
In this article, you will learn:
- What is hexagonal architecture (or “ports & adapters” as this architecture is officially called)?
- What are the advantages of hexagonal architecture over classical layered architecture?
- What distinguishes hexagonal architecture from “clean architecture” and “onion architecture”?
- How are hexagonal architecture, microservices, and Domain Driven Design related?
Before going into the details of the hexagonal architecture, I briefly explain the purpose of software architecture and why the most widely used architectural pattern, the layered architecture, is unsuitable for larger projects.
What is the goal of a Software Architecture?
By architecture, we mean the division of a system into components, the arrangement and characteristics of these components, and the way these components communicate with each other.
A “historically grown” software architectureA “historically grown” software architecture
According to Robert C. Martin’s book “Clean Architecture”, good architecture allows the software to be changed during its lifetime with as little, constant effort as possible (and correspondingly predictable costs for the client).
Changes could be:
- Implementation of customer requests.
- Adjustments to reflect changes in legal requirements.
- Using more modern technologies (e.g., replacing a SOAP API with a REST API).
- Upgrading infrastructure components (e.g., upgrading the database server or ORM library to a new version).
- Exchanging third-party systems (such as an external billing or newsletter delivery system).
- And even replacing the application server (e.g., Quarkus instead of Glassfish).
How to develop a good Software Architecture?
To keep software “soft,” the application should be divided into well-isolated, independently developable, and testable components. (Automated deployment is also required but is not the subject of this article).
In most business applications, programmers try to achieve this goal through the classic layered architecture:
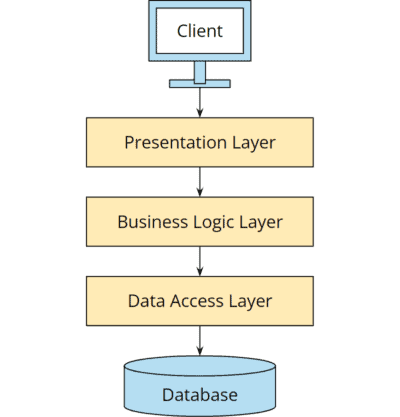
Classic three-layer architecture
However, practice has shown that layered architecture is not well-suited for large projects. You’ll learn why in the next section.
Disadvantages of the Layered Architecture
Layered architecture leads to unnecessary coupling with negative consequences:
The business logic directly depends on the database, while the presentation layer has a transitive dependency. For example, all entities, repositories, and ORM libraries (such as Hibernate or EclipseLink in the Java world) are also available in the presentation layer. This tempts developers to let the boundaries between the layers weaken, especially when they are pressed for time.
For example, it is not uncommon for errors to occur because an attempt is made in the presentation layer to iterate over an uninitialized one-to-many collection of a JPA entity. And so we have to worry about technical issues such as transactions and lazy and eager loading in the business layer.
The coupling also makes it unnecessarily difficult to upgrade the database or data access layer (e.g., to a new database version or a new version of the O/R mapper). I have seen numerous business applications running with outdated (i.e., buggy and/or insecure) Hibernate or EclipseLink versions because an update would require adjustments in all layers of the application and has been down-prioritized by management.
By the way, this affects not only the database but any kind of infrastructure the application accesses. I have even encountered access to the Facebook Graph API from the presentation layer.
The weakening of layer boundaries also makes it impossible to test individual components in isolation – e.g., the business logic without a user interface and database.
What is Hexagonal Architecture?
Alistair Cockburn introduced the hexagonal software architecture in a blog article in 2005. Cockburn states the following goals:
- The application should be equally controllable by users, other applications, or automated tests. For the business logic, it makes no difference whether it is invoked from a user interface, a REST API, or a test framework.
- The business logic should be able to be developed and tested in isolation from the database, other infrastructure, and third-party systems. From a business logic perspective, it makes no difference whether data is stored in a relational database, a NoSQL system, XML files, or proprietary binary format.
- Infrastructure modernization (e.g., upgrading the database server, adapting to changed external interfaces, upgrading insecure libraries) should be possible without adjustments to the business logic.
In the following sections, you will learn how the hexagonal architecture achieves these goals.
Ports and Adapters
The isolation of business logic (referred to as “application” in the hexagonal architecture) from the outside world is achieved via so-called “ports” and “adapters,” as shown in the following diagram:
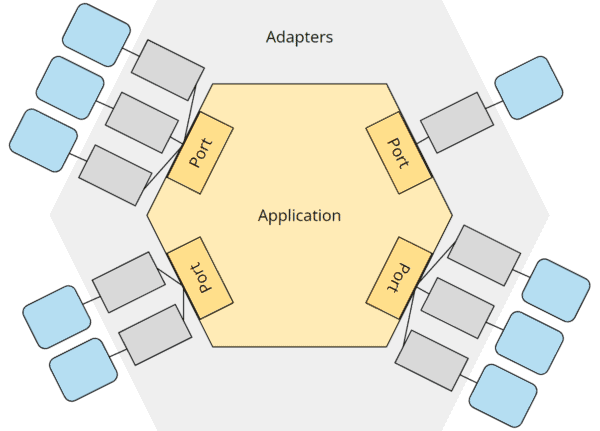
Hexagonal architecture with business logic in the core (“application”), ports, adapters, and external components
The business logic (“application”) is at the core of the architecture. It defines interfaces (“ports”) to communicate with the outside world – both to be controlled (by an API, by a user interface, by other applications) and to control (the database, external interfaces, and other infrastructure).
The business logic knows only these ports; all its use cases are implemented exclusively against the specifications of the ports. It is irrelevant for the business logic which technical details might be behind these ports.
The following illustration shows an exemplary application which
- is controlled by a user via a user interface,
- is controlled by a user via a REST API,
- is controlled by an external application via the same REST API,
- controls a database and
- controls an external application.
(The numbering does not represent an order but references the arrows in the illustration).
