and strategic goals.
Containers level
The next level is the container level, which describes the system’s runtime environment, such as a server, database, or message queue. This level helps identify major technology choices and deployment decisions.
It provides an understanding of the physical infrastructure that will support the system and the tools and resources required for deployment and maintenance.
Example: For the e-commerce platform:
- Containers: Web server (e.g., Apache or Nginx), application server (e.g., Tomcat), database server (e.g., MySQL or MongoDB).
- Deployment: Cloud-based infrastructure (AWS EC2 instances, RDS for database), Kubernetes clusters for container orchestration.
Documentation approach:
- Diagrams: Container diagrams showing how different parts of the system are physically or virtually deployed.
- Descriptions: Document each container’s responsibilities, technologies used, and interaction patterns.
Components level
Components are the building blocks or modules within each container, representing major parts of the system.
Example: Within the application server container of the e-commerce platform:
- Components: User authentication module, product catalog module, shopping cart module, order processing module.
- Technologies: Spring MVC for web layer, Hibernate for ORM, RESTful APIs for communication.
Documentation Approach:
- Diagrams: Component diagrams illustrating the structure and dependencies of each major module.
- Descriptions: Detail each component’s functionality, interfaces, data flows, and dependencies on other components.
Code level
Finally, the code level is the lowest level and describes the actual code and how it implements the component. This level provides a detailed understanding of how the system works and how its different components interact with each other. For developers who will be working with the code, it is crucial to have a clear understanding of how the code is structured and works.
Code refers to the actual implementation details of the components, including classes, methods, and their relationships.
Example: Within the user authentication module of the e-commerce platform:
- Classes: User, AuthenticationManager, UserDAO.
- Methods: authenticateUser(), getUserDetails(), updateUserPassword().
- Relationships: Dependency injection between classes, data access patterns.
Documentation Approach:
- Diagrams: Class diagrams showing class relationships and inheritance hierarchies.
- Descriptions: Code comments, README files, and inline documentation explaining the purpose, usage, and logic of each class and method.
Using the C4 model, software architects can create diagrams and written documentation describing each level, providing a comprehensive view of the system architecture. This approach helps identify potential issues and trade-offs while promoting scalability, maintainability, and adaptability. By documenting the architecture in this way, developers and stakeholders have a clear, easy-to-understand understanding of the system, making it easier to modify and extend based on business needs.
• • •
18 Software Architecture design patterns to know
Architectural patterns increase your productivity: These reusable schemes address common software design challenges.
If you design software architectures, chances are that you come across the same goals and problems over and over again. Architectural patterns make it easier to solve these issues by providing repeatable designs that address common situations.
“The architectural pattern captures the design structures of various systems and elements of software so that they can be reused. During the process of writing software code, developers encounter similar problems multiple times within a project, within the company, and within their careers. One way to address this is to create design patterns that give engineers a reusable way to solve these problems, allowing software engineers to achieve the same output structurally for a given project.”
1. Client-Server
Client-server architecture is a model in which a client (user or application) sends a request to a server, and the server returns the requested data or service. The client and server can be on the same machine or on different machines connected through the network.
The client is responsible for initiating communication with the server and sending requests. The server listens for requests from clients, processes and returns responses.
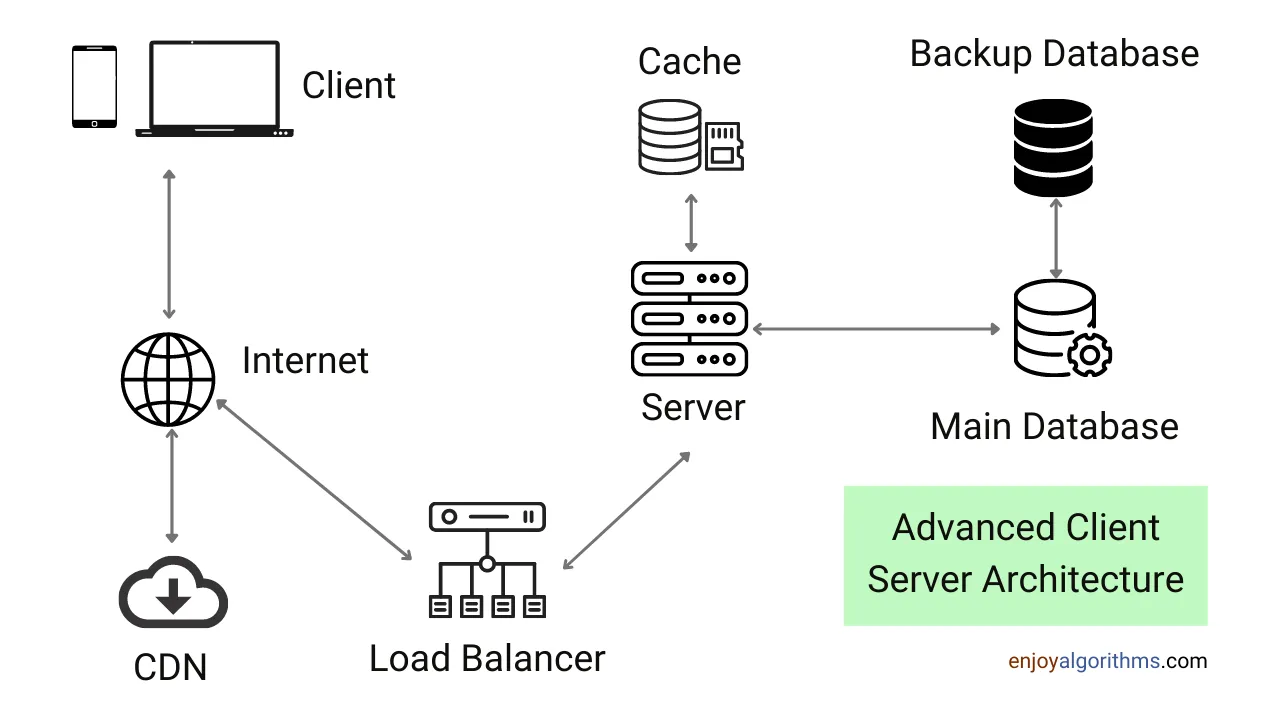
Advantages of client-server architecture:
- Scalability: Client-server architecture is highly scalable as it allows multiple clients to connect to the same server and share resources.
- Security: Client-server architecture provides better security than other network models because the server can control access to resources and data.
- Reliability: Client-server architecture is very reliable as the server can provide backup and recovery services in case of failure.
2. Layering: Layered architecture
This is a common way of designing complex software systems, which breaks the system into layers, each responsible for a specific set of functionality. This approach helps organize code and makes the system easier to maintain and modify over time.
