
Pagination allows you to retrieve a large number of records split into pages, instead of returning all the results at once. This is especially useful in scenarios where you need to retrieve a large number of records. In this article, I present how to implement OffSet and Keyset pagination in a .NET 8 Web API using Entity Framework Core.
For demonstration purposes, I created a .NET 8 Web API project that uses EF Core and MS SQL Server as a database. The complete project can be found on my GitHub.
Demo project structure
This project is organized in three layers:
- API layer, which contains the
Controllers, Dtos, and project configurations such as Dependency Injection configuration, AutoMapper configuration and the DatabaseSeeder, which is responsible for adding data to the database when the app is executed.
- Domain layer, which contains the
Models classes, the Interfaces and the Service classes.
- Infrastructure layer, which contains the
DbContext and the Repository classes.
Pagination
Pagination is the process of splitting data into pages, and it can be used in scenarios where instead of retrieving all the data at once, you split them into small bunks and retrieve them per page. This makes the performance of your app better, as it’s not necessary to retrieve all the data at once, and it also allows the client to navigate between the data.
There are two ways to implement pagination: the Offset pagination and the Keyset pagination. Each approach has pros and cons and can be used in different scenarios, I’m going to present both approaches and also demonstrate how to implement them.
Offset pagination
The Offset pagination requires two values as input: the page number and the page size, and it will use this information to query the data. It uses the Skip method (FETCH NEXT/OFFSET in SQL) to return the data. This approach supports random access pagination, which means the user can jump to any page he wants. Behind the scenes, the OFFSET specifies the first record position, and the LIMIT / FETCH NEXT specifies the number of records you want to fetch. For example, if your database contains 500 records, and you request the records for page number 4 and page size 100, the records from position 301 up to 400 will be returned:

In the code below there is an example of a query using the Skip method (I will explain it in more details in the next topic):
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
When a request is made with the page number equals to 4 and the page size equals to 100, the EF Core query will be transcribed in the following SQL query (for MS SQL Server):
SELECT p.Id, p.Name
FROM Products AS p
ORDER BY p.Id
OFFSET 300 ROWS FETCH NEXT 100 ROWS ONLY
The downside of the Offset pagination, is that if the database contains for example 500 records, and you need to return the records from rows 301 up to 400 (i.e. Skip(300).Take(100)), the database must still process (read) the first 300 entries (even if they are not returned), so the database will look through 300 rows, and skip these rows to reach rows 301 up to 400, and this can create a significant computation load that increases with the number of rows being skipped. The higher the number of rows you need to skip, the higher will be the workload imposed on the database.
Another problem with the Offset pagination is that if any updates occur concurrently, your pagination may end up skipping certain entries or showing them twice. For example, if an entry is removed as the user is moving from page 2 to 3, the whole resultset “shifts up”, and one entry would be skipped, or for example if an entry is added in the initial rows as the user is moving from page 2 to 3, then the last returned row is going to appear again as the first row in the next page.
Keyset pagination
The Keyset pagination (also known as seek-based pagination or cursor pagination) is an alternative to the offset pagination, and it uses a WHERE clause to skip rows instead of using an offset (Skip). In this approach, the client knows the last searched element and uses it as a filter in the Where condition.
The keyset pagination requires two properties as input: a reference value (which can be some sequential identifier for the last returned value) and the page size.
For example, assuming the reference is the last returned Id and your database contains 500 records, when you make a request with the reference value equals 300 and the page size equal 100, it will filter the records that only have the Id bigger than 300 and will take the next 100 records:

This kind of pagination is more performant than the offset pagination, because when a query is executed, the database does not need to process all the previous rows before reaching the row number that needs to be retrieved.
