Earlier I presented one useful design pattern to migrate to a monolithic application to microservices. This pattern is the Strangler Fig pattern and the article can be found here. Here some other specific microservices design patterns will be presented.
What is a Microservice?
As a reminder and before going into details on the design patterns, let’s review what is a microservice, and the challenges it creates.
A microservice is a small, independently deployable component of a larger application that focuses on a specific functionality. Each microservice runs its own process, communicates with other services typically with APIs, and is designed to be loosely coupled, allowing for easier scaling, development, and maintenance.
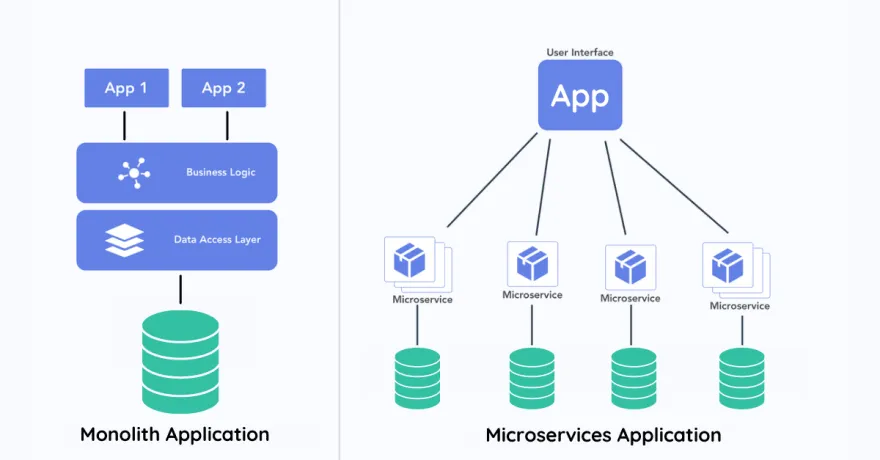
Monolith application vs microservices application from dev.to
Microservices comes with the following main advantages over monolith applications:
- Scalability: Individual microservices can be scaled independently based on demand, optimizing resource usage.
- Flexibility: Different microservices can be developed, tested, deployed, and maintained using different technologies.
- Faster development: Smaller, focused teams can work on separate microservices concurrently, speeding up development cycles and release times.
- Resilience: Failures in one microservice are isolated and less likely to affect the entire system, improving overall reliability.
- Easier maintenance: Smaller codebases for each microservice are easier to understand, modify, and debug, reducing technical debt.
- Flexible to outsourcing: Intellectual property protection can be a concern when outsourcing business functions to third-party partners. A microservices architecture can help by isolating partner-specific components, ensuring the core services remain secure and unaffected.
On the other hand, it comes with some challenges:
- Complexity: Developing and maintaining a microservices-based application typically demands more effort than a monolithic approach. Each service requires its own codebase, testing, deployment pipeline, and documentation.
- Inter-service communication: Microservices rely on network communication, which can introduce latency, failures, and complexities in handling inter-service communication.
- Data management: Distributed data management can be challenging, as each microservice may have its own database, leading to issues with consistency, data synchronization, and transactions.
- Deployment overhead: Managing the deployment, versioning, and scaling of multiple microservices can require sophisticated orchestration and automation tools like Kubernetes.
- Security: Each microservice can introduce new potential vulnerabilities, increasing the attack surface and requiring careful attention to security practices.
The following design patterns are mainly designed to solutionate some of the challenges of microservices:
Let’s look at them in more details.
Database Per Service Pattern
The Database per Service pattern is a design approach in microservices architecture where each microservice has its own dedicated database. Each database is accessible only via its microservice own API. The service’s database is effectively part of the implementation of that service. It cannot be accessed directly by other services.
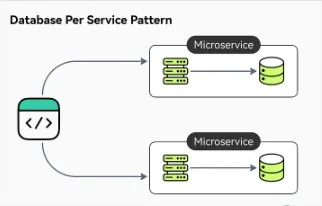
Database Per Service Pattern from ByteByteGo
If a relational database is chosen, there are 3 ways to keep the data private to other databases:
- Private tables per service: Each service owns a set of tables that must only be accessed by that service
- Schema per service: Each service has a database schema that’s private to that service
- Database server per service: Each service has it’s own database server.