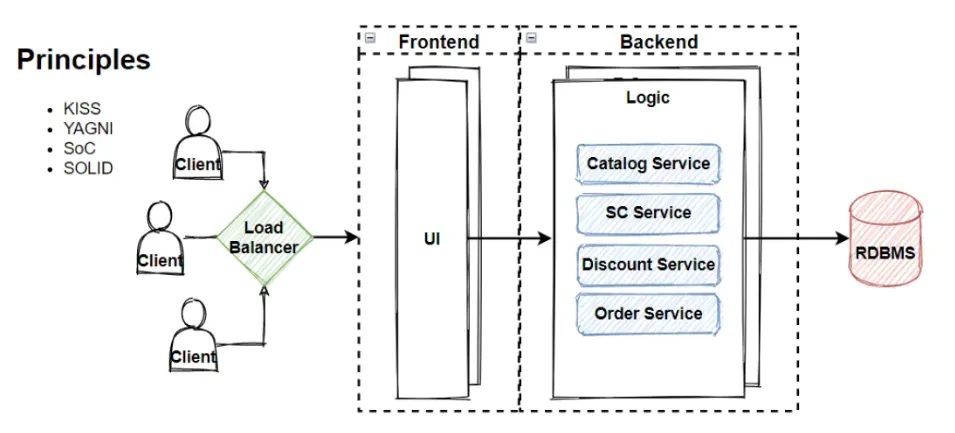
A typical layered architecture consists of three main layers: presentation layer, business logic layer, and data access layer.
Presentation layer: The presentation layer is responsible for displaying information to the user and collecting input. This layer includes the user interface and other components that interact directly with the user. User interface is what users see and interact with, such as buttons, text boxes, and menus. The presentation layer also includes any logic related to the user interface, such as event handlers and validation.
Business logic layer: The business logic layer is responsible for implementing the business rules of the application. This layer contains the code to process and manipulate data, as well as any other application logic. The business logic layer is where the software works its magic. It is where the software performs calculations, makes decisions and performs tasks. It is where the software really does its work.
Data Access Layer: The data access layer is responsible for interacting with databases or other external data sources. This layer contains the code that reads and writes data to the database. The data access layer is key for the software to retrieve data, make changes to the data, and save the changes back to the database. This layer is critical to the functionality of the software as it enables the software to store and retrieve data.
3. Pipes and filters
Pipe and filter architecture is a design pattern that allows software systems to process data by separating processing tasks into independent components. This architecture is particularly helpful for systems that need to process large amounts of data. It improves performance, scalability, and maintainability.
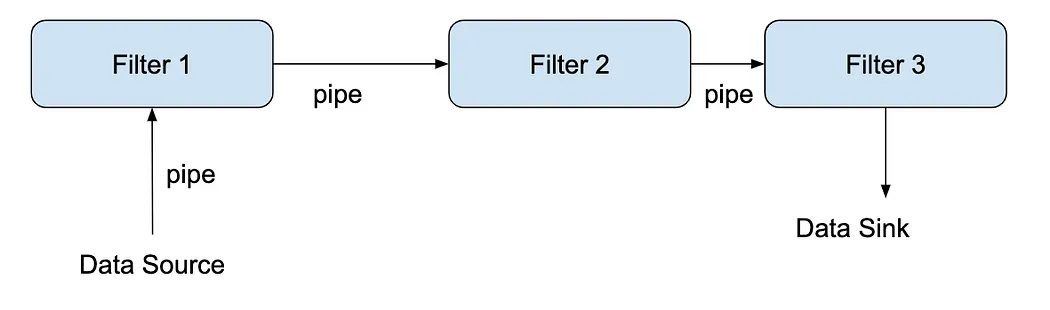
1. Data Source
The data source serves as the start of the pipeline. It is responsible for receiving the input data and delivering it down the pipeline.
2. Pipe
Pipes connects the other components together. They serve to transfer and buffer data between the other components, from a component upstream to one that is downstream. Additionally, pipes also synchronize the activity of neighboring filters.
3. Filter
Filters are self-contained data processing steps that performs a transformation function on data. It receives data from a pipe upstream, transforms the data, then sends the transformed data to the pipe downstream.
4. Data Sink
The data sink serves as the end of the pipeline. It receives the processed data at the end of the pipeline and serves it as the application’s output.
Real-world example: Image processing pipeline
Imagine you have an image processing system where you want to apply several filters to an image sequentially, such as resizing, applying filters (like sharpening or blurring), and then saving the processed image to storage.
Filters:
- Resize Filter: Resizes the image to a specified dimension.
- Sharpen Filter: Enhances the sharpness of the resized image.
- Blur Filter: Applies a blur effect to the image.
- Save Filter: Saves the final processed image to storage.
Pipeline:
- Input: Original image.
- Processing Steps:
- Input image → Resize Filter → Sharpen Filter → Blur Filter → Save Filter → Output image.
In below example, we’ll create a basic pipeline for processing a list of integers through two filters: a Filter to remove odd numbers and a Filter to square each number.
import java.util.ArrayList;
import java.util.List;
// Interface for defining a filter
interface Filter {
List<Integer> process(List<Integer> input);
}
// Concrete implementation of a filter: Remove odd numbers
class RemoveOddFilter implements Filter {
@Override
public List<Integer> process(List<Integer> input) {
List<Integer> output = new ArrayList<>();
for (Integer number : input) {
if (number % 2 == 0) {
output.add(number);
}
}
return output;
}
}
// Concrete implementation of a filter: Square each number
class SquareFilter implements Filter {
@Override
public List<Integer> process(List<Integer> input) {
List<Integer> output = new ArrayList<>();
for (Integer number : input) {
output.add(number * number);
}
return output;
}
}
// Pipeline class that connects filters together
class Pipeline {
private List<Filter> filters = new ArrayList<>();
public Pipeline addFilter(Filter filter) {
filters.add(filter);
return this;
}
public List<Integer> execute(List<Integer> input) {
List<Integer> result = input;
for (Filter filter : filters) {
result = filter.process(result);
}
return result;
}
}
public class Main {
public static void main(String[] args) {
// Create a list of integers
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// Create pipeline and add filters
Pipeline pipeline = new Pipeline();
pipeline.addFilter(new RemoveOddFilter());
pipeline.addFilter(new SquareFilter());
// Execute pipeline
List<Integer> result = pipeline.execute(new ArrayList<>(numbers));
// Print the result
System.out.println("Original numbers: " + numbers);
System.out.println("Processed numbers: " + result);
}
}

Filters in a pipeline are independent of each other, meaning they can be developed, tested, and deployed independently. This makes it easy to add new filters to the pipeline or modify existing filters without affecting other parts of the system.
Advantage:
- Scalability: The architecture can scale horizontally by adding more filters to the pipeline, allowing the system to handle larger amounts of data.
- Performance: This architecture can optimize performance by parallelizing data processing across multiple filters.
- Maintainability: The architecture promotes modularity and separation of concerns, making the system easier to maintain and update.
4. Master and slave
Master-slave architecture is a design pattern used in distributed systems in which one node (the master node) controls one or more nodes (the slave nodes) to perform specific tasks. The master node is responsible for distributing workloads to slave nodes and coordinating their activities. Slave nodes do not have the same level of control as the master node and only perform tasks assigned to them by the master node.
