
The more I learn, the more I realize how much I don’t know. — Albert Einstein
When we were starting off in philanthropy, my wife Cari did a listening tour to try to shape our strategy. We were trying to learn some basic principles about choosing cause areas and tactics — how can we do a good job as philanthropists and as stewards of this capital? Almost universally, people would coach us that this was largely about personal interest — what were we passionate about?
We knew we wanted to help people. We knew we wanted to avoid bureaucracy and waste and do things that achieved efficient impact. In business, I was used to allocating a budget by sorting a list of possibilities based on their relative impact, and I thought I could expect something similar in philanthropy. Our foundation, Good Ventures, was an opportunity to have impact in a leveraged way, at massive scale, as long as we chose these areas purposefully and thoughtfully. To be clear, it was common for other philanthropists and their consultants to think strategically, too, after they had chosen a focus area (or areas). But we couldn’t find anyone accustomed to thinking strategically before choosing focus areas — a concept we now refer to as strategic cause selection. We didn’t know that it would be so hard to find someone who could help us answer the most important questions as we understood them.
In 2010, as part of Cari’s journey walking the connections between ideas and people, we met Holden Karnofsky and Elie Hassenfeld. They had embarked on a similar research endeavor after earning some savings earlier in their careers. At first, they thought that it would be easy to find answers to their questions about effectiveness, but they were hindered again and again by a lack of concrete, well-organized, public information as well as prior research comparing outcomes across cause areas. Eventually, they founded a new organization to create the resource they were missing: GiveWell.
We started working together because we were all interested in the same question: how do we do the most good that we can? Over the years a community has developed, effective altruism, that’s dedicated to this question, though in practice it’s composed of a variety of groups and beliefs, with direct and indirect ties to the core research project. In my mind, the distinctions between these groups come from two places: differing answers on “how”, and differing perspectives on “the most good.”
What they’re anchored in is the desire to figure out what is a wise way to give and when you put it that way, that is absolutely the right question to ask. — Chris Anderson
Effective altruism as a question isn’t prescriptive, which means everybody engages in their own way. When I think of how I relate to people interested in effective altruism, it is that we share a common interest in investigating this question, and actually doing the work that goes into resolving it, rather than that we have a common set of answers. There is a fascination and a shared curiosity — indeed, you often find the same member of the community vacillating between points of views and even hedging how they donate (i.e. “a portfolio approach”).
When a group has a shared sense of identity, the people within it are still not all one thing, a homogenous group with one big set of shared beliefs — and yet they often are perceived that way. Necessarily, the way that you engage in characterizing a group is by giving it broad, sweeping attributes that describe how the people in the group are similar, or distinctive relative to the broader world. As an individual within a group trying to understand yourself, however, this gets flipped, and you can more easily see how you differ. Any one of those sweeping attributes do apply to some of the group, and it’s hard to identify with the group when you clearly don’t identify with many of the individuals, in particular the ones with the strongest beliefs. I often observe that the people with the most fringe opinions inside a group paradoxically get the most visibility outside the group, precisely because they are saying something unfamiliar and controversial.
Similarly, some effective altruists have become known as particularly important examples of the movement precisely because they are prescriptive on the answers to the big questions. On the other hand, the opposite extreme doesn’t make any more sense: it’s hard for anyone to get traction on helping the world without having some beliefs. The central tension with effective altruism comes from how everyone lives between these extremes. Where do people assert convictions and where do they qualify and hedge beliefs, and treat the question with humility?

Epistemic humility — how to do the most good?
When we were starting off on our journey, we’d meet philanthropists who were farther along and they would give us confident answers to our questions. “What is the best way to help people out of extreme poverty?” we’d ask and they’d say “ah, the most important thing is access to clean water, which is why we work on drilling wells.” This would spur a number of follow up questions — what else did they consider? How did they decide wells were the most important among those? Are wells the best solution to providing clean water everywhere or only in certain conditions? What exactly do they mean by “important”? We found that confidence in the answer did not typically come with curiosity about these kinds of questions, and that made it hard for us to feel conviction ourselves.
Similarly, when talking to others about the relative importance of helping animals, I often hear people draw definitive lines in the sand like “only primates matter”, “chickens aren’t conscious”, etc. They say these things to make it clear that we’re hopelessly misguided for spending any of our capital and effort helping animals rather than humans. My attitude is more like “what even is consciousness?” and “what is it like to be a bat?” I thought I knew how animals were usually raised before I researched it,¹ but I had little grounding for these more fundamental questions about what their lives were like. In the end, I concluded that there is less agreement among experts than I could have imagined. The answers are philosophy, not science, and the philosophers don’t agree with each other even on the biggest questions.