Here are the main benefits to use this pattern:
- Loose coupling: Services are less dependent on each other, making the system more modular.
- Technology flexibility: Teams can choose the best database technology, chosing a proper database size, for their specific service requirements for each microservice.
A design pattern always comes with trade offs, here are some challenges that are not solved with this pattern:
- Complexity: Managing multiple databases, including backup, recovery, and scaling, adds complexity to the system.
- Cross-service queries: Hard to implement queries for data spread across multiple databases. API gateway or Aggregator pattern can be used to tackle this issue.
- Data consistency: Maintaining consistency across different services’ databases requires careful design and often involves other patterns like Event sourcing or Saga pattern.
API Gateway Pattern
The API Gateway pattern is a design approach in microservices architecture where a single entry point (the API gateway), handles all client requests. The API gateway acts as an intermediary between clients and the microservices, routing requests to the appropriate service, aggregating responses, and often managing cross-cutting concerns like authentication, load balancing, logging, and rate limiting.
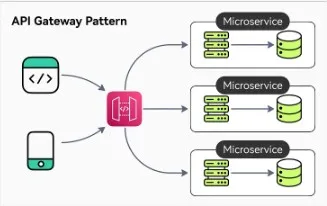
API Gateway Pattern from ByteByteGo
Here are the main advantages of using an API Gateway in a microservice architecture:
- Simplified client interaction: Clients interact with a single, unified API instead of dealing directly with multiple microservices.
- Centralized management: Cross-cutting concerns are handled in one place, reducing duplication of code across services.
- Improved security: The API gateway can enforce security policies and access controls, protecting the underlying microservices.
Here are the main drawbacks:
- Single point of failure: If the API gateway fails, the entire system could become inaccessible, so it must be highly available and resilient.
- Performance overhead: The gateway can introduce latency and become a bottleneck if not properly optimized when scaling.
Backend For Frontend Pattern
The Backend for Frontend (BFF) pattern is a design approach where a dedicated backend service is created for each specific frontend or client application, such as a web app, mobile app, or desktop app. Each BFF is designed to respond to the specific needs of its corresponding frontend, handling data aggregation, transformation, and communication with underlying microservices or APIs. The BFF pattern is best used in situations where there are multiple front-end applications that have different requirements.
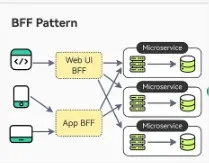
BFF Pattern from ByteByteGo
Here are the benefits of such a pattern:
- Optimized communication with frontends: Frontends get precisely what they need, leading to faster load times and a better user experience.
- Reduced complexity for frontends: The frontend is simplified as the BFF handles complex data aggregation, transformation, and business logic.
- Independent evolution: Each frontend and its corresponding BFF can evolve independently, allowing for more flexibility in development.
However, this pattern comes with these drawbacks:
- Complexity: Maintaining separate BFFs for different frontends adds to the development and maintenance complexity.
- Potential duplication: Common functionality across BFFs might lead to code duplication if not managed properly.
- Consistency: Ensuring consistent behavior across different BFFs can be challenging, especially in large systems.
Command Query Responsibility Segregation (CQRS)
The CQRS pattern is a design approach where the responsibilities of reading data (queries) and writing data (commands) are separated into different models or services. The separation of concerns enables each model to be tailored to its specific function:
- Command model: Can be optimized for handling complex business logic and state changes.
- Query model: Can be optimized for efficient data retrieval and presentation, often using denormalized views or caches.
Communication between the read and the write services can be done in several ways like message queues or by using Event sourcing pattern described below.
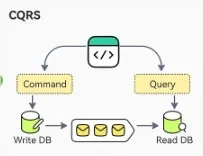
CQRS Pattern from ByteByteGo
Here are the main benefits of the CQRS pattern:
- Performance optimization: Each model can be optimized for its specific operations, enhancing overall system performance.