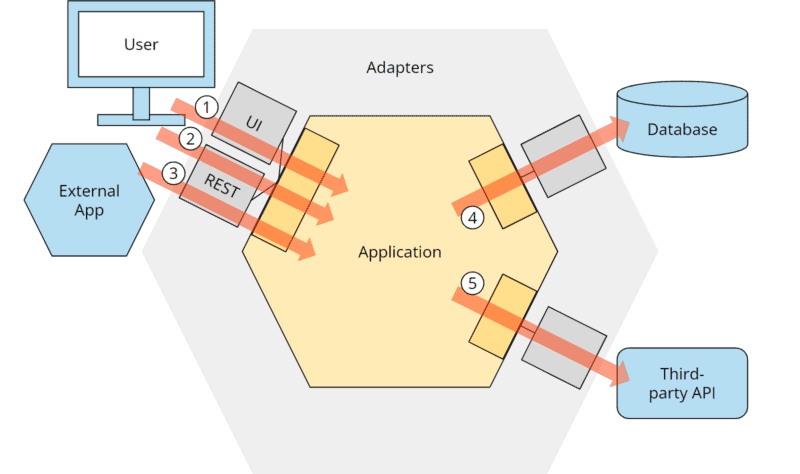
Hexagonal architecture with control flow
The connection to the external components is provided by “adapters.”
For example, the user interface could provide a registration form. When the user has filled in all the data and clicks “Register,” the UI adapter generates a “Register User” command and sends it to the business logic. Alternatively, the same command could be generated by the REST adapter for a corresponding HTTP POST request:
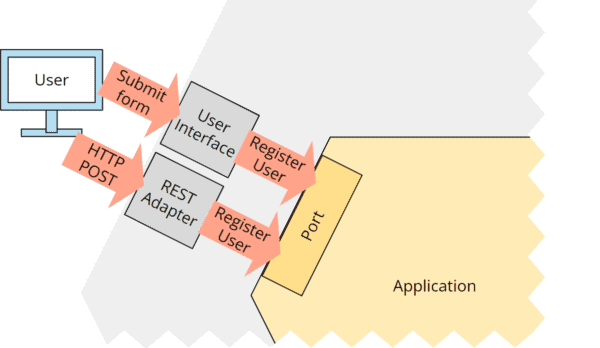
Hexagonal architecture: port with user interface and REST adapter
On the “other side” of the application, the database adapter could translate the “Store User” command into an “INSERT INTO User VALUES (…)” SQL query:
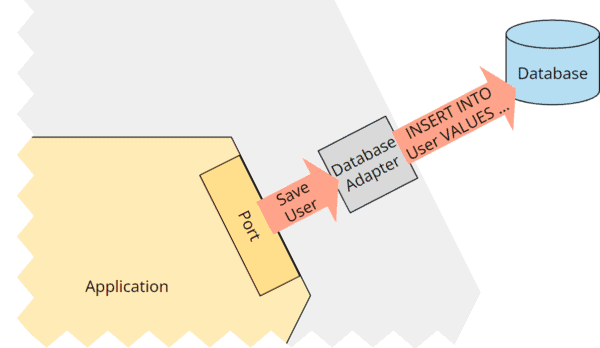
Hexagonal architecture: port with a database adapter
How exactly the adapter does this – whether it uses an O/R mapper and which one and in which version – is irrelevant from the application core’s point of view.
Several adapters can be connected to one port. For example, as in the example above, a user interface adapter and a REST adapter can both be connected to the port to control the application. And a port for sending notifications could have an email adapter, an SMS adapter, and a WhatsApp adapter connected to it.
Incidentally, the term “port” refers to electrical connections to which any device that complies with the connection’s mechanical and electrical protocols can be connected.
Primary and secondary ports and adapters
From the example above, we have seen two types of ports and adapters – those that control the application and those that are controlled by the application.
We call the first group “primary” or “driving” ports and adapters; these are usually shown on the left side of the hexagon.
We refer to the second group as “secondary” or “driven” ports and adapters, usually shown on the right.
Dependency rule
In theory, this sounds quite good. But how do we programmatically ensure that no technical details (like JPA entities) and libraries (like O/R mappers) leak into the application?
We can find the answer in the so-called “dependency rule.” This rule states that all source code dependencies may only point from the outside inwards, i.e., in the direction of the application hexagon:
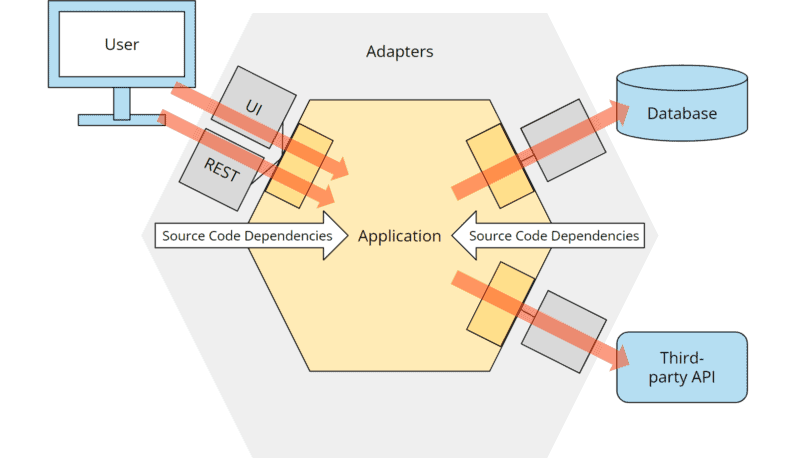
Hexagonal architecture: dependency rule
The mapping into classes and their relationships to each other is quite simple for primary ports and adapters (i.e., the left side of the image).
