Чаще всего deadlock описывают примерно следующим образом:
Процесс 1 блокирует ресурс А.
Процесс 2 блокирует ресурс Б.
Процесс 1 пытается получить доступ к ресурсу Б.
Процесс 2 пытается получить доступ к ресурсу А.
В итоге один из процессов должен быть прерван, чтобы другой мог продолжить выполнение.
Но это простейший вариант взаимной блокировки, в реальности приходится сталкиваться с более сложными случаями. В этой статье мы расскажем с какими взаимными блокировками в MS SQL нам приходилось встречаться и как мы с ними боремся.

Немного теории
При использовании таких сложных СУБД как MS SQL надо понимать, как и какие ресурсы блокируют типичные запросы и как на это влияют уровни изоляции транзакции.
Для тех, кто плохо в этом разбирается рекомендуем прочитать следующие статьи:
Выбор уровня изоляции транзакции
При использовании транзакций с уровнем изоляции serializable могут происходить любые взаимные блокировки. При использовании уровня изоляции repeatable read некоторые из описанных ниже взаимных блокировок не могут произойти. У транзакций с уровнем изоляции read committed могут возникнуть только простейшие взаимные блокировки. Транзакция с уровнем изоляции read uncommitted практически не влияет на скорость работы других транзакций и в ней не могут возникнуть взаимные блокировки из-за чтения, так как она не накладывает shared блокировки (правда могут быть взаимные блокировки с транзакциями изменяющими схему БД).
Уровни изоляции транзакции сильно влияют на скорость работы системы и без учета взаимных блокировок, поэтому очень важно правильно выбирать уровень изоляции в зависимости от задачи, которую выполняет транзакция. Вот примерные советы:
- Если транзакция изменяет данные в БД и при этом проверяет, чтобы эти данные не противоречили уже существующим записям в БД, то для нее скорее всего нужен уровень изоляции serializable. Но если вставка новых записей в параллельных транзакциях никак не может повлиять на результат текущей транзакции то можно использовать уровень изоляции repeatable read.
- Для чтения данных обычно достаточно использовать уровень изоляции по умолчанию (read committed) без какой либо транзакции. Однако при чтении агрегатов, части которых могут быть изменены во время чтения, может понадобится использовать транзакцию с уровнем изоляции repeatable read или даже serializable, иначе можно получить из базы агрегат в некорректном состоянии, в котором он может быть только в процессе выполнения транзакции изменения.
- Если необходимо отображать real time статистику по постоянно изменяющимся данным, то зачастую лучше использовать уровень изоляции read uncommitted. В этом случае в статистике будет некоторое количество грязных данных (хотя вряд ли это будет заметно), но зато построение отчетов практически не будет влиять на скорость работы системы.
Retry on deadlock
В достаточно сложной системе, насчитывающей десятки разнообразных типов бизнес транзакций, вряд ли получится спроектировать все транзакции таким образом, чтобы deadlock не мог возникнуть ни при каких условиях. Не стоит тратить время на предотвращение взаимных блокировок, вероятность возникновения которых крайне мала. Но, чтобы не портить user experience, в случае, когда операция прерывается из-за взаимной блокировки, ее нужно повторить. Для того, чтобы операцию можно было безопасно повторить, она не должна изменять входные данные и должна быть обернута в одну транзакцию (либо вместо всей операции, надо оборачивать в свой RetryOnDeadlock каждую SQL транзакцию в операции).
Вот пример функции RetryOnDeadlock на C#:
private const int DefaultRetryCount = 6;
private const int DeadlockErrorNumber = 1205;
private const int LockingErrorNumber = 1222;
private const int UpdateConflictErrorNumber = 3960;
private void RetryOnDeadlock(
Action<DataContext> action,
int retryCount = DefaultRetryCount)
{
if (action == null)
throw new ArgumentNullException("action");
var attemptNumber = 1;
while (true)
{
var dataContext = CreateDataContext();
try
{
action(dataContext);
break;
}
catch (SqlException exception)
{
if(!exception.Errors.Cast<SqlError>().Any(error =>
(error.Number == DeadlockErrorNumber) ||
(error.Number == LockingErrorNumber) ||
(error.Number == UpdateConflictErrorNumber)))
{
throw;
}
else if (attemptNumber == retryCount + 1)
{
throw;
}
}
finally
{
dataContext.Dispose();
}
attemptNumber++;
}
}
Важно понимать, что функция RetryOnDeadlock всего лишь улучшает user experience при изредка возникающих взаимных блокировках. Если они возникают очень часто, она лишь ухудшит ситуацию, в разы увеличив нагрузку на систему.
