In a Microservices Architecture, services typically collaborate with each other to serve business use cases. These services may have their own software characteristics in terms of Availability, Scalability, Elasticity, etc. but there will always be a situation when the downstream service you are trying to communicate with is either not available — may be because of a planned downtime, temporary network outage, etc. or is available but is responding slow because of some reason.
In such cases, how the dependent consumer services react is very important? Ideally, the expectation would be to have these dependent services be robust in nature and should be able to handle such issues gracefully. But if they are not resilient, then you are impacting the availability of the functionality these services are responsible for.
And this is what we are trying to address in this blog — Patterns to make a Microservice Resilient!!!
Pattern #1 — Timeout
In a Distributed System, when one service makes a request to another downstream service, it takes time for the roundtrip to complete and is not instant in nature. But, if the downstream service is responding slower than usual or may be its not responding at all, how long should the caller service wait for the response before it concludes saying — something is wrong so let me take an alternate path if available. And this alternate path could be a graceful failure also.
If you wait too long to decide then it can slow down the caller service. If you give up too early, then chances are that things could have worked but you went too aggressive and declared it failed. And if you don’t have any timeouts configured then the caller service can come to a hang state very soon, impacting all features it is responsible for.
Let’s see this with an example — A Content Microservice handling use cases of Content Creation and Content Promotion.
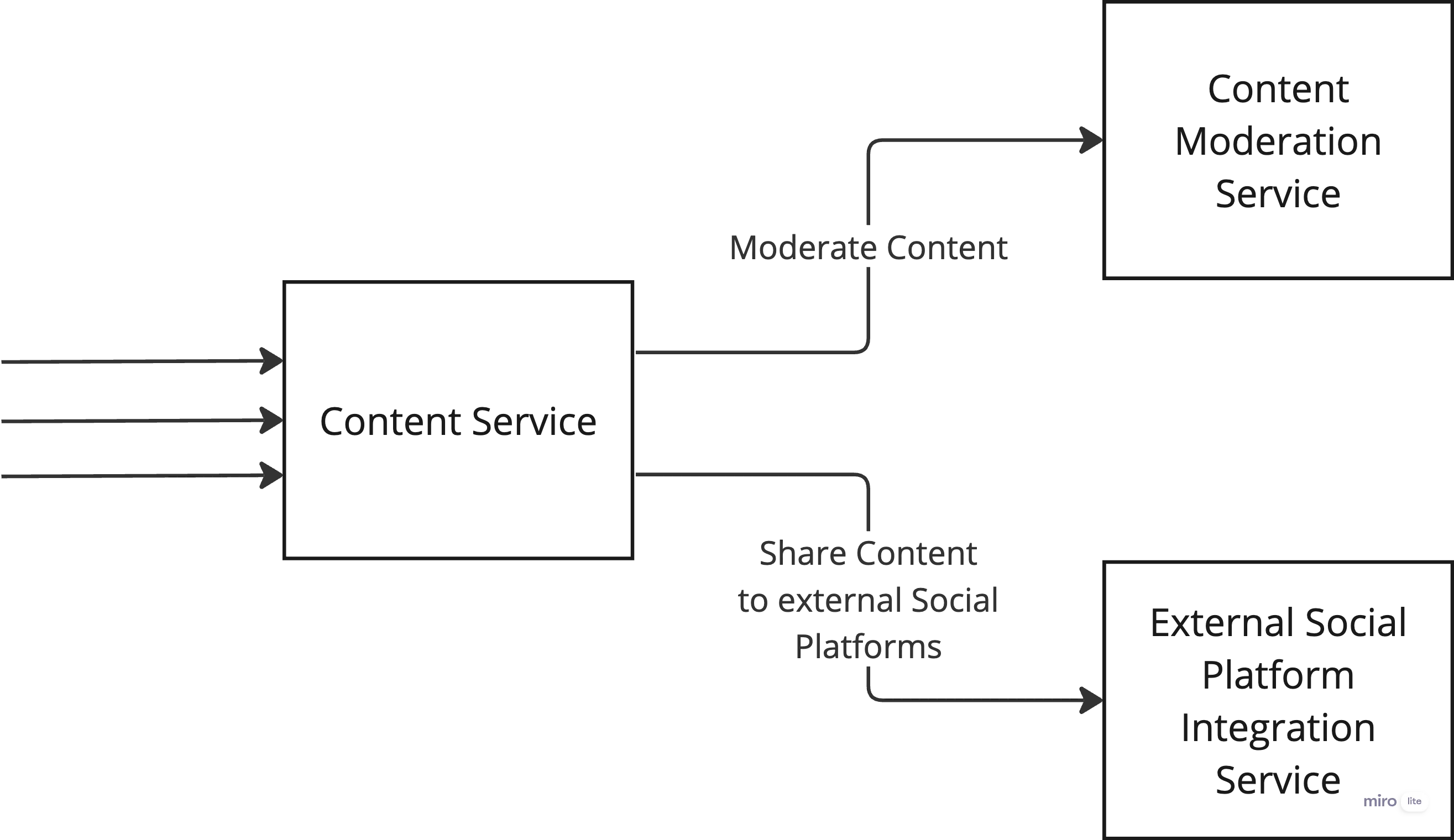
Content Creation and Promotion features of Content Service
In this case, while creating a new content, if the Content Moderation service takes time to respond, then it will impact the content creation time. With more and more requests coming for content creation, the system resources will be blocked waiting for the response from the Content Moderation service, eventually leading to resource contention. And because of resource crunch, if someone tries to perform Share Content use case, because of resource crunch, the Content service will not be able to handle the request despite the External Social Platform Integration service is up and running fine.