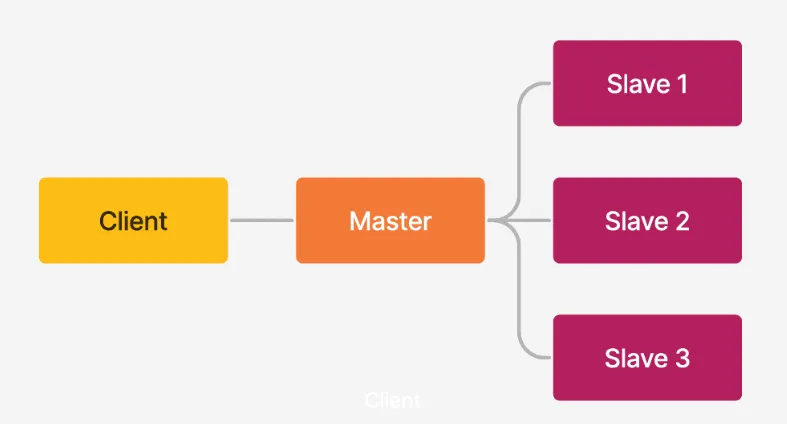
Advantages: One of the most important advantages is that it allows efficient distribution of workloads across multiple nodes. This helps reduce the load on any one node and ensures the system can handle large volumes of data and traffic.
Another advantage of using a master-slave architecture is that it provides fault tolerance. If a slave node fails, the master node can redistribute its workload to other slave nodes. This ensures that even if one or more nodes fail, the system can still function properly.
Real-world example: Web server load balancing
A common real-world example of the Master-Slave architecture is load balancing in a web server cluster. Let’s consider a scenario where multiple web servers handle incoming HTTP requests. To efficiently distribute the workload among these servers, a master node (load balancer) directs incoming requests to different slave nodes (web servers) based on factors like current load, server availability, or proximity to the client.
Master node (load balancer):
- Receives incoming requests from clients.
- Determines which slave node (web server) should handle each request based on predefined rules (e.g., round-robin, least connections).
- Distributes the requests to slave nodes.
Slave nodes (web servers):
- Receive tasks (HTTP requests in this case) from the master node.
- Process the tasks independently and return the results (HTTP responses) to clients via the master node.
We can apply the same ‘master-slave’ pattern in database as well.
“Data is the new Oil”, with rising Data — The accessibility, readability, and backup of the data are major concerns.
Master-Slave database configuration in simple words is dividing our master databases into multiple slave databases. The Slave database serves as a backup for the master database.
5. Microkernel
Microkernel architecture, also known as pluggable architecture, is a software design pattern that allows developers to build more modular and flexible systems. It separates core system functionality from other functionality, which are implemented in separate modules. The core functions of the system are implemented in the microkernel, which is the most basic core system and only provides the most basic services required to run the system. It’s a plug-and-play concept.
Example: Take an e-commerce website as an example. The microkernel will provide basic services such as handling user authentication, managing user sessions and processing payments. Other features, such as product recommendations, user reviews and social media integration, will be implemented in separate modules.
If the website wants to add a new feature, such as a loyalty program, it can be developed and added as a separate module without affecting the core functionality of the system. This modularity makes it easier to add new features or remove existing features without affecting core system functionality.
Additionally, if a website wants to tailor its system to the specific needs of different users, it can select the required modules for each user. For example, users who frequently purchase electronic products can provide a module that recommends electronic products. On the other hand, users who frequently purchase cosmetics can provide a module for recommending cosmetics.
Finally, if a website wants to expand its system to handle more users or hardware changes, modules can be easily added or removed as needed. This scalability makes it easier to adapt the system to changes in user needs or underlying hardware.
6. Domain-driven design (DDD)
In essence, DDD is a way of thinking about software architecture that emphasizes the domain or problem space of the project. This means that developers focus on the business logic of the software, not just the technical implementation.
In practice, this means developers first understand the domain they are working on and break it down into smaller, more manageable pieces. They then use this understanding to create a domain model, which is a representation of the different entities within the domain and their interactions with each other.
Once a domain model is created, developers can use it to guide the architecture of the rest of the software. This includes the creation of Bounded Contexts, which are areas of software defined by a specific language and context, and Aggregates, which are collections of related entities that are treated as a single unit.
Real-world example: E-commerce platform
Let’s illustrate Domain-Driven Design with an example of an e-commerce platform:
Problem domain: E-commerce
Domain entities: Refers to the subject area or problem space that the software application is addressing.
- Customer: Represents a registered user with attributes like name, email, and shipping address.
- Order: Represents a customer’s purchase request with details such as items, quantities, and total price.
- Product: Represents items available for sale with attributes like name, description, and price.
Value objects: Objects that represent characteristics or attributes without their own identity (e.g., Money, Address).
- Money: Represents a monetary amount with properties like currency and amount.
- Address: Represents a physical location with attributes like street, city, state, and postal code.
Bounded contexts: Defines explicit boundaries within which a particular domain model applies. Different bounded contexts may have their own models and terminologies, reflecting different perspectives or subsystems of the overall domain.
- Order Management Context: Focuses on managing orders, including order creation, modification, and fulfillment.
- Customer Management Context: Manages customer profiles, authentication, and address management.
Services:
- PaymentService: Manages payment processing and integration with external payment gateways.
- ShippingService: Handles logistics and shipment tracking for orders.
Repositories:
- CustomerRepository: Manages persistence and retrieval of customer information.
- OrderRepository: Handles storage and retrieval of order data.
7. Component-based
In software engineering, component-based architecture (CBA) is a software design and development approach that emphasizes reusable software components. The idea of CBA is to make software development more efficient and effective by splitting complex systems into smaller, more manageable components.
Software component is a modular, self-contained unit of software that can be reused in different systems. Components typically have well-defined interfaces that specify how other components interact with them. The interface includes information about the component’s inputs, outputs, and behavior.
Components can be classified based on their functionality, such as user interface components, data access components, and business logic components. Each type of component plays a specific role in a software system and can interact with other components through its interfaces.
Each component encapsulates a set of functionalities and interacts with other components through well-defined interfaces. This architecture promotes modular design, reusability, and flexibility in software development.
Key concepts of component-based software architecture:
1. Components:
- Self-contained units of software that encapsulate specific functionalities or services.
- Components can be implemented in different programming languages and technologies as long as they conform to the defined interface.
2. Interfaces:
- Define the contract or API that components expose to interact with other components.
- Interfaces specify the methods, parameters, and data structures used for communication between components.
3. Composition:
- Components are assembled or composed together to build larger systems or applications.
- Composition can be static (compile-time) or dynamic (run-time), depending on how components are instantiated and connected.
4. Reuse:
- Components promote code reuse by encapsulating common functionalities that can be utilized across different applications or projects.
- Reuse reduces development time and effort by leveraging existing components instead of building everything from scratch.
Let’s illustrate Component-Based Software Architecture with an example from Java Enterprise Edition (Java EE):
Example: Java EE web application
1. Components:
- Servlets: Handle HTTP requests and generate dynamic web content.
- EJBs (Enterprise JavaBeans): Provide business logic and transaction management.
