После весны 2020 года слово “тестирование” приобрело некоторые неожиданные значения и неоднозначные коннотации — пожалуй, везде, кроме IT. В нашей сфере без него никуда — и так было всегда.
Видов тестирования ПО — множество: модульное, функциональное, А/В-тестирование, интеграционное, нагрузочное и т д. И на наш взгляд, как раз последнее является как самым важным, так и наиболее сложным. Ведь если ошибки, которые могут быть выявлены с помощью A/B-тестов, модульных, функциональных и интеграционных тестов, проявляются практически сразу после “выкатки” новой версии приложения, то проблемы, на выявление которых нацелено нагрузочное тестирование, — “спящие”. И обнаруживаются они только тогда, когда на новую версию вашего сайта или приложения придет реальный пользовательский трафик, с которым не справится “софтверная” часть проекта (база данных, application-сервер) или “железно-инфраструктурная” (нехватка оперативной памяти в кластере, большая нагрузка на дисковую подсистему при операциях чтения-записи).
В этой статье расскажем и покажем, как мы проводим, пожалуй, эталонное нагрузочное тестирование — в плане полноты покрытия и полноты получаемого в итоге отчёта. Наши наработки вполне воспроизводимы, так что вы можете воспользоваться ими для улучшения работы собственного проекта.
Что? Где? Когда?
Когда необходимо:
- нужна оценка текущего лимита производительности проекта (например, перед какими-то промо-акциями, рассылками, “черной пятницей” и т д) — чтобы оценить объём временного наращивания мощности и изменения в конфигурации проекта на период акции;
- вы ищете пути повышения производительности текущей архитектуры/инфраструктуры (поиск проблемных мест / “бутылочного горлышка”) на постоянной основе;
- нужно проверить новый проект перед запуском в продакшн или новую инфраструктуру после переезда.
Что включено:
- аудит текущей инфраструктуры,
- составление сценариев нагрузочного тестирования и выбор инструментов для его проведения,
- проведение нагрузочного тестирование,
- составление отчета о результатах с рекомендациями по решению выявленных проблем.
Где смотреть:
- технологический стек — с помощью каких инструментов, ЯП, фреймворков работает проект: это может быть как типичный монолитный веб-сайт на LAMP/LEMP-стеке, так и микросервисный проект, состоящий из 30 сервисов, написанных на различных ЯП (typescript, golang, python…); используется ли какое-либо дополнительное ПО (системы кэширования, системы полнотекстового поиска и т.д.)
- рабочие мощности — это железные сервера или облачные ВМ с подключенным автомасштабированием, managed кластер Kubernetes и т.д.
- хранение данных (как БД, так и загружаемые пользовательские файлы) — используется ли on-premise или managed база данных, настроена ли репликация (запись в мастер / чтение со слэйва) и т д. Где хранятся загружаемые пользовательские данные — локальный диск, s3-хранилище и т.д.
- взаимодействие компонентов проекта между собой — как они связаны, какие подсистемы используются и в каком порядке обрабатывают входящий пользовательский запрос; если проект построен на микросервисной архитектуре — как сервисы общаются между собой; существуют ли какие-либо внешние зависимости (API платежного шлюза, сервис для email-рассылок), и если да — как осуществляется коммуникация с этими сервисами.
- вспомогательные компоненты — настроены ли у проекта мониторинг, система сбора логов и трейсов, которые могут быть полезны в процессе нагрузочного тестирования для получения дополнительных данных и инсайтов.
Аудит инфраструктуры помогает лучше понять логику работы проекта, а также сразу найти возможные узкие места, например, синхронный запрос к платежной системе во время оплаты заказа в интернет магазине; отсутствие системы кеширования для статичного контента (страница на новостном портале, включая дополнительный раздел “по этой же теме”). А данные из имеющихся систем мониторинга и сбора логов используем для улучшения сценариев тестирования и поиска узких мест.
Сценарии тестирования и выбор инструментов
Сценарии
В идеальном мире сценарии тестирования должны полностью имитировать пользовательское поведение на сайте — переходы по страницам, процедуры авторизации и аутентификации, сброс и смену пароля, добавление/удаление товаров в корзину, оформление заказа и т д.