In this case, asynchronous communication could have worked better but the synchronous communication is shown just to explain the Timeout issue.
Ok, I get that but how do you hit that sweet spot of when to time out? Well it depends on quite a few things —
- Understand the context in which the external call is made. If there is a Service Level Objective (SLO) of 3 seconds for content creation in above case, then the timeout cannot be more than 3 seconds for Content Moderation request to respond back.
- If a use case overall has a SLO of 5 seconds and the implementation calls more than one API call then plan for the timeouts on individual API calls such that it does not exceed the overall SLO of 5 seconds.
- The amount of time to wait can also be calculated depending on the context in which the call is invoked. Example — if Content Moderation has SLO of 3 seconds and if the Content Moderation API call is invoked after 1 second then all you are left with is 2 seconds of timeout for Content Moderation request before the overall transaction timeout.
- Observe the p90 or p95 latency for the external API calls and set the timeout accordingly.
Pattern #2 — Retries
If a downstream service fails to respond then you may want to handle the situation by retrying the operation in case the problem happens to be temporary and a retry might just work.
There could be reasons for the service not responding:
- A new version of the downstream service might be getting deployed when you made the request for the first time and hence it failed to respond
- There could be a temporary network glitch
- Maybe the API Gateway/Proxy service is too overloaded to relay the request to the target service.
But how do you decide if a retry will help or should you always retry? It depends on the response you received from the initial call. For instance:
- If it just timeout then it might help.
- Assuming you are making HTTP requests, if you happen to get a HTTP 502 or 504 status code then it might also help to retry.
- If you get HTTP status code 500 or maybe status code 404 then it does not make sense to retry.
By the way, when doing a retry, do consider the context in which this operation is to be made. From our Content creation use case above, if the overall SLO is 3 seconds then you may want to retry the Content Moderation API if it fails for some reason but you will have to ensure enough that the number of retries should not exceed the overall time you have set for the Content creation timeout.
Pattern #3 — Bulkheads
It’s a pattern to isolate a failure in a specific section of the functionality, in an attempt to ensure that rest of the service features are not affected.