- JSP (JavaServer Pages): Templates for generating HTML responses.
2. Interfaces:
- Servlet API: Defines methods for handling HTTP requests and responses.
- EJB Interfaces: Specify remote and local interfaces for invoking business methods.
- JSP Tag Libraries: Define tags and attributes for embedding Java code in HTML pages.
3. Composition:
- Web Application Deployment Descriptor (web.xml): Specifies how servlets, filters, and other components are configured and composed.
- Dependency Injection (e.g., CDI — Contexts and Dependency Injection): Manages dependencies between components dynamically at runtime.
4. Reuse:
- Standard Components: Java EE provides standard components like servlets, EJBs, and JSPs that can be reused across different web applications.
- Custom Components: Developers can create custom components (e.g., custom servlets, EJBs) and reuse them in multiple projects.
8. Service-oriented architecture (SOA)
SOA is an architectural style designed to create modular, reusable services that can be easily integrated with other services to create a larger system. In this approach, services expose their functionality through interfaces, which can be accessed by other services or applications.
At its core, SOA is about building software by breaking it into smaller components or modules. This modular approach allows developers to focus on building specific functionality and integrating it with other parts to create a larger system.
Core components of SOA
Service Provider: A service provider is responsible for creating and exposing services for use by the outside world. These services may be used by other services, applications or end users. For example, a payment processing service provider can create and expose a service that allows other applications to process payments.
Service Registry: A service registry is a directory of available services that can be accessed by other services or applications. The service registry provides information about services, such as name, location, and interface. For example, if an application needs to process payments, it can use the service registry to find the payment processing service and access its interface.
Service Requester: The service requester is responsible for consuming the services exposed by the service provider. This can be done by using the service registry to find the appropriate service and then calling its interface. For example, an application can use the service registry to find a payment processing service and then use its interface to process payments.
9. Monolithic
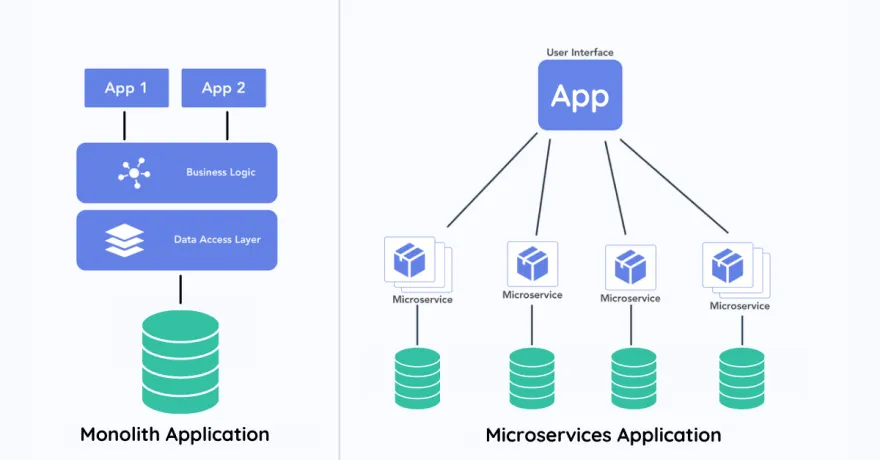
Monolithic architecture is a software design style that has been around for decades. It is a way of building an application as a single, cohesive unit, rather than breaking it into individual, smaller components.
In a monolithic architecture, the entire application is built as a single, self-contained unit. All code and dependencies are packaged together so the application can be deployed and run on a single server.
This makes developing and deploying applications easy because everything is in one place. It also makes it easier to scale horizontally by adding more servers.
Advantages of monolithic architecture
One of the biggest advantages of monolithic architecture is its simplicity. Since everything is contained in one unit, there are fewer moving parts to focus on. This makes developing, testing and deploying applications easier.
Another advantage is that monolithic applications are easier to maintain and debug. Since everything is in one place, it’s easier to track down issues and fix them.
Disadvantages of monolithic architecture
One of the biggest disadvantages of a monolithic architecture is that it can be difficult to scale an application vertically. Since everything is running on a single server, the application is limited in the amount of traffic it can handle.
Another disadvantage is that it is difficult to adopt new technologies and languages within a monolithic application. Since everything is packaged together, it’s difficult to update a single component without breaking the entire application.
10. Microservices
Microservices architecture is a software architecture style that builds applications as a set of small, independent services that communicate with each other over a network. Each service focuses on a specific business capability and can be developed, deployed, and scaled independently of other services in the system.
The main idea of microservices architecture is to split a large, monolithic application into smaller, more manageable services. This approach brings many benefits, such as improved scalability, increased flexibility, and faster rollout of new features.
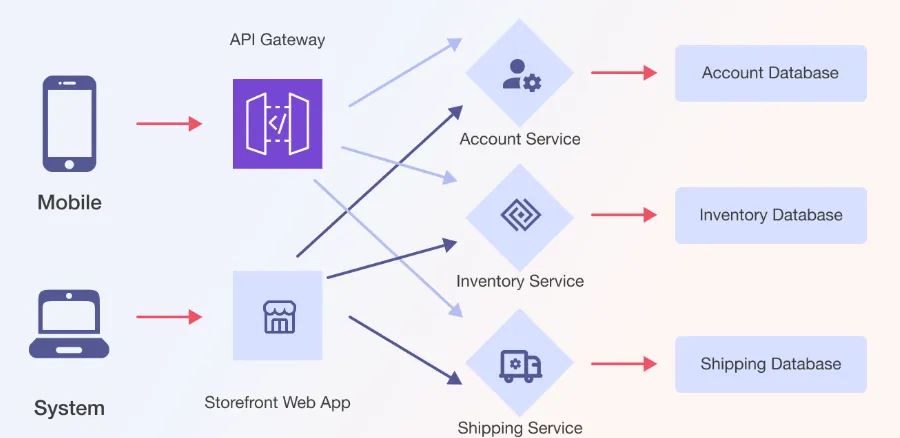
In a microservices architecture, each service can scale independently, making it easier to handle traffic spikes or changes in demand. Developers can also modify or add new services without affecting other parts of the system, speeding up the development process.
Challenges of microservice architecture
While microservices architecture brings many benefits, it also introduces additional complexity. One of the biggest challenges is managing communication between services. Services need to be able to discover each other and communicate efficiently, which can be difficult at scale. In a microservices architecture, load balancing and fault tolerance are also more complex.
Another challenge is ensuring each service has its own data store. In a monolithic application, all data is usually stored in a database. In microservices, each service should have its own data store to ensure that changes to one service do not affect other services in the system. This can lead to increased complexity in data management and synchronization.
1. Distributed system complexity:
- Challenge: Microservices architecture transforms a monolithic application into a distributed system, introducing complexities such as network latency, distributed transactions, and eventual consistency.
- Mitigation: Use technologies like service discovery (e.g., Consul, Eureka), API gateways (e.g., Zuul, Kong), and distributed tracing (e.g., Zipkin, Jaeger) to manage communication and monitoring between microservices.