Борьба с простейшими взаимными блокировками
Если взаимная блокировка возникает из-за того, что два процесса обращаются к одним и тем же ресурсам но в разном порядке (как это описано в начале статьи), то достаточно поменять порядок блокировки ресурсов. В принципе, если в разных операциях блокируется определенный набор ресурсов, блокироваться первым всегда должен один и тот же ресурс, если это возможно. Этот совет применим не только к реляционным БД, но и вообще к любым системам, в которых возникают взаимные блокировки.
В применении к MS SQL этот совет, немного упрощая, можно выразить следующим образом: в разных транзакциях, изменяющих несколько таблиц, первой должна изменяться одна и та же таблица.
Shared->Exclusive lock escalation
Наиболее часто встречаемая взаимная блокировка в нашей практике возникает в транзакциях с уровнем изоляции Repeatable read или Serializable следующим образом:
- Транзакция 1 читает запись (накладывается S-блокировка).
- Транзакция 2 читает эту же запись (накладывается вторая S-блокировка).
- Транзакция 1 пытается изменить запись и ждет, когда транзакция 2 закончится и отпустит свою S-блокировку.
- Транзакция 2 пытается изменить эту же запись и ждет, когда транзакция 1 закончится и отпустит свою S-блокировку
Для возникновения подобной взаимной блокировки достаточно одного ресурса, за который борются две однотипные транзакции. Борьба может вестись не только за одну запись но и за любой другой ресурс. Например, если две Serializable транзакции считают количество записей с определенным значением, а потом вставляют запись с таким же значением, то ресурсом, освобождение которого они ждут, будет ключ в индексе.
Чтобы избежать такой взаимной блокировки, необходимо, чтобы из двух транзакций, собирающихся изменить запись, прочитать ее могла только одна. Специально для этого была введена update блокировка. Ее можно наложить следующим образом:
SELECT * FROM MyTable WITH (UPDLOCK) WHERE Id = @Id
Если вы используете ORM и не можете управлять тем, как запрашивается сущность из БД, то вам придется выполнить отдельный запрос на чистом SQL для блокировки записи прежде чем запрашивать ее из БД. Важно, что накладывающий update блокировку запрос должен быть первым запросом, обращающимся к этой записи в данной транзакции, иначе будет возникать все та же взаимная блокировка, но при попытке наложить update блокировку, а не при изменении записи.
Накладывая update блокировку мы заставляем все транзакции, обращающиеся к одному ресурсу, выполняться по очереди, но обычно транзакции изменяющие один и тот же ресурс в принципе нельзя делать параллельно, так что это нормально.
Такая взаимная блокировка может возникнуть в любой транзакции, которая проверяет данные перед их изменением, но для редко изменяющихся сущностей, можно использовать RetryOnDeadlock. Подход с предварительной update блокировкой достаточно использовать только для сущностей, которые часто меняются разными процессами параллельно.
Пример
Пользователи заказывают призы за баллы. Количество призов каждого вида ограниченно. Система не должна позволить заказать больше призов, чем есть в наличии. Из-за особенностей промоакции периодически происходят набеги пользователей, желающих заказать один и тот же приз. Если использовать RetryOnDeadlock в данной ситуации, то во время набега пользователей заказ приза в большинстве случаев будет падать по web таймауту.
Если мы храним количество оставшихся призов в записи о виде приза, то транзакция заказа приза должна выглядеть следующим образом:
- Получаем запись о виде приза, накладывая update блокировку.
- Проверяем количество оставшихся призов. Если оно равно 0, завершаем транзакцию и возвращаем соответствующий ответ пользователю.
- Если призы еще есть, уменьшаем количество оставшихся призов на 1.
- Добавляем запись о заказанном призе.
Таким образом мы позволяем в один момент заказывать один и тот же вид приза только одному пользователю. Все запросы пользователей на заказ одного и того же вида приза выстраиваются в очередь, но такой подход дает более хороший user experience, чем RetryOnDeadlock или вывод ошибки потребителю при возникновении взаимной блокировки.
Если не хранить количество оставшихся призов, а высчитывать его на основании количества заказанных призов, то update блокировку можно накладывать при вычислении количества заказанных призов. Выглядеть это будет примерно следующим образом:
SELECT count(*) FROM OrderedPrizes WITH (UPDLOCK) WHERE PrizeId = @PrizeId
Большинство взаимных блокировок, описанных далее, происходят похожим образом — мы пытаемся изменить данные после того как наложили на них Shared блокировку. Но в каждом из этих случаев есть свои нюансы.
Выборки по неиндексируемым полям
Если мы в serializable транзакции ищем запись по полю не входящему ни в один индекс, то shared блокировка будет наложена на всю таблицу. По другому нельзя убедиться, что ни одна другая транзакция не сможет вставить запись с таким же значением до завершения текущей транзакции. В итоге любая транзакция делающая выборку по этому полю, а потом изменяющая эту таблицу, будет взаимно блокироваться с любой подобной же транзакцией.