Staying with the user registration example, we could implement the desired architecture with something like the following classes:
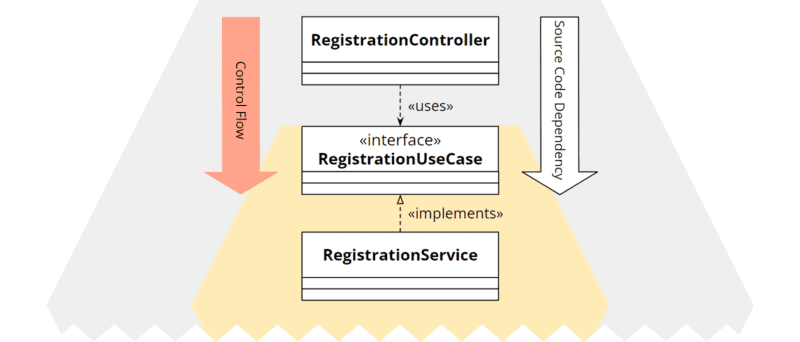
Hexagonal architecture: class diagram of primary port and adapter
The RegistrationController is the adapter, the RegistrationUseCase interface defines the primary port, and the RegistrationService implements the functionality described by the port. (I took this naming convention from the excellent book “Get Your Hands Dirty on Clean Architecture” by Tom Hombergs).
The source code dependency goes from RegistrationController to RegistrationUseCase, therefore, as required, towards the core.
But how do we implement the secondary ports and adapters, i.e., the right side of the image where the source code dependency must be opposite to the invocation direction? For example, how can the application core access the database if the database is outside the core and the source code dependency is to be directed to the center?
This is where the dependency inversion principle comes into play.
Dependency Inversion
Also, the port is defined by an interface. However, the relationships between the classes are swapped: the PersistanceAdapter does not use the PersistencePort but implements it. And the RegistrationService does not implement the PersistencePort but uses it:
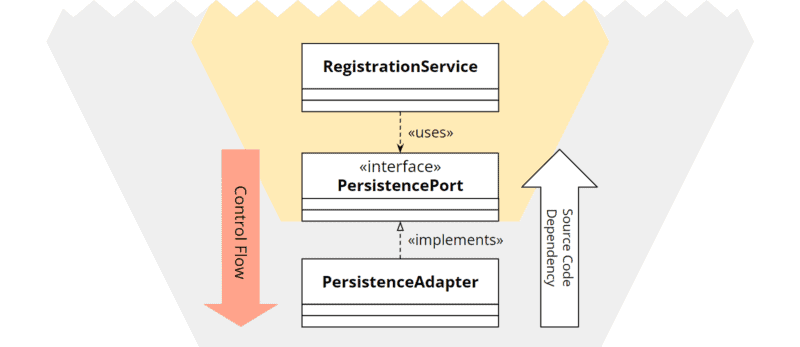
Hexagonal architecture: class diagram of secondary port and adapter
Employing the dependency inversion principle, we can choose the direction of a code dependency – for secondary ports and adapters opposite to the calling direction.
Mapping
Isolating the technical details from the application core leads to a dilemma that becomes apparent, for example, when using an O/R mapper. Entity classes are usually annotated to instruct the mapper on which database table and columns to map the entity and its properties to, how to generate the primary key, and how to map collections to relations.
Since the application core is not supposed to know the technical details of the persistence adapter, we cannot provide such an entity with these technical annotations in the application core:
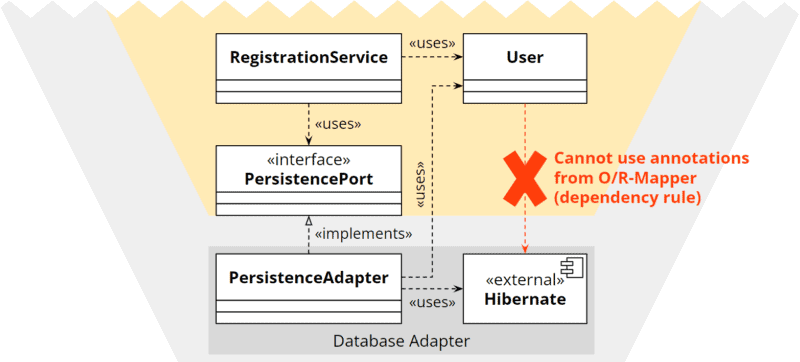
Dependency rule: dependencies from the core to the adapter are not allowed
On the other hand, we cannot implement the entity in the adapter because then the application core would no longer have access to it:
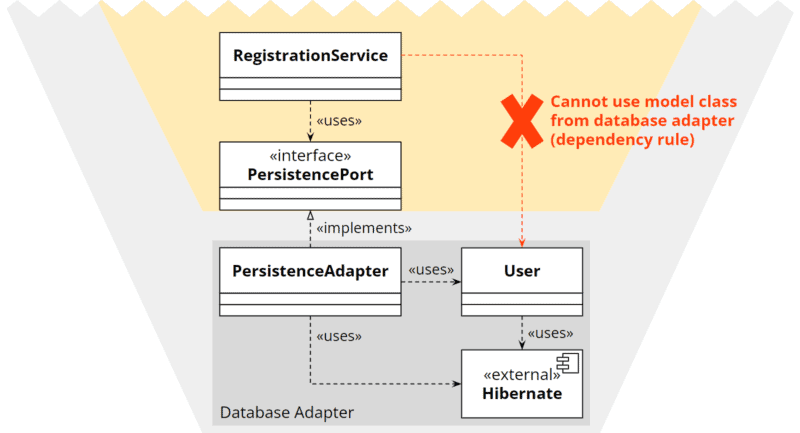
Dependency rule: dependencies from the core to the adapter are not allowed
How can we resolve this dilemma?
In the following sections, I’ll introduce you to different strategies for doing this.
Duplication with two-way mapping
We create an additional model class in the adapter that does not contain any business logic but does contain the technical annotations. The adapter must then map the core’s model class to the adapter model class and vice versa.