- Scalability: Read and write operations can be scaled independently, improving resource utilization.
- Maintainability: By separating command and query responsibilities, the codebase becomes more organized and easier to understand and modify.
Here are the challenges with this pattern:
- Complexity: The need to manage and synchronize separate models for commands and queries add complexity to the system.
- Data consistency: Ensuring consistency between the command and query models, especially in distributed systems where data updates may not be immediately propagated, can be challenging.
- Data synchronization: Synchronizing the read and write models can be challenging, particularly with large volumes of data or complex transformations. Techniques such as event sourcing or message queues can assist in managing this complexity.
Event Sourcing Pattern
The Event Sourcing pattern captures state changes as a sequence of events, stored in an event store instead of directly saving the current state. This event store acts like a message broker, allowing services to subscribe to events via an API. When a service records an event, it is sent to all interested subscribers. To reconstruct the current state, all events in the event store are replayed in sequence. The last process can be optimized using snapshots to avoid replaying every events but only the last ones.
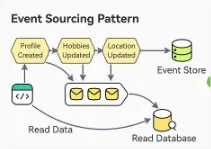
Event Sourcing Pattern from ByteByteGo
Here are the main benefits of event sourcing pattern:
- Audit trail: Provides a complete history of changes, which is useful for auditing, debugging, and understanding how the system evolved over time.
- Scalability: By storing only events, write operations can be easily scaled. This allows the system to handle a high volume of writes across multiple consumers without performance concerns.
- Evolutivity: Easy addition of new functionality by introducing new event types, as the business logic for processing events is separated from the event storage.
It comes with these drawbacks:
- Complexity: The need to manage event streams and reconstruct state can be more complex than a traditional approach, also there is a learning curve to master this practice.
- Higher storage requirements: Event Sourcing usually demands more storage than traditional methods, as all events must be stored and retained for historical purposes.
- Complex querying: Querying event data can be more challenging than with traditional databases because the current state must be reconstructed from events.
Saga Pattern
The Saga Pattern is used in distributed systems to manage long-running business transactions across multiple microservices or databases. It does this by breaking the transaction into a sequence of local transactions, each updating the database and triggering the next step via an event. If a transaction fails, the saga runs compensating transactions to undo the changes made by previous steps.
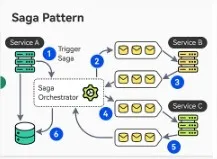
Saga Pattern from ByteByteGo
Here is an illustration example of the saga pattern with the compensating transactions:
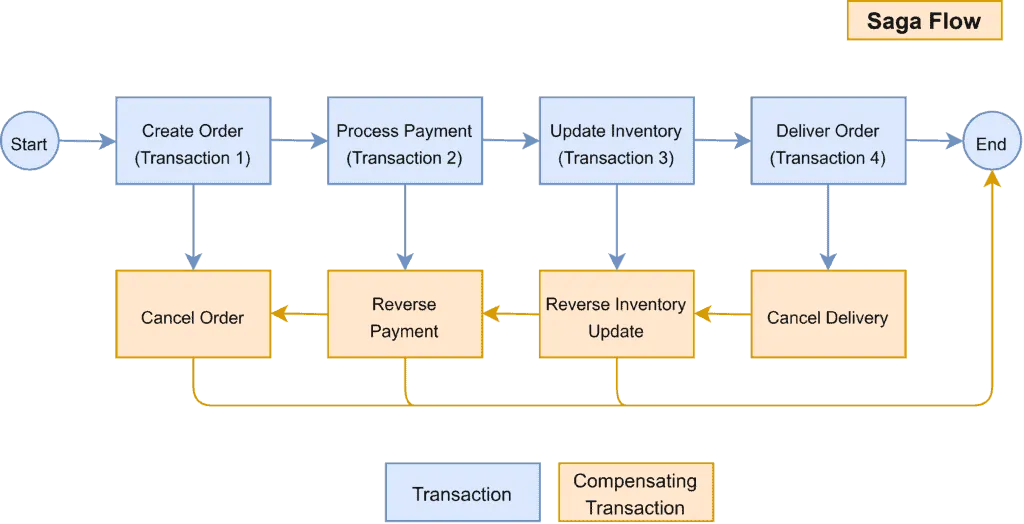
Illustration example of saga pattern with compensating transactions by Baeldung
Sagas can be coordinated in two ways:
Here are the main benefits of the saga pattern:
- Data eventual consistency: It enables an application to maintain data consistency across multiple services.