Когда мы проводили нагрузочное тестирование для “Тотального диктанта”, в сценариях описывали следующие процессы:
- аутентификация пользователя на сайте,
- заполнение и промежуточное сохранение диктанта,
- отправка диктанта на проверку.
Самые частые в нашей практики варианты формирования конечного сценария таковы:
- заказчик сам формулирует набор сценариев, которые необходимо реализовать — самый идеальный и простой путь :-)
- сценарии формируются совместно нашими специалистами с командой заказчика — например, если тестирование запланировано перед промо-акцией или регулярной сезонной нагрузкой, и набор критериев более-менее понятен.
- заказчик хочет тестирование, но не может точно сформулировать критерии — в этом случае мы анализируем access-логи веб-сервера, например, за последний месяц, отбрасываем из них запросы к статическим файлам и формируем из них набор сценариев для тестирования, тем самым покрывая большую часть поведения пользователей на сайте.
Инструменты
Apache JMeter — инструмент для проведения нагрузочного тестирования, разрабатываемый Apache Software Foundation. Хотя изначально JMeter разрабатывался как средство тестирования web-приложений, в настоящее время он способен проводить нагрузочные тесты для JDBC-соединений, FTP, LDAP, SOAP, JMS, POP3, IMAP, HTTP и TCP. Интересна