In the code below, there is an example using the Where condition filtering by the reference:
var products = await _dbContext.Products.AsNoTracking()
.OrderBy(x => x.Id)
.Where(p => p.Id > reference) // in this example, reference is the "lastId"
.Take(pageSize)
.ToListAsync();
When a request is made with the reference value equals to 300 and the page size equals to 100, the EF Core query will be transcribed in the following SQL query (for MS SQL Server):
SELECT TOP(100) p.Id, p.Name
FROM Products AS p
WHERE p.Id > 300
ORDER BY p.Id
For the keyset pagination, the key must be some sortable property such as a sequential Id, or a date time property that you can compare, etc, in this example is the Id property. With the Where condition, instead of going through all the initial rows to skip them, it jumps directly to the searched row. Assuming an index is defined on Id, this query is very efficient and also isn’t sensitive to any concurrent changes happening in lower Id values.
As with any other query, proper indexing is vital for good performance: make sure to have indexes in place which correspond to your pagination ordering. If ordering by more than one column, an index over those multiple columns can be defined; this is called a composite index. (Microsoft Docs)
This kind of pagination can be considered in scenarios where you do not need to jump to a random page, but instead, you only need to access the previous and the next page, and also in scenarios where you want to create an endless scroll content application, because it is efficient and solves offset paging problems.
The downside of the Keyset pagination is that it does not support random access, where the user can jump to any specific page. This approach is appropriate for pagination interfaces where the user navigates forwards and backwards, which means it’s only possible to execute next/previous page navigation.
Offset and Keyset pagination — pros & cons
Below you can see a comparison table with the pros and cons for each approach:

Offset pagination is recommended for cases when you don’t have a large amount of data, or when you need to have the possibility to jump to a specific page. Thinking about UI, it can be used to present data with the possibility to navigate to not only the previous or next pages but also jump to a specific page.
Keyset pagination is recommended for cases where you have a large amount of data and you need to prioritize performance, or when you can not miss or show duplicated items. Thinking about UI, it can be a good fit for cases where you have infinite scroll, such as showing posts on social media, etc.
Offset pagination objects
For the Offset pagination objects, in the Domain layer, I created a record named PagedResponse<T>, which contains the pagination properties such as the page number, the page size, the total of records, the total of pages (which is calculated based on the total records and the page size) and a property for a generic list of records that will contain the data that will be returned:
public record PagedResponseOffset<T>
{
public int PageNumber { get; init; }
public int PageSize { get; init; }
public int TotalRecords { get; init; }
public int TotalPages { get; init; }
public List<T> Data { get; init; }
public PagedResponseOffset(List<T> data, int pageNumber, int pageSize, int totalRecords)
{
Data = data;
PageNumber = pageNumber;
PageSize = pageSize;
TotalRecords = totalRecords;
TotalPages = (int)Math.Ceiling((decimal)totalRecords / (decimal)pageSize);
}
}
Note that other properties might be added in this object, such as HasNextPage, HasPreviousPage, etc.
To retrieve the data in the response, I created the PagedResponseDto:
public record PagedResponseOffsetDto<T>
{
public int PageNumber { get; init; }
public int PageSize { get; init; }
public int TotalPages { get; init; }
public int TotalRecords { get; init; }
public List<T> Data { get; init; }
}
The Model class is mapped to the Dto class by using AutoMapper:
public class PagedResponseProfile : Profile
{
public PagedResponseProfile()
{
CreateMap(typeof(PagedResponse<>), typeof(PagedResponseDto<>));
}
}
This is an example of the pagination response:
{
"pageNumber": 1,
"pageSize": 5,
"totalPages": 20000,
"totalRecords": 100000,
"data": [
{
"name": "Product 1"
},
{
"name": "Product 2"
},
{
"name": "Product 3"
},
{
"name": "Product 4"
},
{
"name": "Product 5"
}
]
}
Offset pagination demo
Below you can see the GET endpoint for the GetWithOffsetPagination in the ProductsController, that returns a list of Products with Offset pagination:
[HttpGet("GetWithOffsetPagination")]
[ProducesResponseType(StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status400BadRequest)]
public async Task<IActionResult> GetWithOffsetPagination(int pageNumber = 1, int pageSize = 10)
{
if (pageNumber <= 0 || pageSize <= 0)
return BadRequest($"{nameof(pageNumber)} and {nameof(pageSize)} size must be greater than 0.");
var pagedProducts =
await _productService.GetWithOffsetPagination(pageNumber, pageSize);
var pagedProductsDto =
_mapper.Map<PagedResponseOffsetDto<ProductResultDto>>(pagedProducts);
return Ok(pagedProductsDto);
}
The parameters for this endpoint are the page number and the page size. The controller method calls the service method:
public async Task<PagedResponse<Order>> GetWithOffsetPagination(int pageNumber, int pageSize)
{
return await _orderRepository.GetWithOffsetPagination(pageNumber, pageSize);
}
The Service method calls the Repository method, where the pagination query is executed. Before going to the method itself, let me explain the Pagination structure.