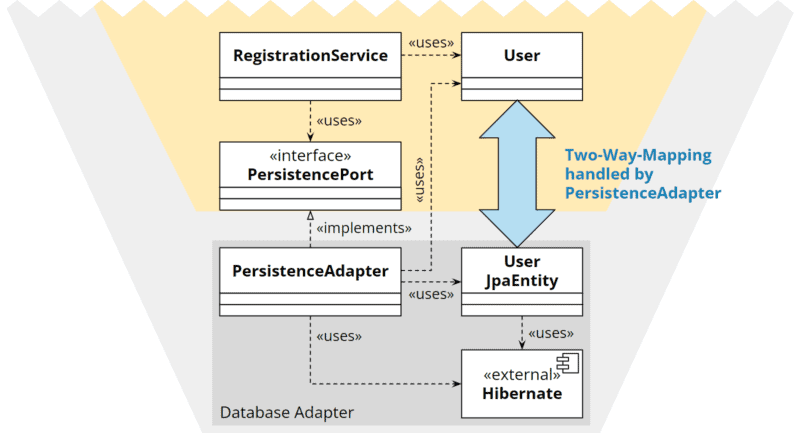
Hexagonal architecture: duplication with two-way mapping
In my experience, this variant is the most suitable.
Duplication with one-way mapping
We define an interface in the core and let both the core’s model class and the adapter’s model class implement this interface. Thus, only the model coming from the core needs to be translated into the adapter model. A translation towards the core is unnecessary: the adapter can send its own model class to the core since it implements the core’s interface.
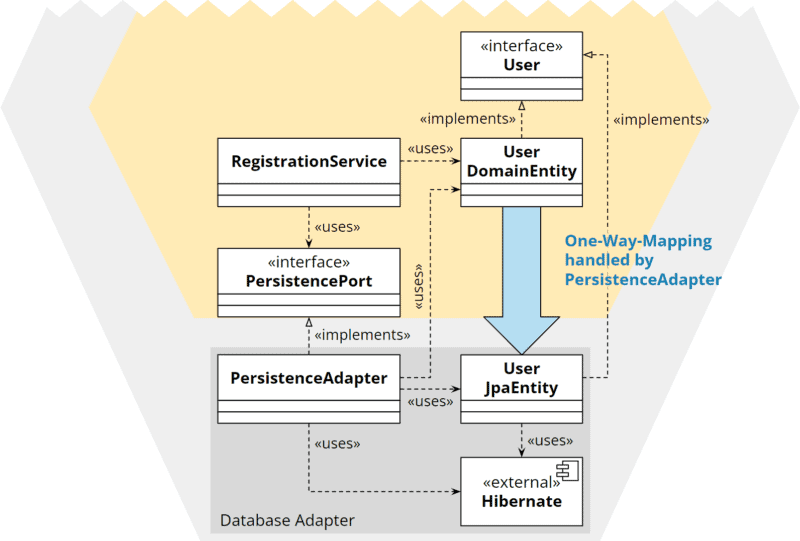
Hexagonal architecture: duplication with one-way mapping
This variant requires that the interface defines only the access methods for those fields to be persisted. Business logic methods must not be contained in the interface. I don’t like this strategy because it is less intuitive and, in my experience, is more overhead and less maintainable than two-way mapping.
Technical instructions outside the program code
Some libraries, such as Hibernate, allow the technical instructions to be defined in an XML file instead of using annotations in the model class. This allows the adapter to use the core’s model class without duplicating code.
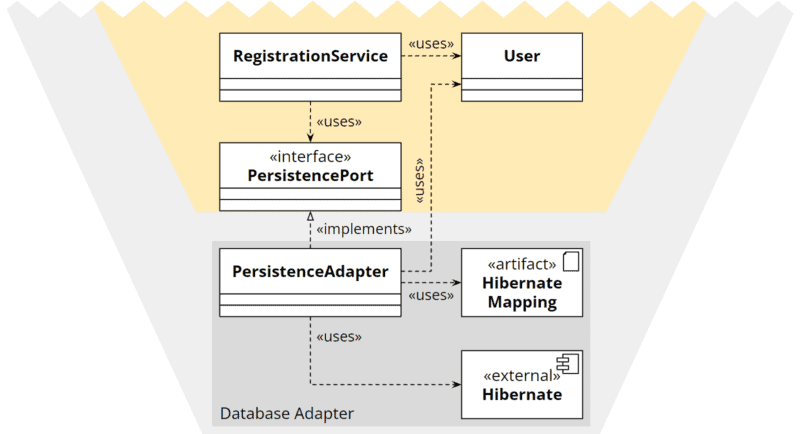
Hexagonal architecture: technical instructions outside the program code
However, external instructions are often much more confusing than annotations in the code, so I’m not particularly eager to use this strategy either.
Weakening the architectural boundaries
Ultimately, one can consciously decide to weaken the strict architectural boundaries, allow a dependency from the core to the ORM library, and place the annotations directly on the entity in the core.
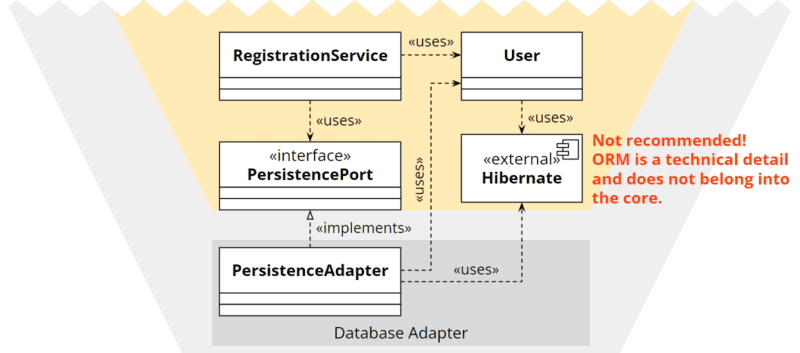
Hexagonal architecture: weakening architectural boundaries
I would always advise against this option. Once you start with it, it doesn’t take long – according to the broken windows theory – until the next architecture rule is dropped.
Mapping in the REST adapter
Mapping is not only an issue with the database adapter but also with a REST adapter, for example. Often we don’t want to make all attributes of an entity visible through the interface (e.g., the primary key or the creation and modification date), and for some attributes, we need to define how to format them (e.g., date and time information).
We can also control this with technical annotations (e.g., @JsonIgnore or @JsonFormat when using Jackson). But we don’t want these in the application core either. Therefore, even with REST adapters, it usually makes sense to map an entity to an adapter-specific model class that contains only the visible fields and the formatting instructions.