возможность создания большого количества запросов с помощью нескольких компьютеров при управлении этим процессом с одного из них. Архитектура поддерживает плагины сторонних разработчиков, что позволяет дополнять инструмент новыми функциями.
Более тяжеловесный и требовательный к ресурсам инструмент, но обладающий и более широкой функциональностью: позволяет добавлять в http-запросы куки, заголовки (например, для авторизации), парсить страницы для получения значения тех или иных переменных и использования их в последующих запросах; в конечном итоге, даёт возможность полностью эмулировать работу браузера. Мы используем JMeter тремя способами:
- ручное заполнение плана запросов (добавление урлов, заголовков и т д),
- импорт из curl (забираем из консоли разработчика в браузере),
- прокси (направляем трафик из браузера через JMeter, вручную “прокликиваем” сайт, JMeter на основе этих данных сам составляет план тестирования).
Из минусов — нет встроенных графиков, приходится дополнительно конфигурировать связку с Grafana (что, впрочем, делается довольно легко). Из плюсов — большое комьюнити + большое количество плагинов для тестирования чего угодно (можно использовать JMeter для генерирования потоковых данных для Apache Kafka и дальнейшей обработки через Apache Spark).
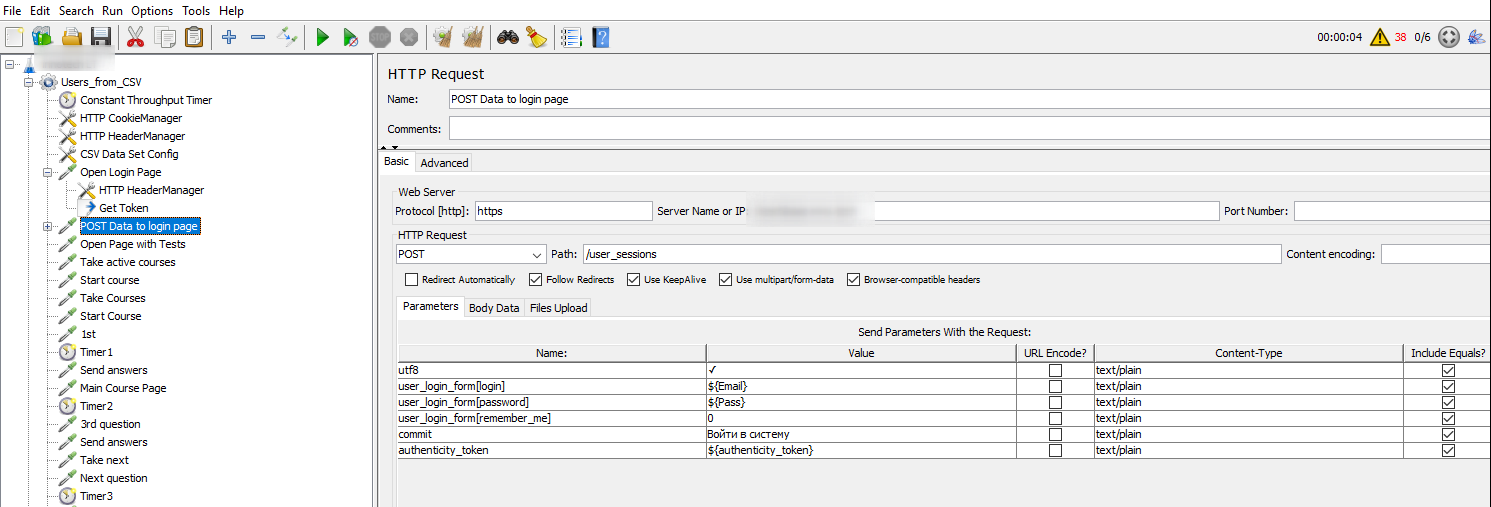