For demonstration purposes, I created a non-generic pagination method and a generic pagination method. Let’s start with the non-generic one, that is in the ProductRepository class:
1: public async Task<PagedResponse<Product>> GetWithOffsetPagination(int pageNumber, int pageSize)
2: {
3: var totalRecords = await _dbContext.Products.AsNoTracking().CountAsync();
4:
5: var products = await _dbContext.Products.AsNoTracking()
6: .OrderBy(x => x.Id)
7: .Skip((pageNumber - 1) * pageSize)
8: .Take(pageSize)
9: .ToListAsync();
10:
11: var pagedResponse = new PagedResponse<Product>(products, pageNumber, pageSize, totalRecords);
12:
13: return pagedResponse;
14: }
- On line 3, it reads the data from the Products
DbSet by using the CountAsync method.
- On lines 5 up to 9, there is the EF Core query to retrieve the data.
- On line 6, there is a
OrderBy to order the data by the Id, you can order your data according to your needs, for example, you can order by the product Name, the Creation Date, etc.
- On line 7, the
Skip method is used to skip a number of rows in the query result, determined by the result of (pageNumber - 1) * pageSize. The pageNumber parameter indicates which page of results you want, and pageSize specifies how many records are on each page. The formula (pageNumber - 1) * pageSize calculates the number of records to skip to reach the desired page.
- On line 8, the
Take method (FETCH NEXT or LIMIT in SQL) is used to limit the number of elements returned by the query, in order to retrieve a specific number of rows for the current page.
- On line 9, the result is returned as a
List.
- On line 11, the
PagedResponse object is created.
This is the Generic version of this method, that is in the Repository class:
public virtual async Task<PagedResponse<TEntity>> GetWithOffsetPagination(int pageNumber, int pageSize)
{
var totalRecords = await Db.Set<TEntity>().AsNoTracking().CountAsync();
var entities = await Db.Set<TEntity>().AsNoTracking()
.OrderBy(x => x.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
var pagedResponse = new PagedResponse<TEntity>(entities, pageNumber, pageSize, totalRecords);
return pagedResponse;
}
As you can see, the method is very similar to the non-generic one, but instead of using _dbContext.Products, it is using Db.Set<TEntity>. For example, on line 3, the method _dbContext.Set<TEntity>() is used to represent a list of a given type (in this example, TEntity) in the dbContext.
Testing the Offset pagination
For testing, let’s make a GET request to the GetWithOffsetPagination endpoint, searching for 5 records on the first page:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithOffsetPagination?pageNumber=1&pageSize=5
This is the result:
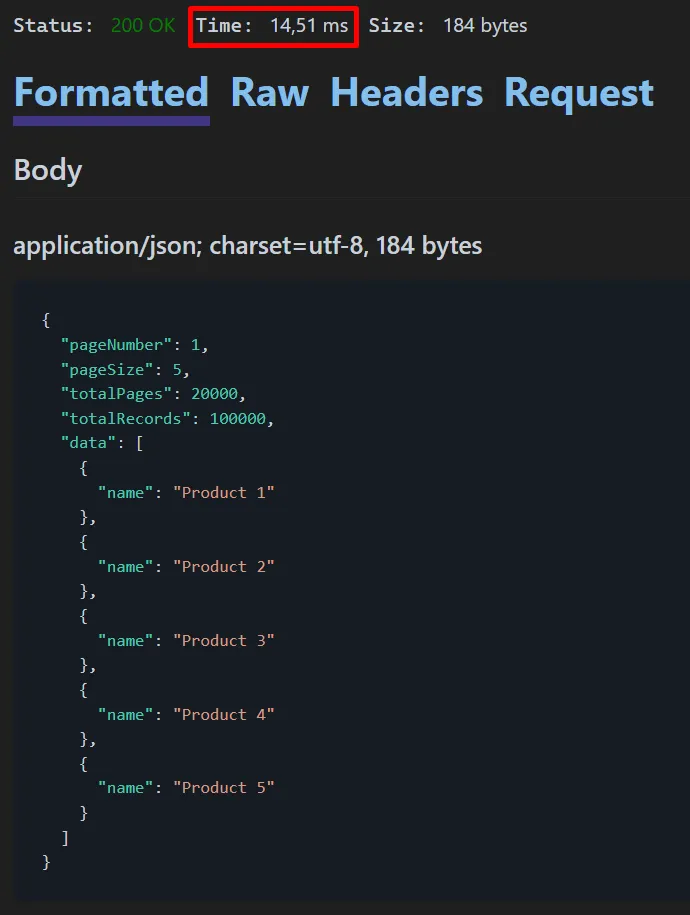
The first five records were returned, and note that the response time was 14,51 ms.