2. Service orchestration and choreography:
- Challenge: Coordinating interactions between multiple microservices, either through orchestration (centralized control) or choreography (decentralized control), can become complex.
- Mitigation: Prefer choreography over orchestration where possible to reduce coupling and improve scalability. Use event-driven architectures and messaging queues (e.g., Kafka, RabbitMQ) for asynchronous communication between services.
3. Data management:
- Challenge: Each microservice may have its own database, leading to data consistency challenges and difficulty in managing transactions across services.
- Mitigation: Apply the principles of Domain-Driven Design (DDD) to define bounded contexts and establish clear boundaries between services. Consider using event sourcing and CQRS (Command Query Responsibility Segregation) to manage data consistency and scalability.
4. Deployment and operations:
- Challenge: Managing the deployment and operation of a large number of microservices can be challenging, requiring robust DevOps practices and automation.
- Mitigation: Implement containerization (e.g., Docker) and container orchestration (e.g., Kubernetes) for consistent deployment and scaling of microservices. Use CI/CD pipelines and infrastructure-as-code (IaC) tools to automate deployment and configuration management.
5. Testing and monitoring:
- Challenge: Testing microservices in isolation and ensuring end-to-end functionality across distributed systems can be complex. Monitoring individual microservices and correlating logs for troubleshooting is also challenging.
- Mitigation: Adopt a microservices testing strategy that includes unit testing, integration testing (using mock services or containers), contract testing (e.g., using tools like Pact), and end-to-end testing. Implement centralized logging and distributed tracing for effective monitoring and debugging.
6. Security:
- Challenge: Securing microservices and managing access control across distributed systems pose challenges such as enforcing consistent authentication, authorization, and protection against potential security vulnerabilities.
- Mitigation: Implement security best practices such as using API gateways with authentication and authorization mechanisms (e.g., OAuth 2.0, JWT tokens), encrypting communication between services (e.g., TLS/SSL), and regularly auditing and updating security configurations.
Best practices for microservices architecture
To ensure the success of microservices-based systems, developers should follow best practices for designing and implementing microservices. Some of these best practices include:
- Design Services Around Business Capabilities: Use Domain-Driven Design (DDD) principles to define bounded contexts and design microservices based on business capabilities, ensuring clear separation of concerns and autonomy.
- Design loosely coupled, highly cohesive services with clear boundaries and well-defined interfaces.
- Use containerization technology such as Docker to package and deploy each service as a separate container. This makes it easy to scale and deploy individual services as needed.
- Implement effective monitoring and management tools to ensure the smooth operation of your system and to quickly detect and resolve issues.
- Use a service mesh, such as Istio, to manage communication and load balancing between services.
- Implement continuous integration and deployment (CI/CD) pipelines to automate testing and deployment of microservices.
- Implement Resilience Patterns: Design for failure by implementing resilience patterns such as circuit breakers (e.g., Hystrix), retries, timeouts, and fallbacks to handle temporary failures and degraded services gracefully.
- Monitor, Measure, and Scale: Implement comprehensive monitoring and logging across microservices to gain visibility into performance metrics, errors, and trends. Use metrics to make informed decisions on scaling and optimizing microservices.
- Using the 12-Factor Approach for Microservices.
11. Event driven
Event-driven architecture (EDA) is a method of designing software systems that enables fast and efficient communication between different components or services. In this paradigm, different software components communicate with each other through events rather than through direct requests or responses.
Key concepts in event-driven architecture:
- Events: These are notifications or signals that something of interest has happened. Events can range from user actions (like clicking a button) to system-generated notifications (like data updates or errors).
- Event sources (producers): Components or services within the system that generate events and publish them to a broker or a central event bus.
- Event consumers (subscribers): Components or services that are interested in certain types of events and subscribe to them. They receive events from the event bus or broker.
- Event Broker (or Event Bus): Middleware component that manages the routing and delivery of events from producers to consumers. It decouples event producers from event consumers, allowing for more flexible and scalable architectures.
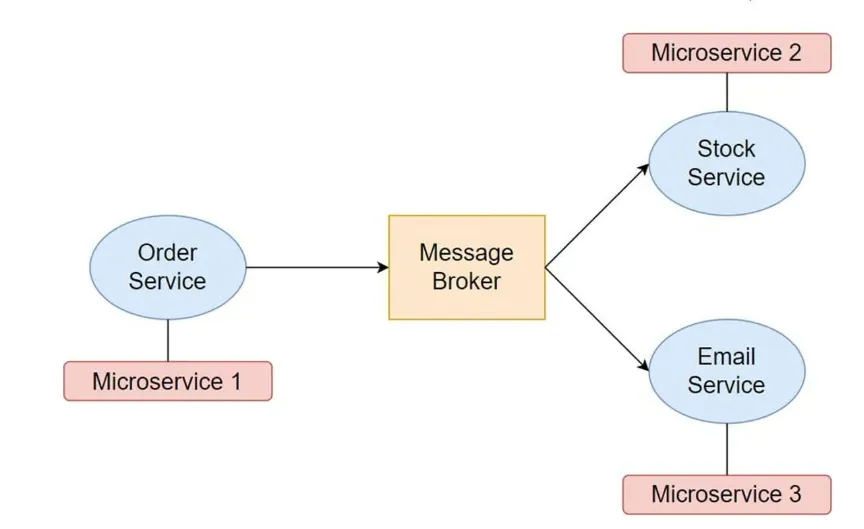
For example, consider a simple e-commerce application. When a new order is placed, the order processing service can generate an “order created” event, which is then broadcast to other services such as inventory management, shipping, and billing. Each service can handle events and make updates to its respective systems.
An excellent real-world example of event-driven architecture is the Uber Engineering case study. Uber uses EDA to handle various aspects of its platform:
- Event Sources: Uber’s system generates events for ride requests, driver availability updates, GPS location updates, and payment transactions.
- Event Consumers: Different services within Uber subscribe to these events. For example, the driver matching service consumes ride request events to find available drivers, while the billing service consumes payment events to process transactions.
- Event Bus: Uber uses Apache Kafka as its event bus, which allows for scalable and reliable event streaming across various services.
Benefits of being event driven
A key benefit of event-driven architecture is its ability to decouple the different components of a software system. When different components communicate through events rather than direct requests, they have less dependence on each other. This makes it easier to change or update individual components of the system without affecting other parts of the system.
Another benefit of event-driven architecture is scalability. Because events are broadcast to multiple components of the system, large amounts of data and transactions can be processed in parallel. This makes it easier to handle high traffic and demand spikes.
Challenges of event-driven architecture
Although event-driven architecture has many benefits, there are also some challenges. One of the major challenges is managing the complexity of event-driven systems. Because events can be generated and consumed by many different components, tracking and debugging problems that arise can be difficult.
Another challenge is ensuring that events are processed in the correct order. Because events can be generated and processed asynchronously, events may not be processed in the correct order. This can lead to problems such as data inconsistencies or calculation errors.