- Improved resilience: By breaking down transactions into smaller, independent steps with compensating actions, the Saga Pattern enhances the system’s ability to handle failures without losing data consistency.
It comes with its drawbacks:
- Complexity: Implementing the Saga Pattern can add complexity, especially in managing compensating transactions and ensuring all steps are correctly coordinated.
- Lack of automatic rollback: Unlike ACID transactions, sagas do not have automatic rollback, so developers must design compensating transactions to explicitly undo changes made earlier in the saga.
- Lack of isolation: The absence of isolation (the “I” in ACID) in sagas increases the risk of data anomalies during concurrent saga execution.
Sidecar Pattern
The Sidecar Pattern involves deploying an auxiliary service (sidecar), alongside a primary application service within the same environment, such as a container or pod. The sidecar handles supporting tasks like logging, monitoring, or security, enhancing the primary service’s functionality without modifying its code. This pattern promotes modularity and scalability by offloading non-core responsibilities to the sidecar, allowing the primary service to focus on its main functionality.
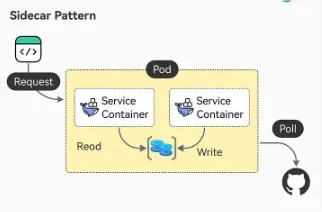
Sidecar Pattern from ByteByteGo
Before going into pros and cons of this pattern, let’s see some use cases of the pattern:
- Logging and monitoring: A sidecar can collect logs or metrics from the primary service and forward them to centralized systems for analysis.
- Security: Sidecars can manage security functions like authentication, authorization, and encryption. Offloading these responsibilities to the sidecar allows the core service to concentrate on its business logic.
Here are the main advantages of this pattern:
- Modularity and extensibility: The Sidecar pattern allows developers to easily add or remove functionalities by attaching or detaching sidecar containers, enhancing code reuse and system maintainability without affecting the core service.
- Isolation of concerns: The sidecar operates separately from the core service, isolating auxiliary functions and minimizing the impact of sidecar failures.
- Scalability: By decoupling the core service from the sidecar, each component can scale independently based on its specific needs, ensuring that scaling the core service or sidecar does not affect the other.
Here comes the main disavantages:
- Increased complexity: Adds a layer of complexity, requiring management and coordination of multiple containers, which can increase deployment and operational overhead.
- Potential single point of failure: The sidecar container can become a single point of failure, necessitating resilience mechanisms like redundancy and health checks.
- Latency: Introduces additional communication overhead, which can affect performance, especially in latency-sensitive applications.
- Synchronization and coordination: Ensuring proper synchronization between the primary service and the sidecar can be challenging, particularly in dynamic environments.
Circuit Breaker Pattern
The Circuit Breaker Pattern is a design approach used to enhance the resilience and stability of distributed systems by preventing cascading failures. It functions like an electrical circuit breaker: when a service encounters a threshold of consecutive failures, the circuit breaker trips, stopping all requests to the failing service for a timeout period. During this timeout, the system can recover without further strain. After the timeout, the circuit breaker allows a limited number of test requests to check if the service has recovered. If successful, normal operations resume; if not, the timeout resets. This pattern helps manage service availability, prevent system overload, and ensure graceful degradation in microservices environments.
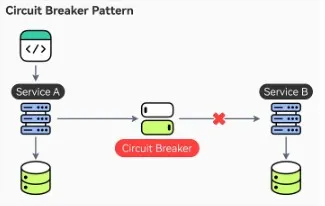
Circuit Breaker Pattern from ByteByteGo
The Circuit Breaker pattern typically operates in three main states: Closed, Open, and Half-Open. Each state represents a different phase in the management of interactions between services. Here’s an explanation for each state:
- Closed: The circuit breaker allows requests to pass through to the service. It monitors the responses and failures. If failures exceed a predefined threshold, the circuit breaker transitions to the “Open” state.