Now let’s make another request with the page number 20000:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithOffsetPagination/?pageNumber=20000&pageSize=5
The response:
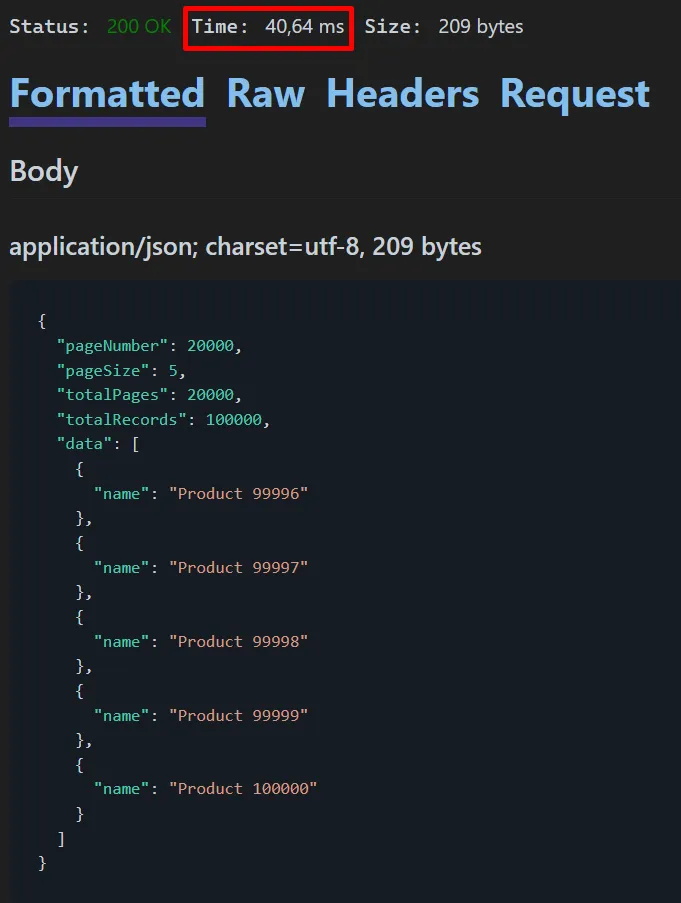
Note that now the response time is quite longer (40,64ms) and this is due to how the offset works in the database. Even that we only return 5 records, the database needs to process all the previous records.
Keyset pagination objects
For the Keyset pagination object, in the Domain layer, I created a record named PagedResponseKeyset<T>, which contains the pagination properties such as a reference value (which in this example is the last returned Id — that will be used as the keyset) and a property for a generic list of records that will contain the data that will be returned:
public record PagedResponseKeyset<T>
{
public int Reference { get; init; }
public List<T> Data { get; init; }
public PagedResponseKeyset(List<T> data, int reference)
{
Data = data;
Reference = reference;
}
}
Note that other properties might be added in this object, such as HasNextPage, HasPreviousPage, etc.