Turning beliefs into action in the face of uncertainty
I’m concerned it can be pretty easy to talk yourself into a default position that the convenient answers are the right ones² and so feel compelled to act to mitigate what seems reasonably likely to turn out to be harms on an unimaginable scale. I’m not sure if I do this out of a sense of moral obligation so much as regret minimization, as well as simple compassion for the suffering that at least does a very compelling job of appearing to exist.
Almost all of our philanthropy seems to encounter confident critics. The most popular rebuttal at the moment is the assertion that “AI x-risk isn’t real”. I’ve long said that the people I least understand in the AI risk debate are the ones who have ~100% confidence that AI will or will not destroy us — either way, how can they really know something like that? The answers about what will happen after the creation of this unprecedented technology (if it is created) are theory, not science, and once again the experts don’t agree with each other even on the biggest questions.
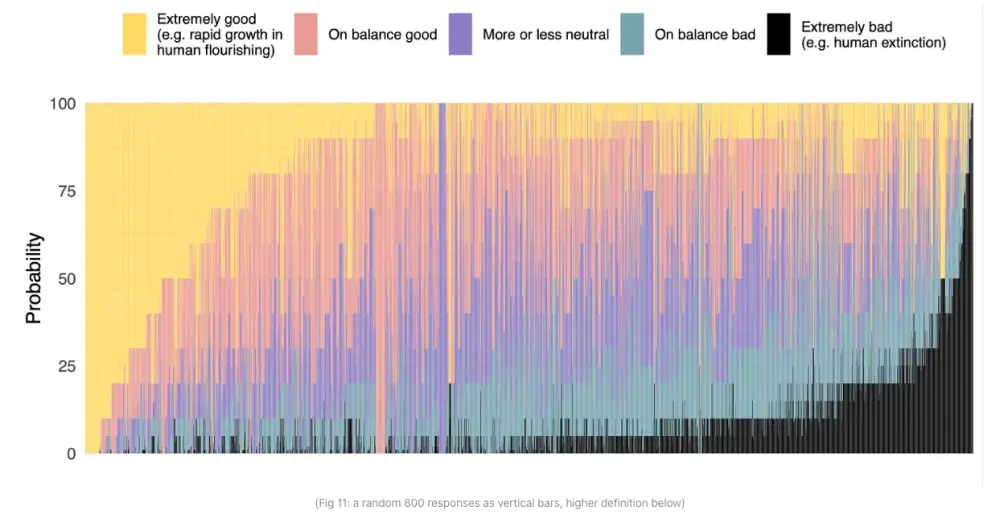
For me, the decision to get involved in mitigating the potential harms from advanced AI comes neither from confidence in a high probability of catastrophe (“doomerism”) nor from some kind of extreme devotion to the precautionary principle. Like our critics, I dream of what’s possible if and when we succeed in building transformative AI, of humanity thriving, and the benefits are big enough to warrant tolerating some risks.³ At the beginning, I thought I knew AI would unfold safely and even helped to build it faster,⁴ but I have tried to look as objectively as possible at the arguments and the evidence and concluded that the risks were big enough and real enough to be taken much more seriously than humanity currently does.
I’m not saying it’s inherently extremely difficult to avoid existential risks from AI — I am saying it is likely we need to take specific safety and security measures to avoid them. — Ajeya Cotra
I believe we can do a lot to mitigate them and still get the benefits of transformative AI, but only if we try, and to try, we have to believe that we should. I’m not surprised that others are skeptical, as I spent many years in that state myself, but after even more years of consideration and reflection, I once again feel compelled to act. Contrary to the popular narrative about effective altruists working in AI, my interest in mitigating the potential risks isn’t rooted in specific predictions about the far future, but rather simple concern about the next few decades, when I and the people I care about are still alive to care about what happens. I don’t walk around day to day feeling like we’re doomed to apocalypse… and yet the reasons for concern make sense to me, especially the fact that the situation may develop extremely quickly.
Practical messiness
All models are wrong, some are useful.— George Box
At a more basic level, there are good reasons to be meta-epistemically humble. We should doubt empirical conclusions, due to data tampering, motivated reasoning, statistical flukes, and more. I’m a fallibilist, seeing science as continually improving the quality of our hypotheses, without ever really confirming anything. Nonetheless, I believe that it’s better to act on the information we have than to act like we know nothing at all. To do that means creating models that include empirical conclusions, but staying thoughtful about uncertainty and quick to update to new information.
In order to take action in our chosen focus areas, we also have to work with other groups who share some, but inevitably not all, of our beliefs. While the program officers at Open Philanthropy that I’ve gotten to know tend to be on the humble, curious side and overlap with our personal values, they’ve also made grants over the years to folks who are a less perfect match. I think that’s significantly the nature of philanthropy — you have to make hard calls around supporting people who share some of your values, but not all. Sometimes you know you’re making a hard call, and sometimes you find out retroactively because new information comes to light or a group you supported in the past moves in a more radical direction over time.