12. Stream based
As software development becomes more complex and the need for scalability increases, traditional architectures become increasingly inadequate. Stream-based architectures have emerged as a promising alternative, enabling developers to build systems capable of processing large amounts of data in real-time.
Stream-based architecture is a design approach where data is continuously processed as it flows through a system. This architecture relies on the concept of data streams, which are sequences of data records (events or messages) that are produced, transmitted, and consumed in real-time or near real-time. Stream-based architectures are particularly suited for handling large volumes of data, enabling real-time processing, and supporting applications that require low-latency responses.
At its core, stream-based architecture is based on the principles of event-driven programming. Instead of processing data in batches, stream-based systems process the data generated in real-time. This enables developers to build systems that respond to data changes with minimal latency.
Key concepts in stream-based architecture:
- Data streams: Continuous flows of data records (events, messages) that are generated by various sources and consumed by applications or services.
- Stream processing: The real-time or near real-time processing of data streams, where computations and transformations are applied as data flows through the system.
- Event time processing: Handling data based on the time when events occur, which is crucial for maintaining correct order and ensuring temporal consistency in stream-based applications.
- Stateful processing: Maintaining state across data records within a stream, which allows for complex analytics, pattern detection, and aggregations.
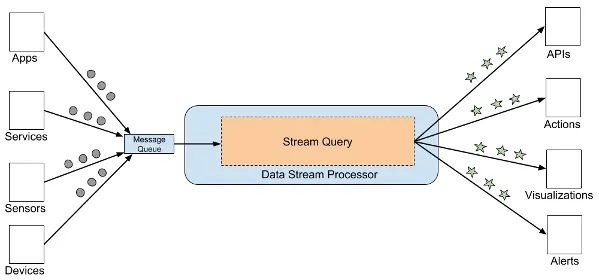
An exemplary real-world application of stream-based architecture is Twitter’s real-time analytics platform. Twitter processes millions of tweets every day and uses stream-based architecture to analyze and derive insights from these tweets in real-time:
- Data streams: Each tweet generated by users serves as a data event in the stream.
- Stream processing: Twitter employs technologies like Apache Storm or Apache Flink to process these streams in real-time. They perform tasks such as sentiment analysis, trending topic detection, and user engagement analytics.
- Scalability: Twitter’s architecture scales horizontally to handle increasing volumes of tweets and users, ensuring that the real-time analytics remain responsive and efficient.
Reasons for using stream-based architecture:
- Real-time insights: Stream-based architecture enables applications to process and analyze data as it arrives, providing real-time insights and responses to events.
- Scalability: Systems built on stream-based architecture can handle large volumes of data and scale horizontally by adding more processing nodes.
- Low latency: By processing data in real-time, stream-based architectures support low-latency applications where immediate responses are required.
- Continuous processing: Streams facilitate continuous processing of data, which is essential for applications such as real-time analytics, fraud detection, and IoT data processing.
Another benefit of stream-based architecture is flexibility. Because data is processed in real time, systems can be built that respond to changes in data with minimal latency. This makes it possible to build complex, event-driven systems that can adapt to changing business needs. For example, in an e-commerce platform, a stream-based architecture can be used to track user activities in real time and provide personalized recommendations and promotions based on the user’s browsing and purchase history.
Additionally, stream-based architecture can lead to significant cost savings. Traditional batch processing processes require expensive hardware and complex software infrastructure to manage data processing. Stream-based systems can be built on cheap, general-purpose hardware, making expansion and maintenance easier.
Finally, stream-based architectures are highly fault-tolerant. Because data is processed in real time, it is possible to build systems that can automatically recover from failures without manual intervention. This makes it possible to build systems that operate at scale with high reliability, reducing the risk of data loss or system downtime.
13. Serverless architecture pattern
Serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. In this model, developers focus on writing code and deploying individual functions or services, without worrying about the underlying infrastructure.
Key characteristics of serverless architecture:
- Event-driven: Functions (serverless components) are triggered by events such as HTTP requests, database changes, file uploads, or scheduled tasks.
- Auto-scaling: Automatically scales to match the exact demand, from a few requests per day to thousands per second, without manual intervention.
- Pay-per-use: Billing is based on the actual resources consumed by the function execution, rather than pre-allocated server instances.
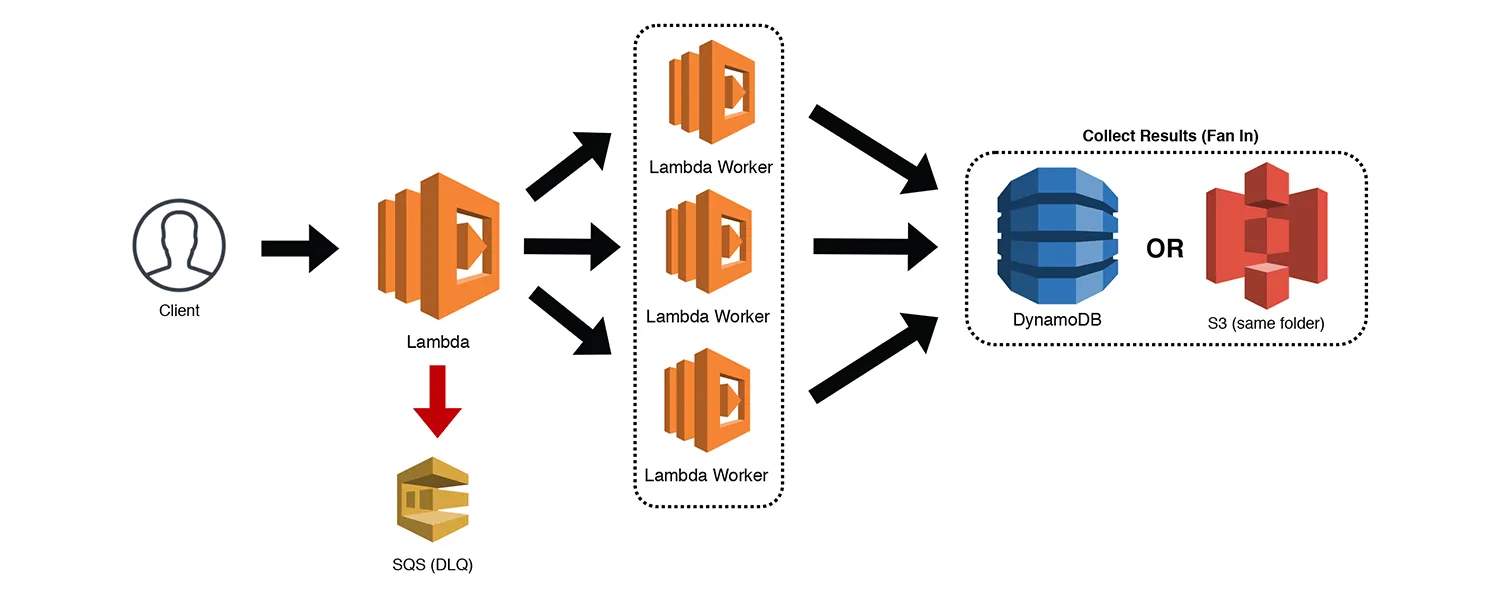
Real-world example and use-case: Image processing service
Imagine you’re developing an application that allows users to upload images, apply filters, and save the edited versions. Here’s how you might use serverless architecture to implement this:
- Upload event: When a user uploads an image, an event is triggered. This event could be managed by a cloud provider’s service like AWS Lambda, Google Cloud Functions, or Azure Functions.