It resembles the Bulkhead design we have in Ships — in case a Ship springs a leak, we can close the bulkhead doors of that section ensuring that specific problematic area of the ship is not usable but rest of the Ship continues to work as expected.
And the idea here is very simple:
- Create a pool of worker threads for each downstream service you want to connect to
- Configure the maximum concurrent calls which can be made using the pool
- Let the consumer service use this pool to make requests to external service and if the pool is full with no free worker thread, wait for sometime or fail immediately depending on the use case.
- With this we ensure that all the system resources are not getting choked because of malfunction of a single downstream service and other healthy downstream services can be invoked from other features offered by the service.
If we try to apply this pattern in our Content Service, it would look something like below:
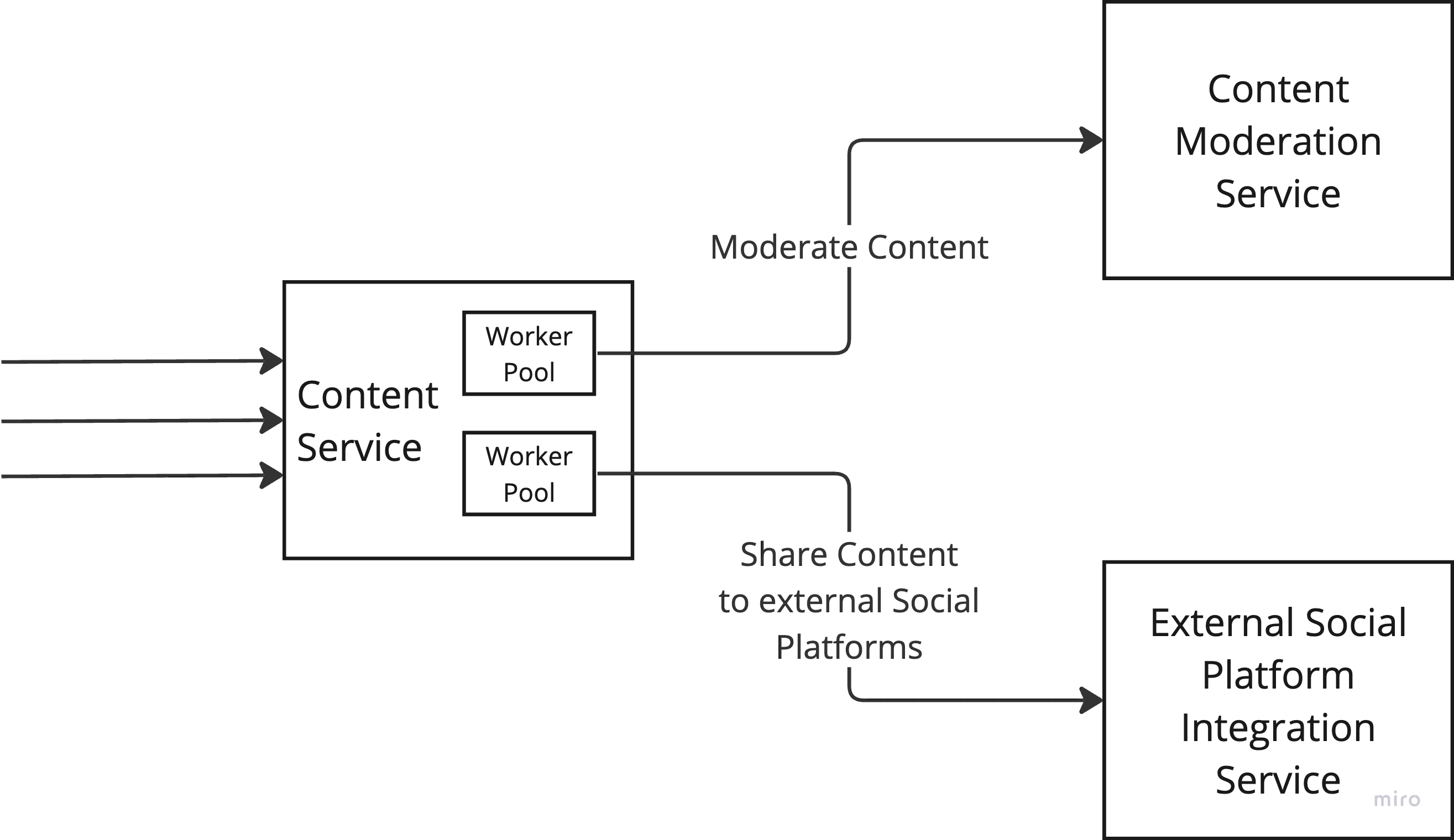
Content Service with Bulkhead Pattern
Pattern #4 — Circuit Breakers
A widely used pattern to implement Resilient Microservices. The idea is very much similar to the Electrical Circuit breaker we have at our homes — a sudden spike in the power supply simply blows up the circuit breaker, ensuring the appliances are safe.