Moral uncertainty — what is the good?
In working to answer the question of how to do the most good, you often face trade-offs, particularly around how to apply resources like capital to solve a problem. For example, if you’re interested in helping with child mortality, you might look at the relative impact of donating to hospitals vs. donating to help volunteers reach people at home.
Something akin to utilitarianism is how people often approach this type of choice. In this case, we’d ask something like: how many more children will reach the age of 5 per $100,000 of donations? That’s not really an EA thing per se — most people, and certainly institutions, will naturally use utilitarianism some of the time when faced with this kind of question.
Some philanthropists and institutions will continue this same logic at higher levels of abstraction — what is the best, most cost effective way to help children generally? To intervene in extreme poverty? To attack the highest level causes of the problems?
Effective altruists take things a bit further by focusing on strategic cause selection. Well-established focus areas like education, climate change and global health & development are hugely important and a ton of resources are rightfully being leveraged towards those ends, but people tend not to ask whether those are even the right focus areas. What should be done with the next dollar on the margin? Out of everything, where can it be put to the best use? Both within existing areas, and across new areas that could be built up?
But utilitarianism has problems too — the real world involves complex situations. You don’t ever have all the information, especially about the consequences of your choices. This is obviously the case a priori, but it’s frequently still true after the choice is made as well; second/third/etc.-order effects can end up mattering more than the direct consequences and you won’t be able to measure them all. Many people may be pretty bad at evaluating what’s best even when they have good information — do we really want everyone walking around judging for themselves? FTX shows us the consequence of taking that idea all the way.
If you’re maximizing X, you’re asking for trouble by default. You risk breaking/downplaying/shortchanging lots of things that aren’t X, which may be important in ways you’re not seeing. Maximizing X conceptually means putting everything else aside for X — a terrible idea unless you’re really sure you have the right X. — Holden Karnofsky
Even aside from that, if you keep riding the utilitarianism train, you get to some counterintuitive places, like the repugnant conclusion⁵ and (strong) longtermism. Some effective altruists bite all of these bullets, but there’s a wide spectrum of beliefs within the community.
As with many things, I’m just really unsure myself. I believe that utilitarianism can be helpful and good for making many small and large decisions, without committing to thinking it’s good at the extreme, if for no other reason than because uncertainty about choices seems to continue growing for practical reasons as you follow those paths.
So there are many situations in which utilitarianism guides my thinking, especially as a philanthropist, but uncertainty still leaves me with many situations where it doesn’t have much to offer. In practice, I find that I live my day to day deferring to side constraints using something more like virtue ethics. Similarly, I abide by the law, rather than decide on a case by case basis whether breaking the law would lead to a better outcome. Utilitarianism offers an intellectual North Star, but deontological duties necessarily shape how we walk the path.

How to measure the good?
All of that framework uncertainty comes before you even get to the question of what you value — what is utility? Is it happiness, longevity/health, economic empowerment, equity, etc.? Again, different effective altruists will give you wildly different answers to this question, but for me I’m comfortable saying that there’s no single answer, not one thing to maximize. In practice, we end up with a shifting blend of priorities, and relative ratios that are context and opportunity dependent. We try to resist scope insensitivity, but nonetheless do encounter it as part of resource decisions — for example, should we help millions of humans, or hundreds of billions of animals? When in doubt, we diversify, but these remain extraordinarily difficult judgment calls, and I think we’re far from having all the right answers.
When EAs have too much confidence
Not all EAs have this epistemic humility. Sam Bankman-Fried, in his own words, was a “fairly pure Benthamite utilitarian” — among other things, this meant he was dogmatically driven by positive expected value (EV) bets, happy to take any risk with a 49% chance of failure, no matter how high the stakes, nor whose stakes they were. He literally said he was hypothetically willing to wager the entire world in such a gamble, because perhaps infinite such risks would lead to infinite happiness.⁶ The crypto environment let him put this philosophy into practice with increasingly enormous sums of money, and he kept doubling down until he lost it all.⁷ Then, he started gambling with customer deposits to try to get back above 0.
In doing so, he combined over-confidence with self-interest and then later with desperation to protect his freedom and his reputation.
I think civil disobedience — deliberate breaking of laws in accord with the principle of utility — is acceptable when you’re exceptionally sure that your action will raise utility rather than lower it.