- Function execution: A serverless function is invoked in response to the upload event. This function could be responsible for: 1) Resizing the image to multiple sizes for thumbnails, previews, and full-resolution versions. 2) Applying filters or transformations to the images based on user preferences.
- Integration with services: Each function can interact with other cloud services, such as storage (like AWS S3, Azure Blob Storage) to store processed images or databases (like DynamoDB, Firestore) to store metadata.
- Scalability: As more users upload images or request processing, the serverless architecture automatically scales by spinning up additional instances of the function to handle the increased load. There’s no need for manual intervention to manage server provisioning.
- Cost efficiency: You only pay for the actual compute time used by each function execution. If there are periods of low activity, costs are minimized because there are no idle servers consuming resources.
14. CQRS: Command Query Responsibility Segregation pattern
The Command Query Responsibility Segregation (CQRS) pattern separates a service’s write tasks from its read tasks. While reading and writing to the same database is acceptable for small applications, distributed applications operating at web-scale require a segmented approach. Typically there’s more read activity than write activity. Also, read activity is immutable. Thus, replicas dedicated to reading data can be spread out over a variety of geolocations. This approach allows users to get the data that closest to them. The result is a more efficient enterprise application.
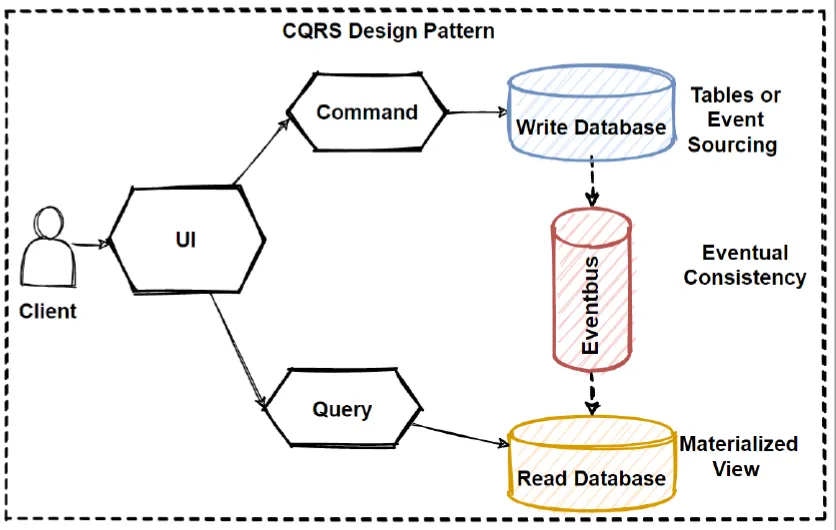
Advantages of CQRS
- Separating write activity from ready activities allows you to use the best database technology for the task at hand, for example, a SQL database for writing and a non-SQL database for reading.
- Read activity tends to be more frequent than writing, thus you can reduce response latency by placing read data sources in strategic geolocations for better performance.
- Separating write from read activity leads to more efficient scaling of storage capacity based on real-world usage.
Disadvantages of CQRS
- Supporting the CQRS pattern requires expertise in a variety of database technologies.
- Using the CQRS patterns means that more database technologies are required hence there is more inherent cost either in terms of hardware or if a cloud provider is used, utilization expense.
- Ensuring data consistency requires special consideration in terms of Service Level Agreements (see the CAP theorem).
- Using a large number of databases means more points of failure, thus companies need to have comprehensive monitoring and fail-safety mechanisms in place to provide adequate operation.
15. Throttling architecture pattern
The Throttling pattern, also known as Rate Limiting, is one in which a throttle is placed in front of a target service or process to control the rate at which data flow into the target. Throttling is a technique that ensures that the flow of data being sent into a target can be digested at an acceptable rate. Should the target become overwhelmed, the throttle will slow down or even stop calls to the target.

Throttling pattern controls how fast data flows into a target. It’s often used to prevent failure during a distributed denial of service attack or to manage cloud infrastructure costs. To use this pattern successfully, you need good redundancy mechanisms in place, and it’s often used alongside the circuit breaker pattern to maintain service performance.
Client-side throttling will control the rate at which calls are made to commercial services that calculate fees according to usage activity. Thus, the Throttling pattern is used as a cost-control mechanism.
16. Sharding architecture pattern
The Sharding pattern segments data in a database to speed commands or queries. It ensures storage is consumed equally across instances but demands a skilled and experienced database administrator to manage sharding effectively.
The Sharding pattern is when a datastore is separated from a single storage instance into multiple instances called shards. Data is then divided according to some form of sharing logic. Queries are executed against the shards. It’s up to the database technology implementing the shards to perform the queries in an optimized manner.
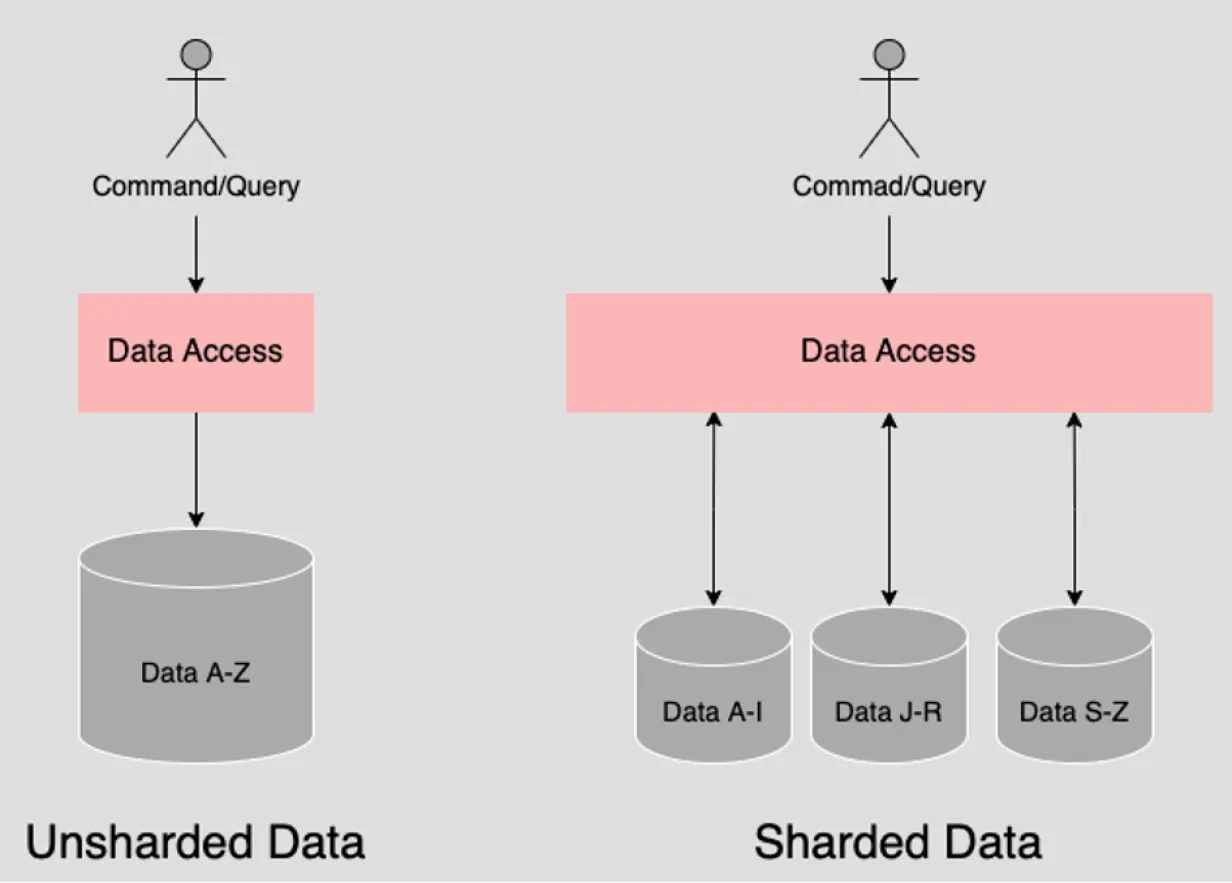
Another type of sharding separates data according to a segmentation logic that ensures that disk capacity is consumed equally among all instances.