To retrieve the data in the response, I created the PagedResponseKeysetDto:
public record PagedResponseKeysetDto<T>
{
public int Reference { get; init; }
public List<T> Data { get; init; }
}
The Model class is mapped to the Dto class by using AutoMapper:
public class PagedResponseKeysetProfile : Profile
{
public PagedResponseKeysetProfile()
{
CreateMap(typeof(PagedResponseKeyset<>), typeof(PagedResponseKeysetDto<>));
}
}
This is an example of the pagination response for the Keyset operation:
{
"reference": 5,
"data": [
{
"name": "Product 1"
},
{
"name": "Product 2"
},
{
"name": "Product 3"
},
{
"name": "Product 4"
},
{
"name": "Product 5"
}
]
}
Keyset pagination demo
Below you can see the GET endpoint for the GetWithKeysetPagination in the the ProductsController, that returns a list of Products using the Keyset Pagination:
[HttpGet("GetWithKeysetPagination")]
[ProducesResponseType(StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status400BadRequest)]
public async Task<IActionResult> GetWithKeysetPagination(int reference = 0, int pageSize = 10)
{
if (pageSize <= 0)
return BadRequest($"{nameof(pageSize)} size must be greater than 0.");
var pagedProducts = await _productService.GetWithKeysetPagination(reference, pageSize);
var pagedProductsDto = _mapper.Map<PagedResponseKeysetDto<ProductResultDto>>(pagedProducts);
return Ok(pagedProductsDto);
}
The parameters for this endpoint are the reference and the page size. The controller calls the service method:
public async Task<PagedResponseKeyset<Product>> GetWithKeysetPagination(int reference, int pageSize)
{
return await _productRepository.GetWithKeysetPagination(reference, pageSize);
}
The Service method calls the Repository method, where the Keyset pagination is executed. This is the GetWithKeysetPagination method in the CustomerRepository class:
1: public async Task<PagedResponseKeyset<Product>> GetWithKeysetPagination(int reference, int pageSize)
2: {
3: var products = await _dbContext.Products.AsNoTracking()
4: .OrderBy(x => x.Id)
5: .Where(p => p.Id > reference)
6: .Take(pageSize)
7: .ToListAsync();
8:
9: var newReference = products.Count != 0 ? products.Last().Id : 0;
10:
11: var pagedResponse = new PagedResponseKeyset<Product>(products, newReference);
12:
13: return pagedResponse;
14: }
- On lines 3 up to 7, there is the EF Core query to retrieve the data.
- On line 4, there is a
OrderBy to order the data by the Id, you can order your data according to your needs, for example, you can order by the product Name, the Creation Date, etc.
- On line 5, the
Where method is used to filter for records where the reference (in this example, the Id) is higher than the last returned reference value (in this example, the last returned Id). Note that for the keyset pagination, the field you are going to search need to be in a sequential order.
- On line 6, the
Take method (FETCH NEXT or LIMIT in SQL) is used to limit the number of elements returned by the query, in order to retrieve a specific number of rows for the current page.
- On line 7, the result is returned as a
List.
- On line 9, the new reference value is calculated to be retrieved.
- On line 11, the
PagedResponseKeyset object is created.