Пример конфигурации JMeter для процесса залогинивания
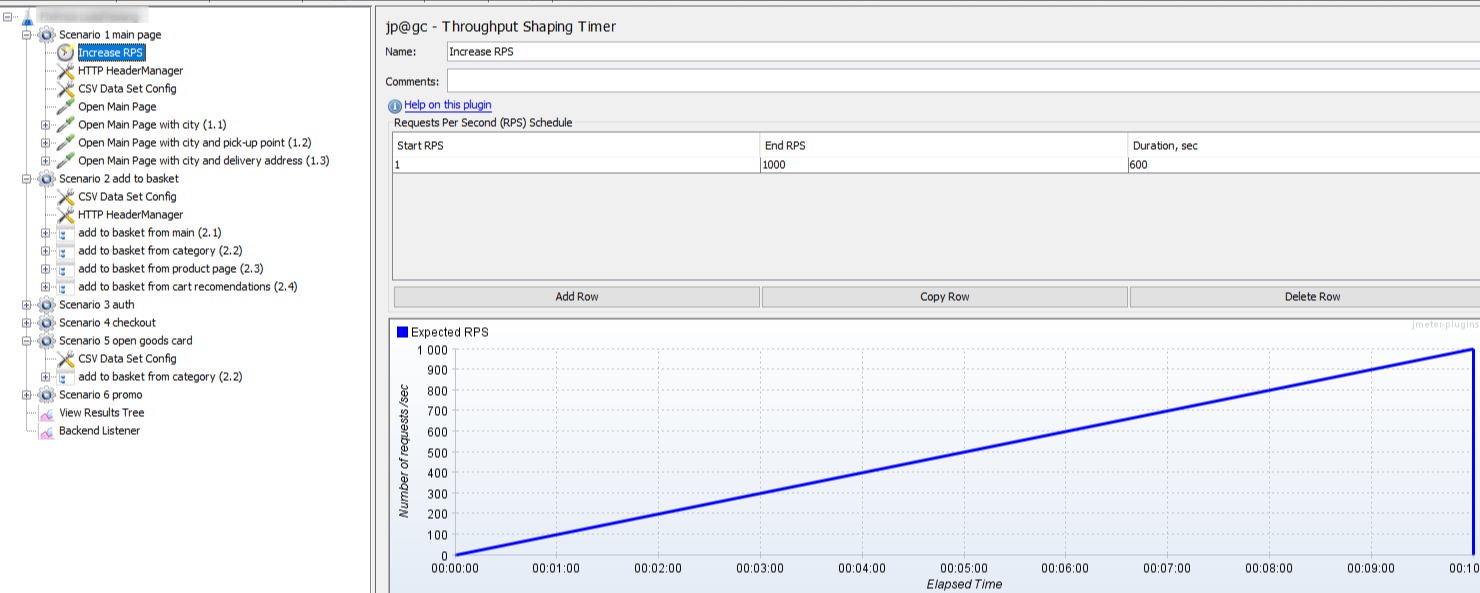
Пример конфигурации JMeter для увеличения RPS
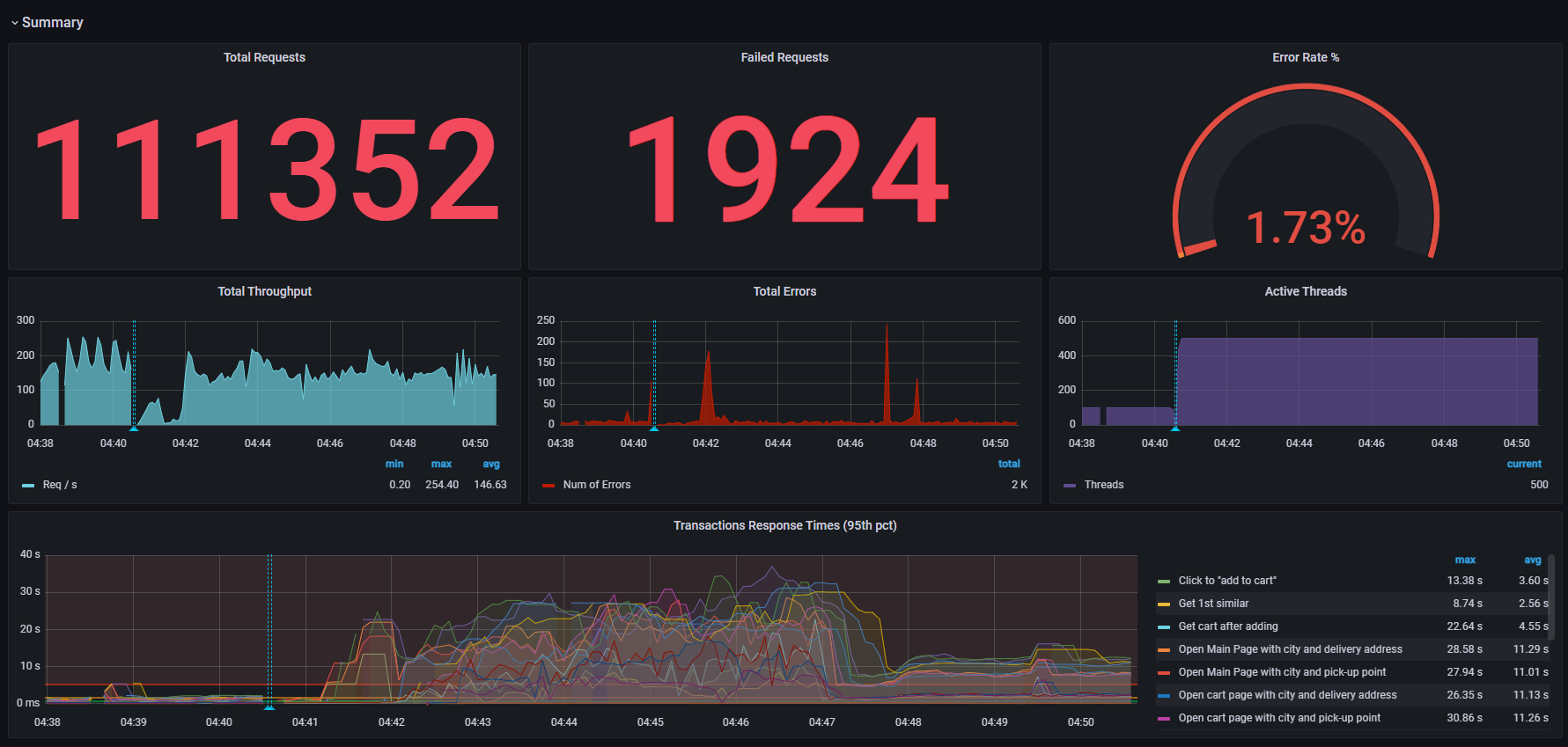
Примеры графиков/таблиц из настроенной Grafana для Jmeter
Самотестирование и отчёты
После подготовки сценариев и выбора инструментов настаёт очередь самого простого — с организационной точки зрения, но самого ответственного — точки зрения результата. Да, речь про саму процедуру нагрузочного тестирования. Так как основная его цель — это оценка производительности именно production-окружения, перед запуском тестов необходимо выполнить следующие действия:
- согласовать технологическое окно для тестирования — выбирается время, при котором система будет находится под минимальной нагрузкой от живых пользователей (обычно это промежуток между ночью и ранним утром) и во время которого не будет происходить каких-либо импортов, рассылок, снятия бэкапов и т.д.
- координация с разработчиками / ops-ами — во время тестирования, во-первых, не должно вестись никаких работ по проекту со стороны заказчика (например, деплоя новой версии); во-вторых, в процессе нагрузочного тестирования сайт может полностью “упасть” и необходимо иметь под рукой recovery-план / возможность быстро найти источник проблемы и устранить его.