17. Static Content Hosting architecture pattern
The Static Content Hosting pattern is used to optimize webpage loading time. It stores static content (information that doesn’t change often, like an author’s bio or an MP3 file) separately from dynamic content (like stock prices). It’s very efficient for delivering content and media that doesn’t change often, but downsides include data consistency and higher storage costs.
The Static Content Hosting pattern is one in which static content is separated from dynamic content and stored over a variety of geographic locations in a manner that is optimized for fast access. An example of static content is a web page written in HTML that has data that changes slowly, for instance, an author’s biography. Another example is an mp4 file associated with a movie. An example of dynamic content is data that is fast-changing and is composed on the fly when requested. An example of dynamic data is a list of current stock prices.
18. Strangler architecture pattern
The Strangler pattern is one in which an “old” system is put behind an intermediary facade. Then, over time external replacement services for the old system are added behind the facade.
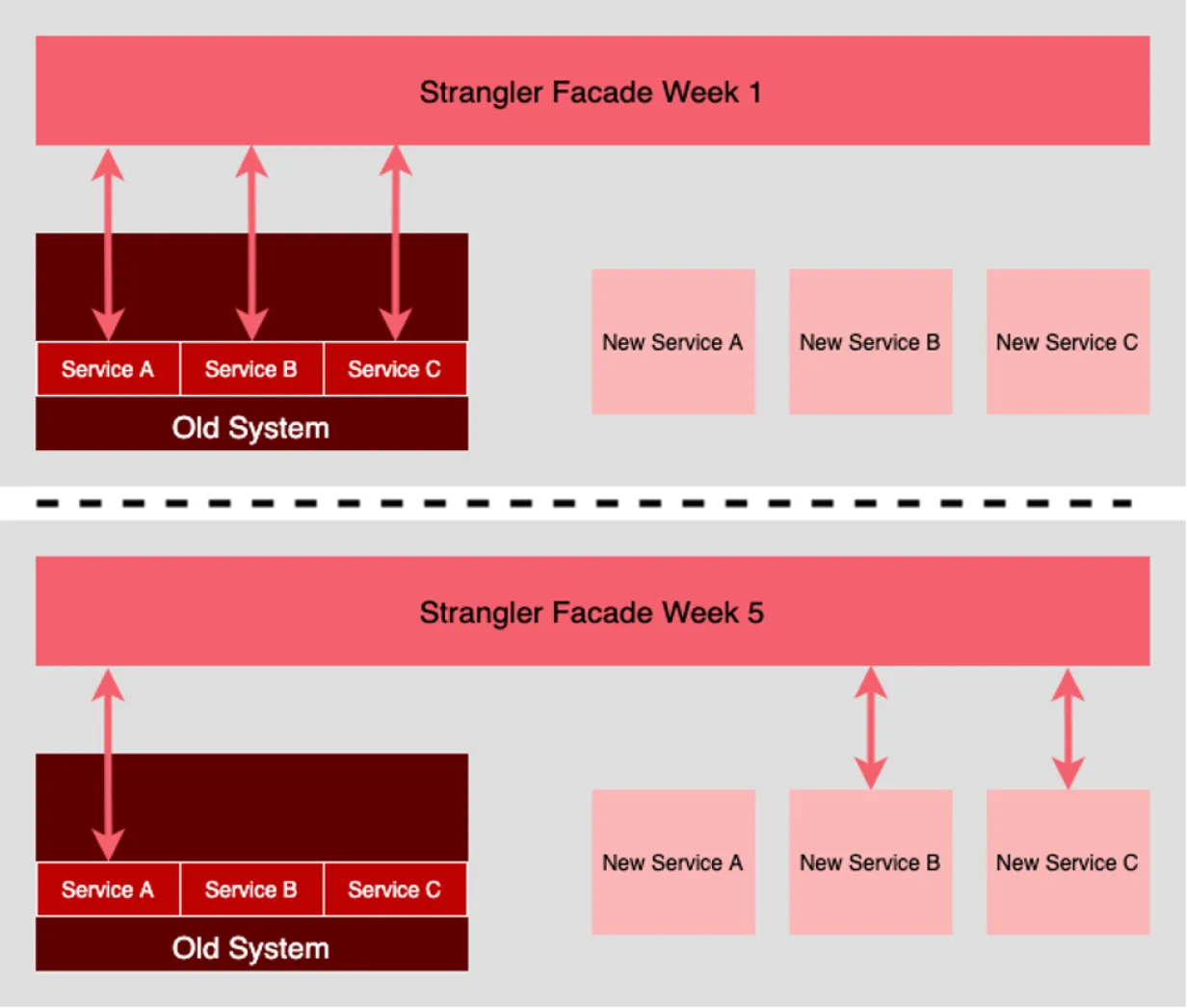
The facade represents the functional entry points to the existing system. Calls to the old system pass through the facade. Behind the scenes, services within the old system are refactored into a new set of services. Once a new service is operational, the intermediary facade is modified to route calls that used to go to the service on the old system to the new service. Eventually, the services in the old system get “strangled” in favor of the new services.
Summary
Software architecture is critical to building successful software systems that meet the needs of users and stakeholders. It provides a blueprint for designing and developing software systems, ensuring that the system meets its functional and non-functional requirements, promoting adaptability, and helping to manage complexity. Therefore, it is crucial to invest time and resources at the beginning of a software development project to design a robust architecture. Hope this article can be of some help to you.