- Open: The circuit breaker prevents any requests from reaching the failing service, redirecting them to a fallback mechanism or returning an error. This state allows the service time to recover from its issues.
- Half-Open: After a predefined recovery period, the circuit breaker transitions to the “Half-Open” state, where it allows a limited number of requests to test if the service has recovered. If these requests succeed, the circuit breaker returns to the “Closed” state; otherwise, it goes back to “Open.”
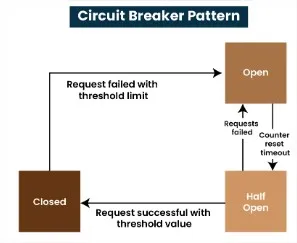
Circuit Breaker Pattern states by GeeksForGeeks
Here are the main benefits of this pattern:
- Prevents cascading failures: By halting requests to a failing service, the pattern prevents the failure from affecting other parts of the system.
- Improves system resilience: Provides a mechanism for systems to handle failures gracefully and recover from issues without complete outages.
- Enhances reliability: Helps maintain system reliability and user experience by managing and isolating faults.
Here are the main challenges that comes in with this pattern:
- Configuration complexity: Setting appropriate thresholds and recovery periods requires careful tuning based on the system’s behavior and requirements.
- Fallback management: Ensuring effective fallback mechanisms that provide meaningful responses or handle requests appropriately is crucial.
Note there exists other design pattern to reduce damage done by failures like the Bulkhead pattern, which isolates different parts of a system into separate pools to prevent a failure in one part from impacting others.
Here is an illustration of how it works:
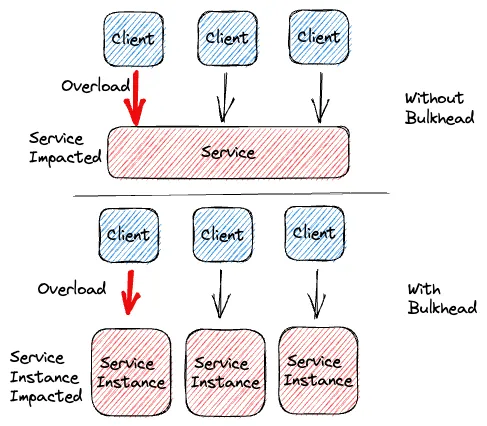
Bulkhead patttern from this Medium article
Anti-Corruption Layer
The Anti-Corruption Layer (ACL) Pattern is a design pattern used to prevent the influence of external systems’ design and data models from corrupting the internal design and data models of a system. It acts as a barrier or translator between two systems, ensuring that the internal system remains isolated from and unaffected by the complexities or inconsistencies of external systems.