В результате нагрузочного тестирования на выходе мы получаем набор графиков — зависимости времени ответа страницы от RPS входящей нагрузки и утилизации ресурсов в зависимости от RPS, — исходя из которых в финальном отчете мы показываем как текущие возможности/лимиты системы, так и рекомендации по увеличению производительности проекта. Эти рекомендации могут относиться уровню инфраструктуры (отсутствие механизмов автомасштабирования, проблемы на уровне сети) и к уровню архитектуры и кодовой базы (неоптимизированные SQL-запросы, отсутствие индексов в БД, устаревшее ядро bitrix; неоптимальное распределение операций чтения/записи между master/slave БД).

Пример из отчета с рекомендациями по оптимизации SQL-запросов
Ниже приведены примеры с рекомендациями по результатам нагрузочного тестирования.
На данный момент рекомендации по результатам тестирования:
а) Снизить таймауты в node bitrix-frontend-app, чтобы клиент не ожидал по 60 секунд до появления ошибки 504 и тем самым не забивались коннекты.
б) Нарастить параметры для vault, чтобы api корректно получал секреты из него, а также не висел в ожидании ответа.
в) Всё-таки исследовать сетевые настройки.
г) Добавить ресурсов imaginary, т.к. при загрузке ресайза изображений он стабильно падает.
д) Скорректировать работу CDN, т.к. даже после завершения тестов он стабильно отдает 502 коды ответа.
е) Поднять уровень логирования в bitrix-frontend для возможности дебага проблем и устранения причин их возникновения.

Дальше мы положили один интересный пример из практики: клиенту нужна была дополнительная образовательная система для обучения сотрудников. Мы проводили нагрузочное тестирование обеих.
Итого:
Площадка 1 имеет проблемы с пропускной способностью сети и нагрузкой на сервер приложений. Среднее время ответа системы (без учета загрузки видео) держится на уровне 5-7 секунд при среднем показателе 260 RPS и без ошибок по таймаутам.
Площадка 2 имеет проблемы с чрезмерной нагрузкой на worker-серверах, и при среднем значении в 205 RPS страницы отдаются существенно дольше.
Также из-за проблем с отдачей js-файла, часть тестовых пользователей не смогла пройти авторизацию и, соответственно, не смогла пройти тестирование вовсе.
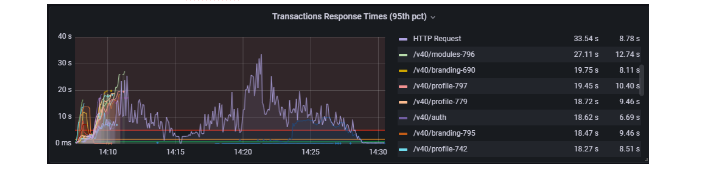
График времени ответа системы.

Количество тестовых пользователей, которые не смогли пройти авторизацию.
В чём польза, брат?
Как и любые профилактические проверки, периодическое нагрузочное тестирование будет, несомненно, позитивно влиять на развитие вашего продукта/сервиса. В идеальном мире, при наличии stage(preprod)-площадки, идентичной продакшну, нагрузочное тестирование можно встраивать непосредственно в процессы CI/CD при выкладке новой версии проекта на препродакшн.
Кроме того, оно помогает выявить ошибки как в архитектуре проекта, так и в его кодовой базе. В нашей практике был интересный пример, когда stage-проект, развернутый в managed-кластере K8s, выдерживал всего лишь 8 RPS, а потом падал вплоть до рестартов всех pod’ов деплоймента. После трех итераций нагрузочного тестирования (с разницей в неделю) производительность выросла до 110 RPS.
Резюмируя: в отличие от различных других тестирований (и не только в IT — см. начало статьи), нагрузочное тестирование — это не просто констатация, “болен” пациент или нет, это тотальное и исчерпывающее исследование проекта на предмет узких мест, которые могут стать причиной отказа сайта или сервиса при росте нагрузки. И, в нашем случае, — ещё и дорожная карта по устранению проблем.
Так что берегите здоровье проекта и не забывайте вовремя его проверять!