To be exceptionally sure, you’d need very good evidence and you’d probably want to limit it to cases where you personally aren’t the beneficiary of the law-breaking, in order to prevent your brain from thinking up spurious moral arguments for breaking laws whenever it’s in your self-interest to do so. — Scott Alexander, The Consequentalism FAQ
SBF did not seem to be honoring this heuristic to avoid bias, especially when he decided to borrow customer deposits after going in the red — there was a clear, massive benefit to himself that needed to be achieved before any value could be earned that might benefit others. I don’t want to live in a world where individuals gamble with other people’s livelihoods when they think they’ve got good enough odds,⁸ much less the entire world. I generally don’t want to live in a world where individuals decide on their own which laws are valid at all (though I have to temper that with the recognition that many important social changes throughout history were only possible because some individuals did exactly that).
There is also an adjacent community, rationalists, that has in part influenced the way I approach issues, like using Scout Mindset. As the current community stands, I feel some distance due to the fact that they use rationality to arrive at, in my humble opinion, some much too confident opinions, even as they admirably calibrate and hedge other ones. As an example of the former, the AI risk folks who believe in near 100% probability of doom, like Eliezer Yudkowsky, ~all come from this community. They have at times also used their confidence to emphasize rules of discourse, like high decoupling, that I feel they take too far, losing out on the benefits of historical experience and collective intuitions. I know that they remain ever open to new arguments and evidence, even on meta levels, so I mostly expect them to nuance these over time, but I worry deeply that the practices systematically bias who stays in their communities — because objectors and more reasonable voices opt out — in a way that could create ideological lock-in.
Works in progress
Being in scout mindset means wanting your ‘map’ — your perception of yourself and the world — to be as accurate as possible.— Julia Galef
Following the collapse of FTX, and to some extent during the fallout from the OpenAI CEO drama,⁹ there have been calls for people interested in effective altruism to do some deep reflection, update on new evidence, and iterate on their principles. It’s hard not to react by thinking, “uh yea, that’s literally what they’ve been doing the whole time?” The type of deference and intellectual humility I describe above isn’t new thinking that came out post-SBF, but it was nonetheless not the way he thought about doing the most good.
There is, however, an important kind of meta update here. Even if parts of the community preach against overconfidence and maximization, others take the ideas extremely literally. As they act on their literal interpretations, others inside the community will see those examples and start to emulate them, spreading the problem (or possibly become alienated and leave the community, to its detriment).
SBF shows us how that can go poorly on a massive scale. Many individuals who self-identify as EAs are also familiar with how it can go poorly on a personal scale — they’re known for burning out from trying to, well, do too much good. There are ways to internalize this as simply irrational — i.e. you want to maximize your lifetime good, you have to run at a marathon pace — but it’s also about our limits of judgment. As an intellectual exercise, it’s useful to seek the answers to how to do the most good, and as a practical exercise, I believe in acting on that knowledge. In the abstract, I want to do the most good possible with my time and resources, but in practice I find the mindset helpful for this to be around more good and doing good better, both due to uncertainty about the right thing to do and humility about what I can achieve.
For now, I am encouraged by possibility and concerned by peril. But both sentiments spring from a recognition that effective altruism’s questions are important. Its answers may never be final, but the journey of seeking them can help us build a wiser, more effective practice of compassion.
I encourage the EA community and EAs¹⁰ to internalize and act on the lessons and fear the perils of maximization. The community has been around long enough to be able to learn from the journeys of more long-tenured EAs and now they have a tragedy of epic proportions to use as a cautionary tale. More than anything, we have a community built around learning and evolving, that strives to grow ever better. We’ve been trying our best to learn as much as we can, and we’ve never known more about what we don’t know.
• • •
¹ Like others I talk to all the time, I assumed their lives were generally getting better over time, instead of the prevailing reality that cost minimization erodes welfare, systematically making things worse over time.
² i.e. that the animals we raise for consumption are not capable of meaningful suffering
³ This is often the case with discovery, and I agree with these same critics that forgoing these benefits is itself a kind of harm, a “sin of omission”.
⁴ I would even say I started off as somewhat of an AI “accelerationist” in the early 2010s as an investor in Vicarious. (Vicarious has since been acquired.)
⁵ The repugnant conclusion is a philosophical thought experiment that suggests, via a step by step transition, that a world with a large population of people leading lives barely worth living could be considered better than a world with a smaller population of people leading deeply fulfilling lives.
⁶ This is “station 3: galaxy-brain longtermism” as Sigal Samuel describes it: “the view that we should take big risks to make the long-term future utopian”.
⁷ For many observers, all of this was quite predictable and you can find long Twitter exchanges from 2021/2022 with people trying to argue him out of it.
⁸ And empirically, SBF doesn’t seem to have been particularly adept at evaluating odds.
⁹ … and to a large extent just all the time … n.b. I’m choosing not to actually address the OpenAI cycle in this document because the most recent evidence suggests EA doesn’t have much to do with what happened, even though people assumed that at the beginning.
¹⁰ And EA-Adjacents too!