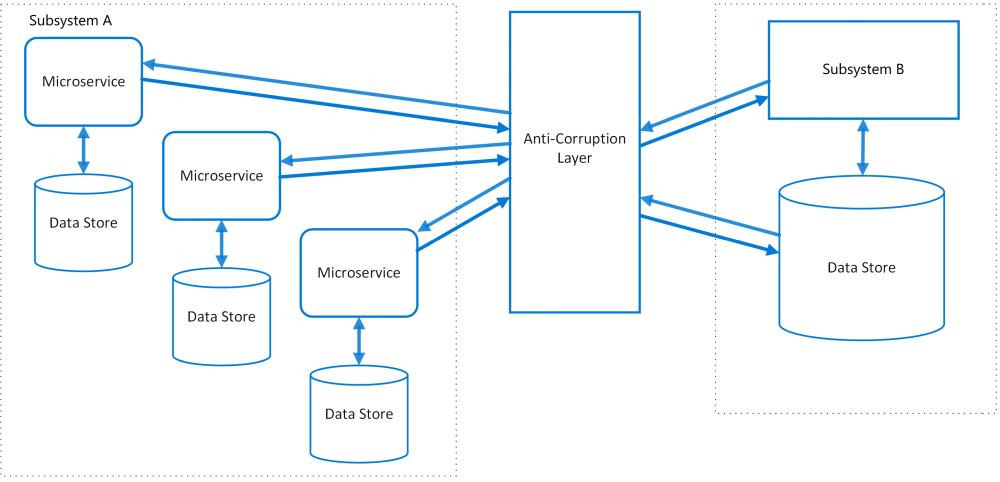
ACL pattern from Microsoft
The design inside the ACL can be represented this way:
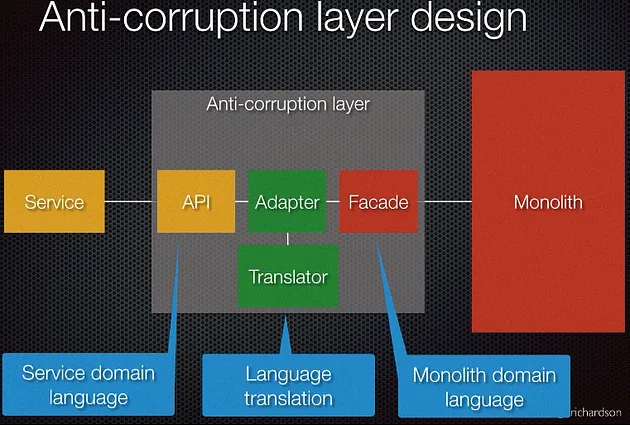
ACL design from this Youtube channel
Here are the main benefits from the ACL pattern:
- Protection: Shields the internal system from external changes and potential corruption.
- Flexibility: Easier integration with external systems by managing differences in data models and protocols.
- Maintainability: Simplifies modifications and updates to either the internal or external systems without affecting the other.
On the other hand, here are the main challenges of the ACL pattern:
- Latency: Latency can be added by calls made between the two systems.
- Scaling: Scaling ACL with many microservices or monolith applications can be a concern for the development team.
- Added complexity: Introduces additional complexity due to the need for translation and adaptation logic.
Aggregator Pattern
The Aggregator Pattern is a design pattern used to consolidate data or responses from multiple sources into a single, unified result. An aggregator component or service manages the collection of data from different sources, coordinating the process of fetching, merging, and processing the data.
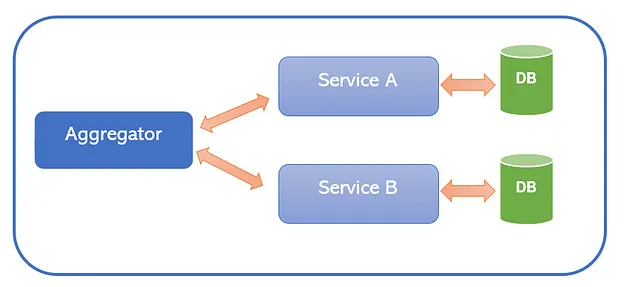
Aggregator Pattern from this Medium article
Here are the main benefits from the Aggregator pattern:
- Simplified client interaction: Clients interact with one service or endpoint, reducing complexity and improving ease of use.
- Reduced network calls: Aggregates data from multiple sources in one place, minimizing the number of calls or requests needed from clients and improving overall efficiency.
- Centralized data processing: Handles data processing and transformation centrally, ensuring consistency and coherence across different data sources.
Here are the drawbacks of this pattern:
- Added complexity: Implementing the aggregation logic can be complex, especially when dealing with diverse data sources and formats.
- Single point of failure: Since the aggregator serves as the central point for data collection, any issues or failures with the aggregator can impact the availability or functionality of the entire system.
- Increased latency: Aggregating data from multiple sources may introduce additional latency, particularly if the sources are distributed or if the aggregation involves complex processing.
- Scalability challenges: Scaling the aggregator to handle increasing amounts of data or requests can be challenging, requiring careful design to manage load and ensure responsiveness.
• • •
Hoping now microservices architecture and its design patterns have no more secrets to you.