Tests
At the beginning of the article, I mentioned “isolated testable components” as one of the requirements for good software architecture. In fact, the hexagonal architecture makes it very easy for us (as you will also see in practice in the following parts of this article series) to test the business logic of the application:
- Tests can invoke the business logic through the primary ports.
- The secondary ports can be connected to test doubles, e.g., in the form of stubs to answer queries from the application or spies to record events sent by the application.
The following diagram shows a unit test that creates a test double for the database and connects it to the secondary database port (“Arrange”), invokes a use case on the primary port (“Act”), and verifies the port’s response and interaction with the test double (“Assert”):
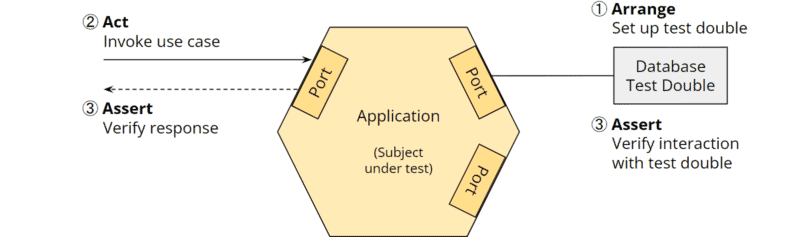
Hexagonal architecture: unit tests for the business logic
Not only can the business logic be tested in isolation from the adapters, but the adapters can also be tested in isolation from the business logic (e.g., in the Java ecosystem, primary REST adapters with REST Assured, secondary REST adapters with WireMock, and database adapters with TestContainers).
The following diagram shows an integration test that creates a test double for the primary port (“Arrange”), sends an HTTP POST request to the REST adapter via REST Assured (“Act”), and finally verifies the HTTP response and interaction with the test double (“Assert”):
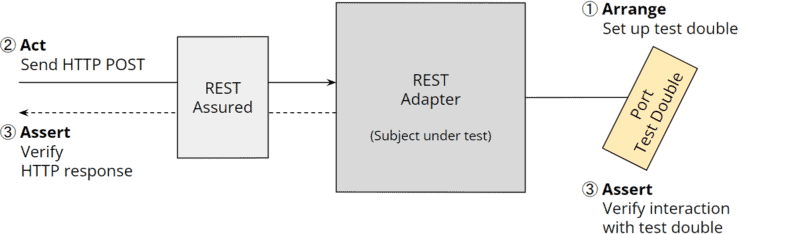
Hexagonal architecture: integration test for a REST adapter
The last diagram shows an integration test for the database adapter that uses TestContainers to start up a test database (“Arrange”), calls a method on the database adapter (“Act”), and finally checks whether the return value of the method and, if applicable, the changes in the test database meet expectations (“Assert”):
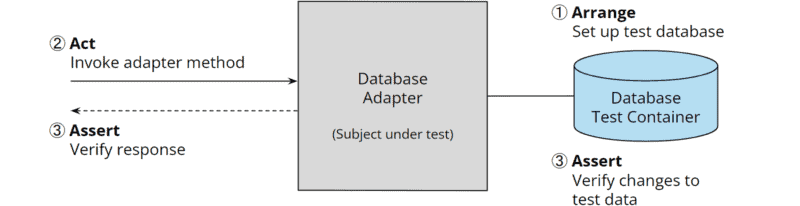
Hexagonale Architektur: Integrationstest für Datenbank-Adapter
In addition to these isolated tests, complete system tests should not be missing (to a lesser extent, according to the test pyramid).
Why a Hexagon?
Alistair Cockburn is frequently asked whether the hexagon or the number “six” has a particular meaning. His answer to this question is: “No.” He wanted to use a shape that no one had used before. Squares are used everywhere, and pentagons are hard to draw. So it became a hexagon.
The hexagon is also great for drawing in two primary ports on the left and two secondary ports on the right. Cockburn says he’s never encountered a project that required more than four ports for its schematic representation.
Advantages of the Hexagonal Architecture
Now that we have looked at the hexagonal architecture from all sides, it is time to recall the goals of good software architecture and to examine the extent to which the hexagonal architecture fulfills these goals.
Software should be easily modifiable and remain so throughout its lifetime. To this end, it should be structured into components that are isolated from one another and can be developed and tested independently.
Let’s go through the criteria in detail.
Modifiability
- We can change the business logic in the application core without having to change the adapters or infrastructure (although, in practice, changing the business logic often involves changes to the user interface and data storage).
- We can upgrade and replace the infrastructure (e.g., the database or the O/R mapper) without having to change a single line of code in the business logic. We only need to adapt the corresponding adapter.
- By starting with the development of the application core, we can delay decisions about the infrastructure and make them very late in the development process. The experience gained during the core development allows us to make better decisions about the infrastructure to use (application framework, database system, etc.).
Isolation
- The application core deals exclusively with business topics.
- All technical issues are implemented in the primary and secondary adapters.
- Application core and adapters are isolated by ports – the use cases in the application core interact exclusively with these ports without knowing the technical details behind them.
- Isolation allows all responsibilities to be clearly localized in the code, significantly reducing the risk of architectural boundaries becoming blurred.
Development
- Once the ports of the application are defined, the work on the components (core, user interface, database connectivity, etc.) can be easily divided among multiple developers, pairs, or teams.
Testability
- As shown in detail above, we can test all components in complete isolation using test doubles.
The hexagonal architecture thus fulfills all the criteria of good software architecture. That sounds almost too good to be true. Doesn’t the hexagonal architecture model have any disadvantages?
Disadvantages of the Hexagonal Architecture
Implementing the ports and adapters and the selected mapping strategy represent a non-negligible additional effort. It amortizes quickly for large enterprise applications; for smaller applications, such as a simple CRUD microservice with minimal business logic, the extra effort is not worth it.
In the best case, you have a senior developer/architect in your team who already has experience with hexagonal architecture and can judge whether the initial additional effort is worthwhile for your project.