In the Microservices world as well, if a downstream service is struggling to respond back to the consumer services, then it makes sense for consumer services not to further bombard the downstream service with more and more requests and let the downstream service recover from the situation by not making requests for some time.
If consumer service continues to make requests to the downstream in this case, it will have to wait for the timeout to happen. And with more and more requests waiting for the timeout, the system resources will be choked to handle other use cases. So it perfectly makes sense for the consumer services to Fail Fast provided they know the downstream service is not able to handle the requests. And this is where the Circuit Breaker pattern helps.
By the way — even if the consumer services have implemented the Timeout pattern to handle the slow response, no response or error response from the downstream service, the new requests still continues to be sent to the downstream service making it more worse for the already struggling downstream service to recover.
The idea of Circuit Breaker pattern is very simple — keep an eye on the number of consecutive requests failing when invoking a downstream service. If this number crosses a threshold value then Open the Circuit — meaning, don’t make any more requests to the downstream service and fail fast. Give a breather to the downstream service to recover. And after a certain period of time, make few attempts to invoke downstream service and if you get successful response then Close the Circuit — meaning all subsequent requests continues to go to the downstream service.
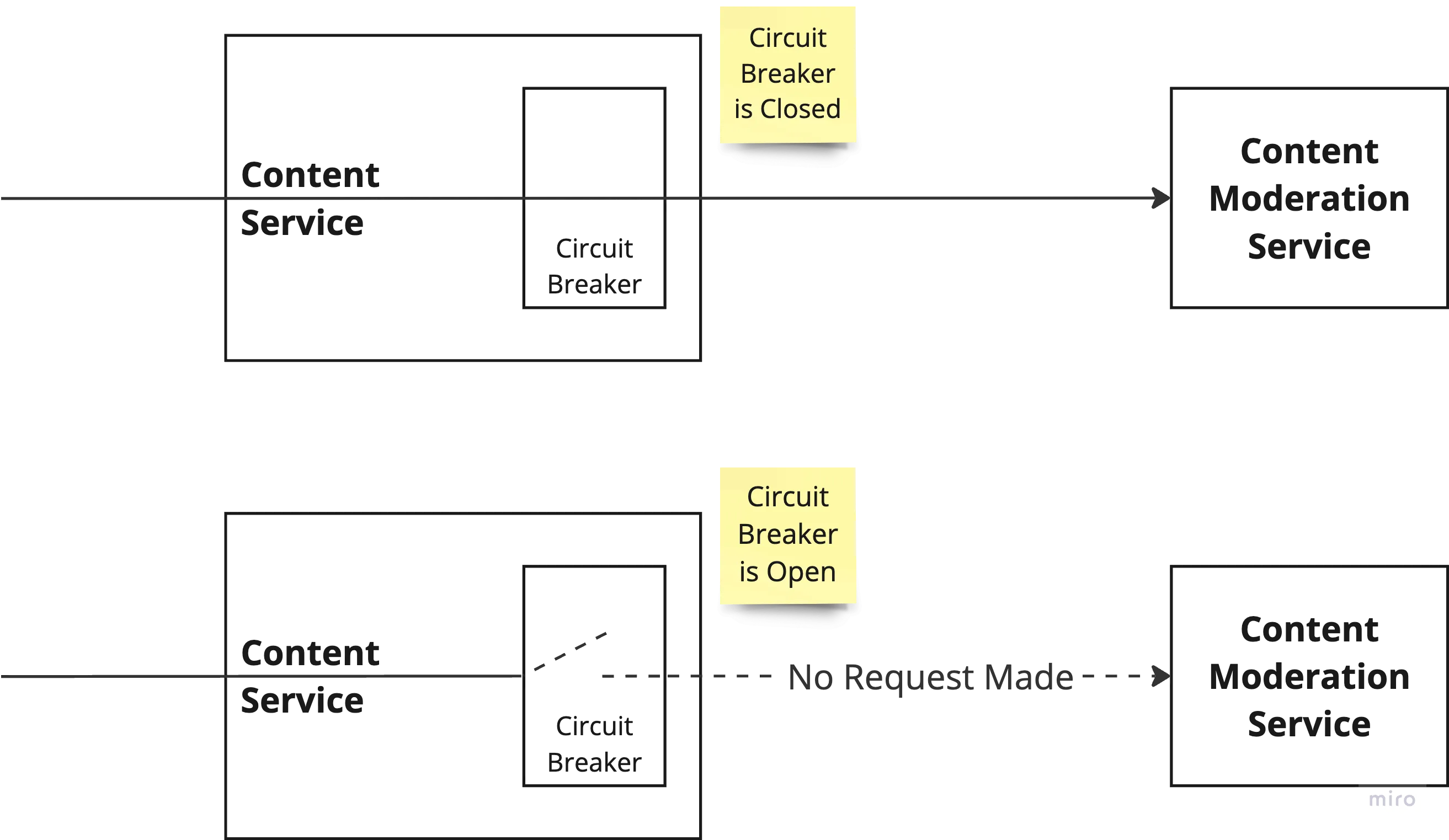
Circuit Breaker with Closed and Open State
Configuring the values for when to close the circuit and when to retry with an intention of closing the circuit could be tricky. You may want to start with sensible default values and then continue to tweak the values case by case.