Если же добавить индекс по этому полю (или индекс по нескольким полям, первым из которых является поле, по которому мы ищем), то блокироваться будет ключ в этом индексе. Так что в serializable транзакциях еще более важно задумываться есть ли индекс по колонкам, по которым вы ищете записи.
Есть еще один нюанс, о котором важно помнить: если индекс уникален, то блокировка накладывается только на запрашиваемый ключ, а если неуникален, то также блокируются cледующее за этим ключом значение. Две транзакции, запрашивающие разные записи по неуникальному индексу, а потом изменяющие их, могут взаимно блокироваться, если запрашиваются соседние значения ключей. Обычно это редкая ситуация и достаточно использовать RetryOnDeadlock, чтобы избежать проблем, но в некоторых случаях может потребоваться накладывать update блокировку при вытаскивании записей по неуникальному ключу.
Проверка на наличие перед вставкой
Пример
Нам необходимо проверить, есть ли в БД пользователь с таким Id в Facebook, перед тем как его добавлять. Так как мы работаем с одной строчкой в БД, создается ощущение, что будет блокироваться только она и вероятность взаимной блокировки невелика. Однако если в транзакции с уровнем изоляции Serializable попытаться выбрать несуществующее значение (и эта колонка входит в индекс), то будет наложена shared блокировка на все ключи между двумя ближайшими значениям, которые есть в таблице. Например, если в базе есть Id 15 и Id 1025, и нет ни одного значения между ними, то при выполнении SELECT * FROM Users WHERE FacebookId = 500 будет наложена Shared блокировка на ключи с 15 до 1025. Если до вставки другая транзакция проверит есть ли пользователь с FacebookId = 600 и попытается его вставить, то произойдёт взаимная блокировка. Если в БД уже много потребителей, у которых заполнен FacebookId, то вероятность взаимной блокировки будет невелика и нам достаточно использовать RetryOnDeadlock. Но если выполнять множество таких транзакций на почти пустой базе, то взаимные блокировки будут возникать достаточно часто, чтобы это сильно сказалось на производительности.
У нас эта проблема возникла при параллельном импорте потребителей от новых клиентов (для каждого клиента мы создаем новую пустую БД). Так как нас на данный момент устраивает скорость однопоточного импорта, мы просто отключили параллелизм. Но в принципе проблема решается также как и в выше описанном примере, надо использовать update блокировку:
SELECT * FROM Users WITH(UPDLOCK) WHERE FacebookId = 500
В этом случае при многопоточном импорте в пустую базу по началу потоки будут простаивать, ожидая пока освободится блокировка, но по мере заполнения базы степень параллелизма будет возрастать. Хотя если импортируемые данные упорядочены по FacebookId, то параллельно импортировать их не получится. При импорте в пустую базу такого упорядочивания стоит избегать (либо не проверять наличие пользователей в БД по FacebookId при первом импорте).
Взаимные блокировки на сложных агрегатах
Если у вас в системе есть сложный агрегат, данные которого хранятся в нескольких таблицах, и есть множество транзакций изменяющих разные части этого агрегата параллельно, то необходимо выстроить все эти транзакции таким образом, чтобы в них не возникали взаимные блокировки.
Пример
В БД хранится персональные данные потребителя, его идентификаторы в соц сетях, заказы в интернет магазине, записи об отправленных ему письмах.
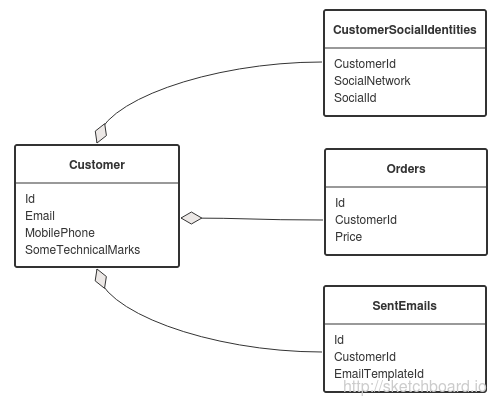
Транзакции, добавляющие идентификатор в соц сети, отправляющие письма и регистриующие покупки, также могут изменять технические поля в основной записи о потребителе. В любой из этих транзакций присутствует Id потребителя.
Для избежания взаимных блокировок нужно начинать любую транзакцию со следующего запроса:
SELECT * FROM Customers WITH (UPDLOCK) WHERE Id = @Id
В этом случае в один момент только одна транзакция сможет изменять данные, относящиеся к конкретному потребителю и взаимные блокировки не будут возникать в независимости от того насколько сложен агрегат потребителя.