I recommend you follow the example application on which I will demonstrate the implementation of the hexagonal architecture in the following parts of this tutorial series. This way, you’ll gain your first experience and maybe become that experienced developer who brings the hexagonal architecture into play for your next project.
Hexagonal Architecture and DDD (Domain Driven Design)
In literature, one repeatedly finds representations of the hexagonal architecture with “entities” and “use cases” or “services” within the application hexagon and/or with a “domain” or “domain model” hexagon within the application hexagon – roughly as in the following figure:
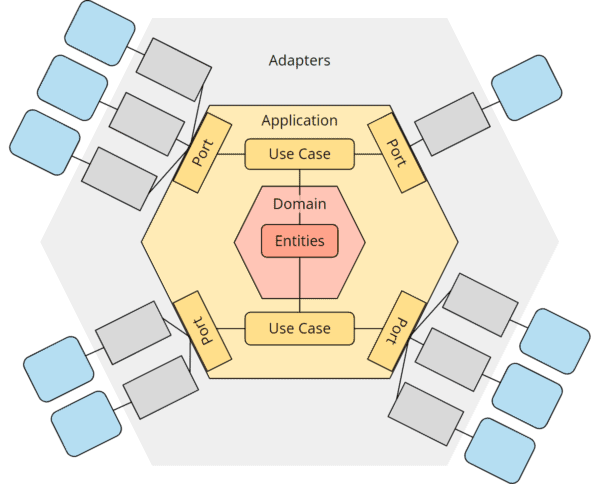
Hexagonal architecture and DDD (domain driven design)
In fact, the hexagonal architecture deliberately leaves open what is inside the application hexagon. In a fascinating interview, Alistair Cockburn answered the question, “What do you see inside the application?” with, “I don’t care – not my business. The hexagonal design pattern represents a single design decision: “Wrap your app in an API and put tests around it.”
Nevertheless, domain-driven design (DDD) and hexagonal architecture complement each other exceptionally well because the DDD discipline of tactical design is ideally suited to structure the business rules within the application hexagon.
I will, therefore, also use this additional domain hexagon in the following articles of this series, in which I will demonstrate the implementation of a hexagonal architecture with Java.
Hexagonal Architecture and Microservices
The hexagonal architecture is also suitable for implementing microservices, provided they meet two criteria:
- They must contain business logic and not be purely technical. For example, a microservice that logs all events it listens to on an event bus to another system has a strictly technical purpose. There is no business logic that could be isolated from the technical details.
- They must be of a certain size. For a microservice with minimal business logic, the extra effort for ports, adapters, and mapping is not worth it. There is no fixed size limit; a decision must be made based on experience. When using domain-driven design, and a microservice comprises an aggregate with several entities and the associated services, the hexagonal architecture is usually sensible.
From a microservice’s perspective, all other microservices are parts of the outside world and are isolated via ports and adapters, just like the rest of the infrastructure:
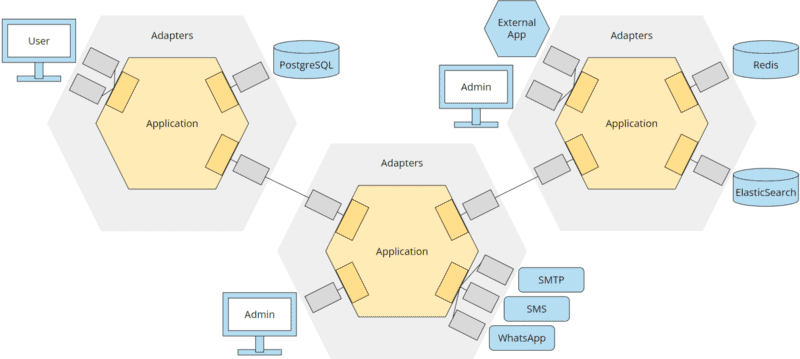
Hexagonal architecture and microservices
My approach to designing a complex business application is usually a combination of domain-driven design, microservices, and hexagonal architecture:
- Using strategic design to plan the core domain, subdomains, and bounded contexts.
- Breaking down a bounded context into one or more microservices. A microservice can contain one or more aggregates – but also the complete bounded context, as long as this is not too large (and the application becomes a monolith instead of a microservice).
- Implementation of the application hexagon according to tactical design, i.e., with entities, value objects, aggregates, services, etc.
Hexagonal Architecture vs. “Ports & Adapters”
Hexagonal architecture and “ports and adapters” (sometimes “ports & adapters”) refer to the same architecture. The official name given by Alistair Cockburn to the architecture pattern described in this article is “ports and adapters.”
The more common, figurative name “hexagonal architecture” results from the architecture’s graphical representation using hexagons. Alistair Cockburn revealed in the above interview that he, too, prefers the figurative name – but that the official name of a design pattern must be one that describes its properties.
Hexagonal Architecture vs. Layered Architecture
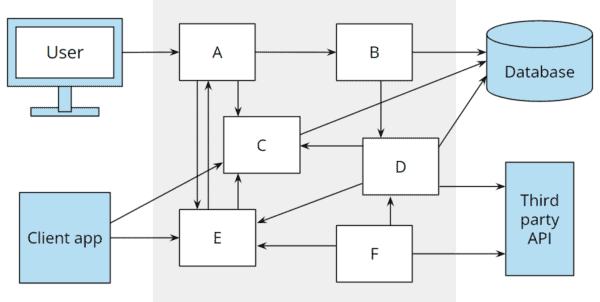
At the beginning of the article, I mentioned the widely used layered architecture and its disadvantages (transitive dependencies to the database, blurring layer boundaries, poor isolation of components, poor testability, poor maintainability, and interchangeability of infrastructure components).