Crux here is to detect the failure -> fail fast -> handle the request gracefully and keep the system resources free to handle the rest of the use cases where this downstream service is not in the path.
Pattern #5 — Redundancy
As the name says — having a redundant copy of something always helps to embrace Resiliency. This redundant copy may be working in an active-active mode along with the main instance to serve the requests or could be lying idle in a stand-by mode to take over the requests when the main instance fails for some reason.
If you are running more than one instance of a downstream microservice, and if one instance goes down, the consumer services are not impacted as there are other instances available to handle the requests. It might result in slow response and throughput but the system will continue to work. And you could have enough automation in place to launch a new instance and hence within a few seconds or may be minutes, the throughput of the downstream service can resume to the full. Another example could be — having a Stand-by Database. If the primary Database fails, then the Stand-by Database can take the role of a primary and hence helps to failover quickly.
Redundancy also helps you to ensure High Availability and Scalability of the services. But there is a cost involved. The more redundant copies you want to have, the more cost you have to shell. So we need to strike a balance here.
As they say, things will always fail, eventually. So you can either put your energy to ensure it does not fail or channelize the same energy to ensure the system is resilient enough to handle the failure and has the capability to recover from the failure fast and adapts itself to ensure the same failure is handled gracefully should it occur again.
Hope this blog has given enough details on the patterns to implement to embrace Resiliency in a Microservice Architecture. So if you are not using these patterns in your architecture yet, it’s time to bake them in :)