Testing the Keyset pagination
For testing, let’s make a GET request to the GetWithKeysetPagination endpoint to get the first 5 records:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithKeysetPagination?reference=0&pageSize=5
This is the result:
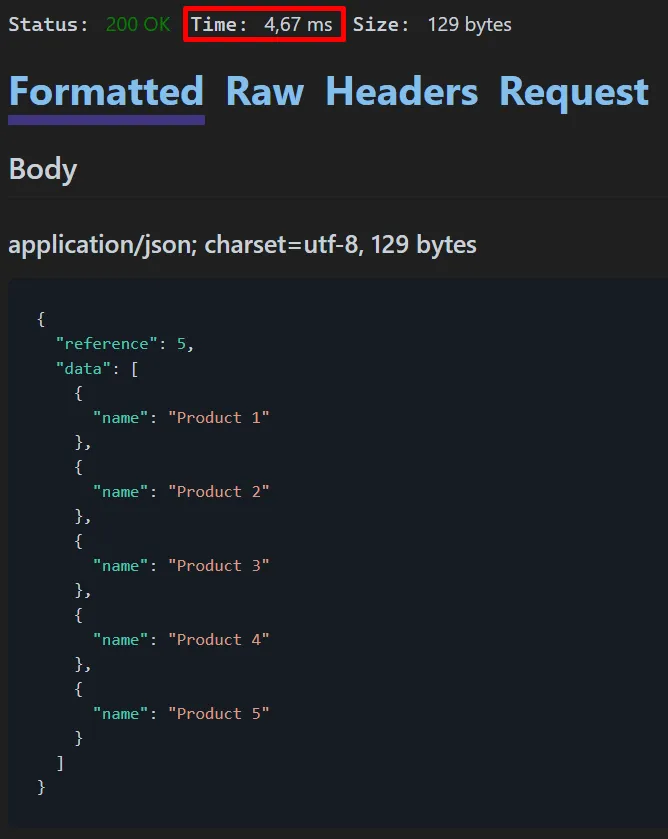
As you can see, the response time was already faster when compared with the Offset pagination, it took only 4,67ms. Now let’s test using the reference equals to 999995, to return the last page:
@PaginationDemo.API_HostAddress = https://localhost:7220
GET {{PaginationDemo.API_HostAddress}}/api/products/GetWithKeysetPagination?reference=99995&pageSize=5
The response:
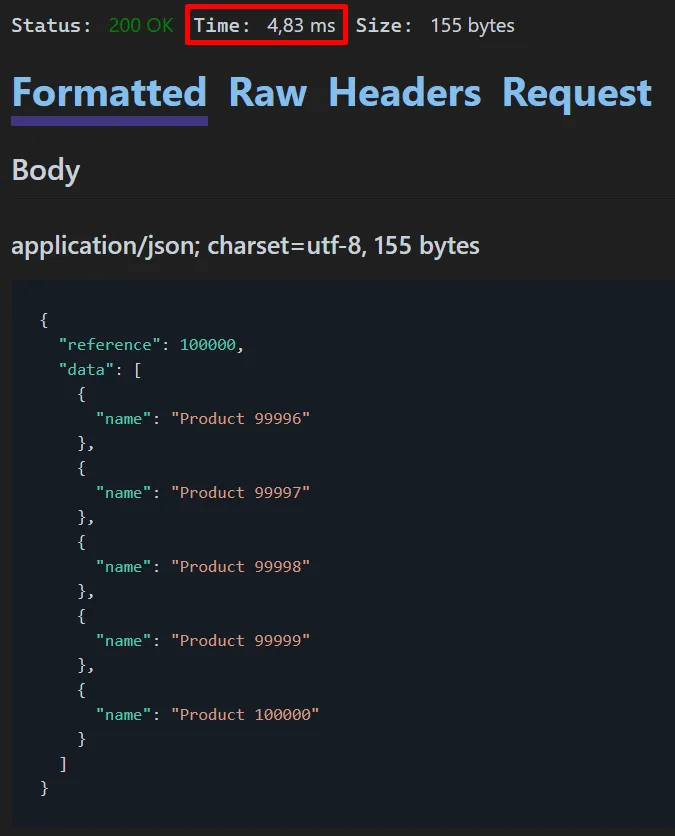
Note that the response time in this case was quite low (4,83ms), and this is because the keyset pagination uses a Where condition, which means that the database does not need to process all the previous records until reach the current rows.
Conclusion
Pagination allows you to retrieve data split into pages, which is a great way to retrieve data in cases where you have a large amount of records. It improves website performance by reducing the number of data that needs to be loaded at once, and it also enhances user experience by providing an easy way to navigate between a large number of data. The Offset pagination can be used when jumping to a specific page is a requirement, and the Keyset pagination can be used when jumping to a specific page is not a requirement and data consistency or performance needs to be prioritized.
The demo project with all examples can be found on my GitHub: https://github.com/henriquesd/PaginationDemo
Thanks for reading!
References