In the following, you can see the two architectural patterns compared. In contrast to the hexagonal architecture (here in its original representation by Alistair Cockburn without explicit ports), the layered architecture does not focus on the business logic but on the database:
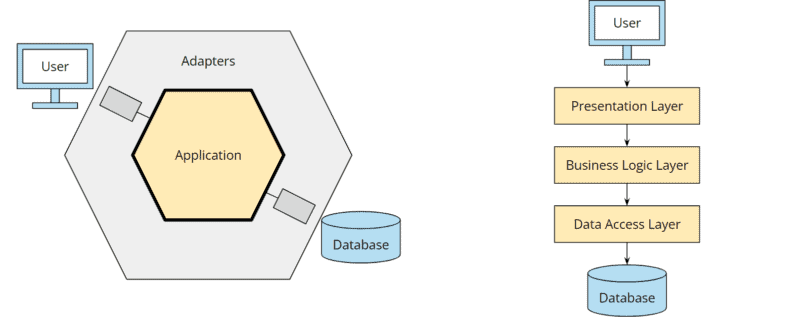
Hexagonal architecture vs. layered architecture
We apply a “database-driven design,” so to speak, and start planning how to store our model in tables rather than considering how our model should behave.
Many of us developers have been working with the layered model for so long that it has become second nature, and we consider it the most normal thing in the world to plan an application around a database.
Doesn’t it make much more sense to plan and develop the business side of an application first? And only then, when it is necessary, to think about how data is persisted? Shouldn’t it be that changes in the business logic may require changes to the persistence – and not the other way around? I think so.
And rarely does a business application remain as simple as shown above. Once the application becomes more complex, additional dependencies are created. The following figure shows the architecture extended by a REST API and the connection of a third-party service:
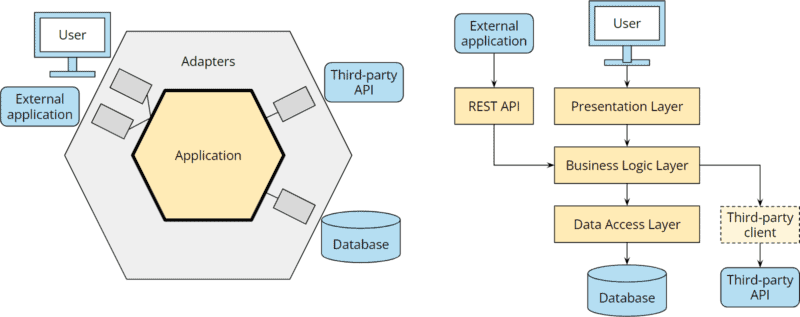
Hexagonal architecture vs. layered architecture: extending the application
With the hexagonal architecture, it is clearly defined where the additional components belong.
In a layered architecture, a REST API is often attached to the business logic (possibly duplicating business logic implemented in the presentation layer if not refactored beforehand), and the business logic, in turn, gets an additional dependency on the external service.
I have drawn the “third-party client” as a dashed line since this component is often omitted, and the interface of the external application is accessed directly from the business layer (if not from the presentation layer).
While the hexagonal architecture added a port and two adapters with clear source code dependencies towards the core, the dependency chaos between the layers is growing: We now have transitive dependencies from the REST API to the data access layer, from the REST API to the third-party API, from the user interface to the data access layer, and from the user interface to the third-party API:
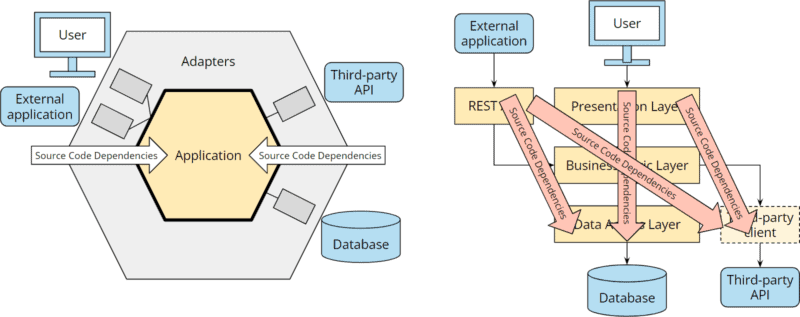
Hexagonal architecture vs. layered architecture: source code dependencies
These dependencies make available not only the lower layer code in REST API, presentation layer, and business layer but also all libraries used there. And so the architectural boundaries blur further.
Hexagonal Architecture vs. Clean Architecture
“Clean architecture” was introduced in 2012 by Robert Martin (“Uncle Bob”) on his Clean Coder Blog and described in detail in the 2017 book “Clean Architecture.”
As in the hexagonal architecture, business logic is also at the center of clean architecture. Around it are the so-called interface adapters, which connect the core with the user interface, the database, and other external components. The core only knows the interfaces of the adapters but knows nothing about their concrete implementations and the components behind them.
In clean architecture, too, all source code dependencies point exclusively in the direction of the core. Where calls point from the inside to the outside, i.e., in the opposite direction to the source code dependency, the dependency inversion principle is applied.
The following diagram shows the hexagonal architecture and clean architecture side by side:
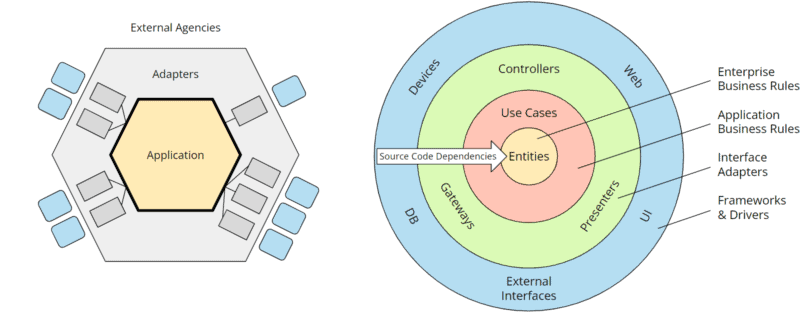
Hexagonal architecture vs. clean architecture
If we adjust the colors a bit in the hexagonal architecture and replace the concrete adapters and external components with nameless placeholders in the clean architecture, we get two very similar illustrations:
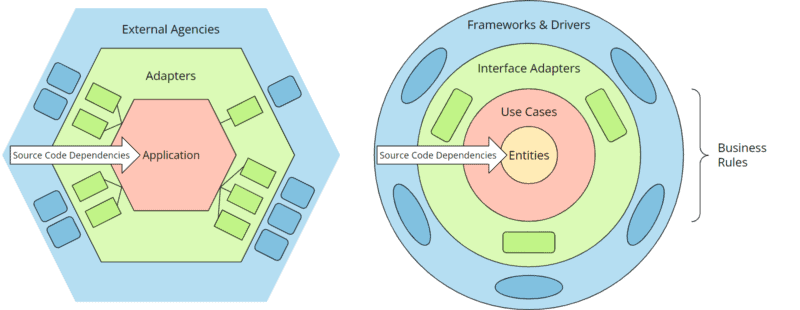
Hexagonal architecture vs. clean architecture (both “normalized”)
The hexagons can be mapped almost one-to-one to the clean architecture rings:
- The “external agencies” arranged around the outer hexagon correspond to the outer ring of the clean architecture, “frameworks & drivers.”