Можно попробовать изменить схему хранения данных так, чтобы транзакции, отправляющие письма и регистрирующие покупки не меняли технические пометки в потребителе. Тогда информацию о заказах и отправленных письмах можно будет изменять параллельно с изменением потребителя. В этом случае мы фактически выносим эти данные за рамки агрегата «потребитель».
Если обобщать, советы по работе с агрегатами можно описать следующим образом:
- надо стремится к тому, чтобы любая транзакция в системе не изменяла более одного агрегата
- в любой транзакции, изменяющей агрегат, первый запрос, обращающийся к данным агрегата, должен накладывать exclusive или update блокировку на корень агрегата
- для увеличения степени параллелизма системы надо делать агрегаты настолько маленькими насколько это возможно
Эти советы, конечно, не являются панацеей от взаимных блокировок, но могут сильно облегчить вам жизнь.
Взаимные блокировки на последовательно идущих записях
Подобные взаимные блокировки возникают при очень специфичных условиях, но пару раз мы с ними все-таки сталкивались, так что о них тоже стоит рассказать.
Пример
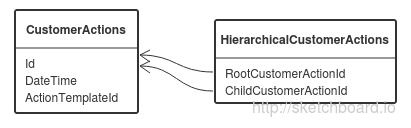
При отправке письма из DirectCRM в email-шлюз потребителю выдается действие о факте отправки (одна запись в БД). Id действия это обычный identity, увеличивающийся на один для каждой следующей записи. При успешной отправке письма в почтовый сервер, email-шлюз сообщает об этом DirectCRM, и CRM выдает действие об успешной отправке письма, которое ссылается на действие о факте отправки (ссылка хранится в таблице HierarchicalCustomerActions). Для того, чтобы операция обработки сообщения из email-шлюза была идемпотентной, мы проверяем не выдалось ли действие об успешной отправке до этого (в serializable транзакции). При такой проверке накладывается shared блокировка на ключ в индексе по RootCustomerActionId, соответствующий факту отправки письма. Но действие об отправке — первое ссылающиеся на факт отправки и в момент его выдачи в таблице HierarchicalCustomerActions нет ни одной записи с таким RootCustomerActionId. Поэтому shared блокировка будет наложена на все ключи между двумя существующими. Так как Id действия — identity, то очень часто проверяемый RootCustomerActionId оказывается больше любого из тех, которые уже есть в таблице и блокировка накладывается на все ключи больше или равные максимальному значению RootCustomerActionId в таблице. В email-шлюзе отправка сообщения происходит в несколько потоков и в итоге очень часто возникает следующая ситуация:
- DirectCRM добавляет действия о факте отправки с Id N, N+1, N+2 и т. д.
- Email-шлюз параллельно обрабатывает отправку всех этих писем.
- В момент выдачи действий об отправке, максимальное значение RootCustomerActionId равняется N-1.
- При проверке нет ли записи об успешной отправке письма N, N+1, N+2 и т.д., накладывается shared блокировка на записи с RootCustomerActionId больше или равные N-1.
- Каждая из транзакций пытается вставить свою запись об отправке и ждет когда другая транзакция освободит shared блокировку.
- В итоге из всех параллельно выполняющихся транзакций выполнится только одна, а остальные будут откачены.
Если накладывать update блокировку при запросе к HierarchicalCustomerActions, то взаимных блокировок не будет, но и параллельной обработки тоже — все транзакции будут ждать пока закончится транзакция наложившая update блокировку.
Есть следующие решения этой проблемы:
- Отказаться от identity и генерить Id действия так, чтобы новый Id в большинстве случаев оказывался между двумя существующими. Тогда вероятность взаимной блокировки будет невелика.
- При выдачи действия о факте отправки также вставлять запись в HierarchicalCustomerActions (у этой записи RootCustomerActionId будет равен CustomerActionId). Тогда при запросе записей с RootCustomerActionId = N будет накладываться shared блокировка на значения N и N+1, так как записи с такими значениями уже есть. Чтобы не возникали взаимные блокировки при параллельной вставке действий об успешной отправке, ссылающихся на действия о факте отправки с Id N и с Id N+1, надо накладывать update блокировку при запросе к HierarchicalCustomerActions. В итоге при параллельной вставке нескольких записей происходит следующее:
-
Транзакция 1 запрашивает записи с RootCustomerActionId = N. При этом накладывает update блокировка на значения ключа N и N+1.
-
Транзакция 2 запрашивает записи с RootCustomerActionId = N+1. При этом он пытается наложить update блокировку на значения N+1 и N+2, поэтому ждет завершения транзакции 1.
-
Транзакция 3 запрашивает записи с RootCustomerActionId = N+2. При этом накладывает update блокировка на значения ключа N+2 и N+3. Теперь транзакция 2 должна также дождаться завершения транзакции 3.
-
Транзакции 1 и 3 отрабатывают параллельно.
-
Выполняется транзакция 2.