- The outer hexagon “adapters” corresponds to the ring “interface adapters.”
- The application hexagon corresponds to the “business rules” in the clean architecture. However, these are further subdivided into “enterprise-related business rules” (entities) and “application business rules” (use cases that orchestrate the entities and control the flow of data to and from them). On the other hand, the hexagonal architecture deliberately leaves the architecture within the application hexagon open.
The ports are not explicitly mentioned in clean architecture but are also present in the associated UML diagrams and source code examples in the form of interfaces:
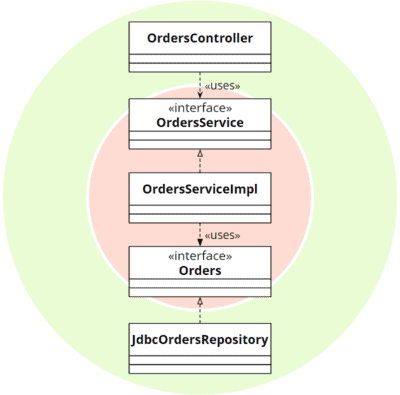
Interfaces: implicit “ports” in the clean architecture
In summary, both architectures are almost identical: the software is divided into layers, and all source code dependencies point from the outer to the inner layers. The application’s core knows no details of the outer layers and is implemented only against their interfaces. This creates a system whose technical details are interchangeable and which is fully testable without them.
Hexagonal Architecture vs. Onion Architecture
Also, in the “onion architecture” presented by Jeffrey Palermo on his blog in 2008, business logic is at the center, in the so-called “application core.” The core has interfaces to the user interface and the infrastructure (database, file system, external systems, etc.) but does not know their concrete implementations. Thus, the core is also here isolated from the infrastructure.
Just as in the hexagonal and clean architecture, all source code dependencies point in the direction of the core. Where the call direction goes opposite to the source code dependency, dependency inversion is applied.
In the following figure, you can see the hexagonal architecture and the onion architecture compared:
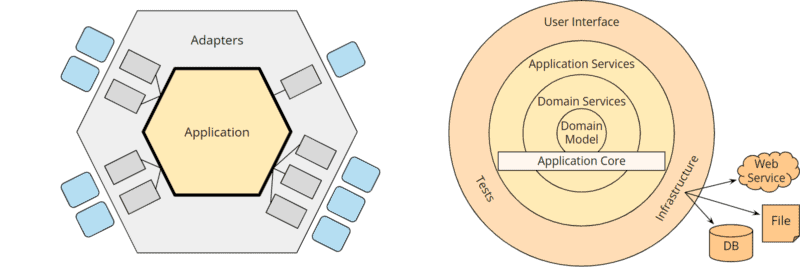
Hexagonal Architecture vs. Onion Architecture
If we again adjust the colors a bit and replace the user interface, tests, and infrastructure with placeholders in the onion architecture and hide the optional rings of the application core, we again get two very similar images:
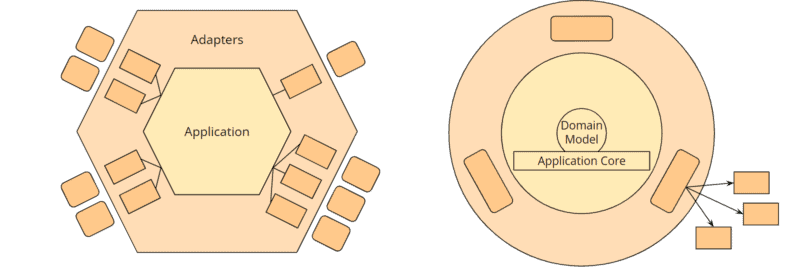
Hexagonal Architecture vs. Onion Architecture (both “normalized”)
The hexagons can be mapped almost one-to-one to the rings of the onion architecture:
- The “external agencies” arranged around the outer hexagon are represented in the onion architecture by the infrastructure components at the bottom right.
- The outer hexagon “adapters” corresponds to the ring containing “user interface,” “tests,” and “infrastructure.”
- The application hexagon corresponds to the application core in the onion architecture. This is further subdivided into “application services,” “domain services,” and “domain model,” whereby only the “domain model” is a fixed component of the onion architecture. The other rings of the application core are explicitly marked as optional. The “domain model” defines the “enterprise business rules” and thus corresponds to the “entities” ring – i.e., the innermost circle – of the clean architecture.
In the final analysis, therefore, the onion architecture is also almost identical to the hexagonal architecture – it differs only in the explicit “domain model” at the center of the application core.
Summary and outlook
Hexagonal architecture or “ports and adapters” (alternatively clean architecture or onion architecture) are an architectural pattern that eliminates the problems of traditional layered architecture (leakage of technical details to other layers, poor testability) and allows decisions about technical details (e.g., the database used) to be deferred and changed without having to adapt the core of the application.
Business code resides in the application core, remains independent of technical code in the infrastructure, and can be developed and tested in isolation.
All source code dependencies point exclusively in the direction of the core. The dependency inversion principle is applied when control flows in the opposite direction, i.e., from the core to the infrastructure (e.g., to the database).
The hexagonal design pattern requires additional effort and is particularly suitable for complex business applications with an expected lifetime of several years to decades.